1. RAG란?
RAG(Retrieval-Augmented Generation)는 정보 검색과 텍스트 생성을 결합한 자연어 처리 기술이다.
RAG의 핵심 개념
- RAG는 문서 검색기(retriever)와 텍스트 생성기(generator)를 유기적으로 결합한다.
- 사용자의 질문이 입력되면 먼저 외부 데이터베이스에서 관련 정보를 검색한다.
- 검색된 정보를 바탕으로 대규모 언어 모델(LLM)이 답변을 생성한다.
RAG의 장점
- 정확성 향상: 외부 지식을 활용하여 LLM의 "할루시네이션(환각)" 문제를 크게 줄일 수 있다.
- 최신 정보 반영: 실시간으로 업데이트되는 외부 데이터베이스를 활용하여 항상 최신 정보를 제공할 수 있다.
- 도메인 적응성: 특정 분야의 전문 지식을 쉽게 통합할 수 있어 다양한 도메인에 적용이 용이하다.
RAG의 활용 사례
- 고객 서비스: 제품 매뉴얼, FAQ 등을 검색하여 정확하고 상세한 고객 응대가 가능히다.
- 의료 분야: 최신 의학 논문, 임상 가이드라인 등을 활용하여 의사 결정을 지원하다.
- 제조업: 설비 문제 해결을 위해 관련 규정, 과거 사례, 유지보수 기록 등을 검색하여 신속한 문제 해결을 돕는다.
RAG는 LLM의 강력한 언어 이해 및 생성 능력과 외부 지식 활용을 결합함으로써, 보다 정확하고 풍부한 정보를 제공할 수 있는 혁신적인 기술이다.
이처럼 오늘날에 가장 주목 받는 기술인 RAG에 대해 이 블로그에서는 완전 초보용으로 작성할 예정이다.
사실 필자도 절반도 이해 못한 초보라 그럼
2. RAG가 중요한 이유
