안녕하세요! 데보션영 3기 5CEAN의 서희건입니다.
오늘은 제 프로젝트에 활용했던 RAG에 대해 쉽게 설명해보려고 합니다!
정말 많이 듣는 개념이지만, 전공 분야가 아니면 찾아보기도 귀찮고 공식문서는 더더욱 어려워서 읽기도 싫어지더라고요..ㅠㅠ
그런분들을 위해서..! 준비했습니다.
(FROMdk님의 "고등학생도 이해하는 Transformer "에서 영감을 받았습니다.)
RAG란?
RAG(Retrieval-Augmented Generation)는 대규모 언어 모델의 출력을 최적화하여 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스입니다.
쉽게 말해 자료를 정리해놓은 서랍장에서 필요한 자료를 찾아서 "자, 이거 같이 봐~" 하는것이지요.
RAG를 사용하는 이유는?
보통 우리가 LLM에 질문을 하게되면 엉뚱하게 대답할 때가 있습니다.
챗지피티에게 “세종대왕이 맥북 프로를 던진 사건에 대해서 써줘”라고 했더니, 갑자기 조선왕조실록 얘기를 하며 “조선시대 때 세종대왕이 한글을 만들다가 노하셔서 맥북 프로를 던졌다”는 말을 해주죠.

다음과 같은 이점을 가지고 있지요!!
- 할루시네이션 방지
- 최신 정보 반영 가능
- 사용자 신뢰 강화
RAG는 어떻게 작동하나요?
RAG를 사용하지 않는 경우 LLM은 사용자 입력을 받아 훈련한 정보 또는 이미 알고 있는 정보를 기반으로 응답을 생성합니다. RAG에는 사용자 입력을 활용 하여 먼저 새 데이터 소스에서 정보를 가져오는 정보 검색 구성 요소가 도입되었습니다.