LLM 모델의 가장 큰 단점이라고 볼 수 있는 환각 문제를 대처할 수 있다.
환각이란 LLM 모델이 사실이 아닌 답변을 사실이라고 답변 하는 경우를 뜻한다.
RAG를 사용하면 주어진 문서 내에서 사용자 쿼리에 가장 유사한 값을 찾아와 해당 값을 근거 삼아 답변을 제공 하므로 환각이 일어난 확률이 낮다.
3. RAG의 과정
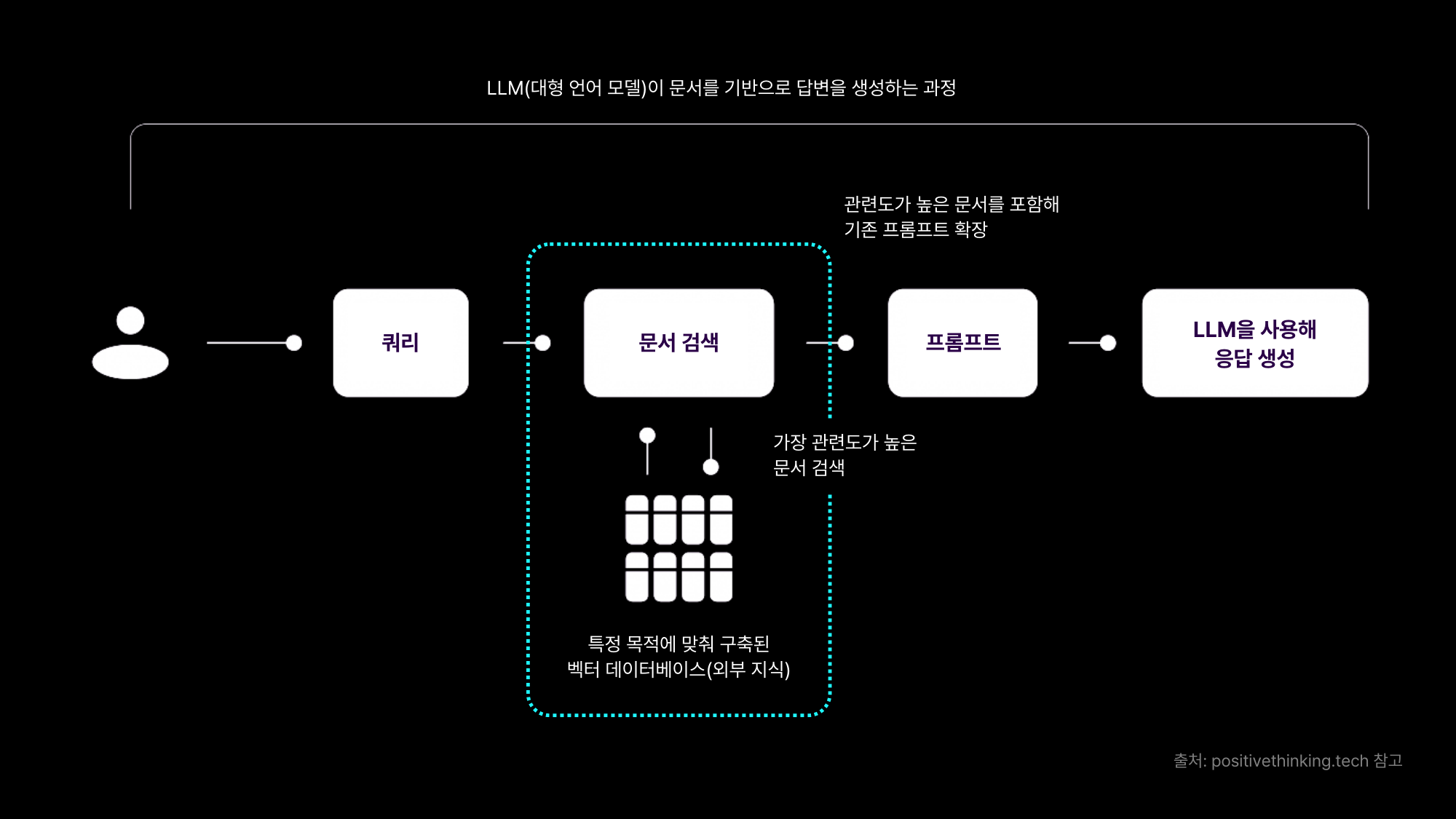
RAG는 기본적으로 위의 사진과 같은 형태를 띈다.
물론 복잡하게 간다면 더욱 복잡해지지만 가장 기본적인 알고리즘은 위의 사진이다.
1) 사용자 쿼리 입력
2) 미리 저장되어 있는 벡터 스토어 내에서 사용자 쿼리와 유사한 값 찾기
3) 문서 내에서 찾아온 부분을 LLM에게 전달
4) LLM을 이용해 답변 생성
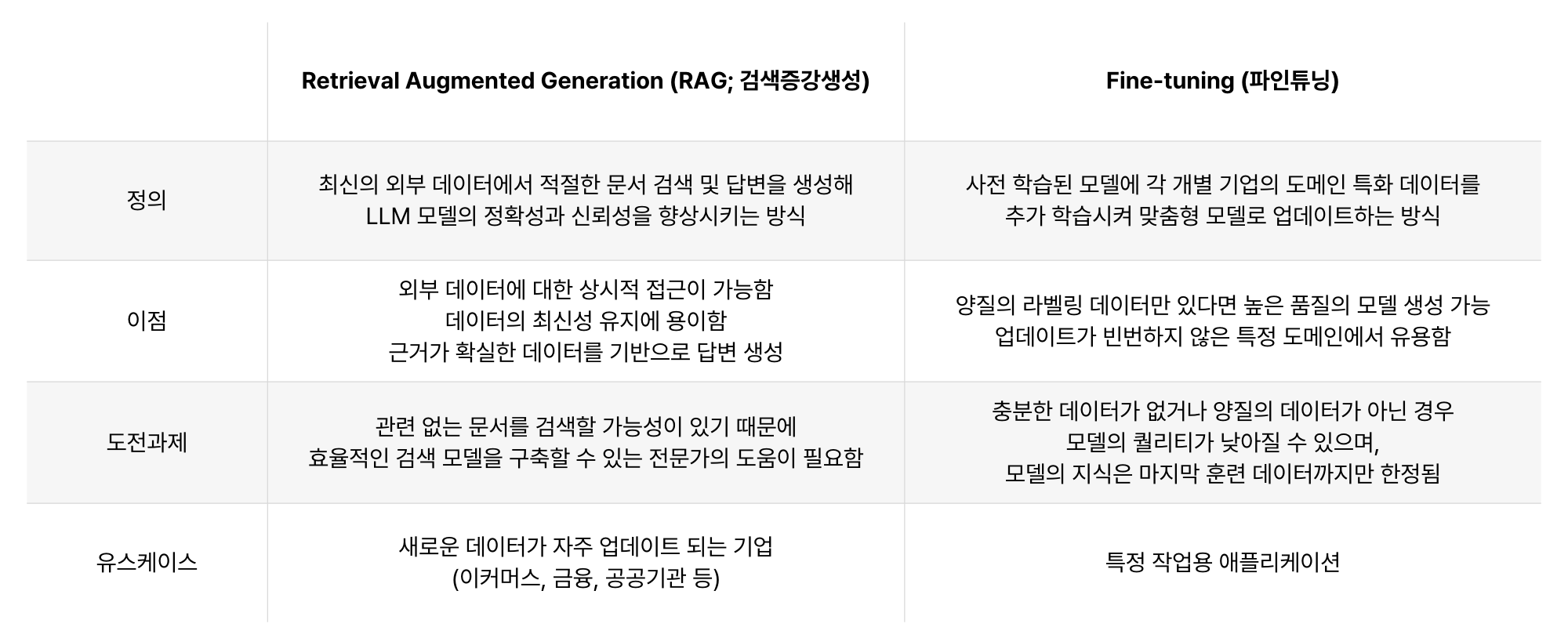
4. RAG VS Fine-Tuning
현재 RAG는 기업들이 가장 많이 찾는 기술이다.
그렇다면 기업에선 2 가지의 고민에 빠진다.
RAG냐 파인 튜닝이냐.
여기서 부터 하는 모든 말은 필자의 개인 의견 및 뇌피셜이므로 100% 신뢰하지 말것
기본적으로 둘의 접근 방식 자체가 다르다.
RAG는 문서를 주어주면 저장하여 원하는 값을 검색하여 나오는 결과값을 토대로 답변을 생성하는 반면, 파인 튜닝은 미리 QNA 형식의 답변 데이터 셋을 LLM 모델에게 학습 시켜 맞춤형 모델로 업데이트 하는 방식이다.
그렇다면 파인 튜닝이 더 좋은거 아니냐?
나도 잘 모른다
꼭 그렇지만은 않다.
파인 튜닝은 비용적인 면에서 당연히 부담이 될 수 밖에 없다.
이건 필자의 경험담 이지만, 필자는 현재 M1 pro Macbook 16인치를 사용하고 있다.
이 노트북이 어느정도 이상의 성능을 내주고 있다는건 다들 좀 알고 있을거다.
하지만 정말 작은 데이터 셋으로 파인 튜닝을 시도한 결과 바로 메모리 부족으로 뻑나면서 컴터 강제 종료 당했다.
정말 작은 데이터 셋이지만, 파인 튜닝을 시작하자 사용하는 메모리가 몇 십 기가 단위로 기하 급수적으로 늘어나 버린다.
따라서, 어느정도 기업 규모가 있는 대기업 급의 회사, 정말 좋은 GPU 서버가 있는 회사가 아니라면 사실 엄두조차 내지 못하는 상황이다.
하지만 RAG는 다르다.
RAG는 사용하는 컴퓨터의 성능 부담이 굉장히 적은 편이다.
필자가 생각하는 RAG에서 가장 중요한건 "어떤 임베딩 모델을 쓰느냐" 이다.
현재 진행형으로 RAG 프로젝트를 진행중에 있지만, 검색 결과가 시원찮았다.
물론 돈 쓰고 API를 통해서 좋은 임베딩 모델과 LLM 모델을 쓴다면 나도 고수?가 되겠지만 현실은 돈 없은 백수이니 그냥 돈 안드는 무료 모델 (뒤에 나올 HuggingFace, LM STUDIO, Llama3) 등을 쓰다 보니 이정도 성능만 나와도 감지 덕지가 아닐까 싶긴 하다.
현재 필자가 갖고 있는 정말 작은 지식을 공유해서 더 많은 사람들이 RAG를 연구해서 많은 양의 데이터들이 쏟아진다면 필자도 구글링을 통해서 더 좋은 성능을 뽑을수 있지 않을까 기대하며 이 긴 글을 쓴다.
이제부터 작성하는 글들은 RAG 시스템의 알고리즘 순서대로 작성할 것이다.
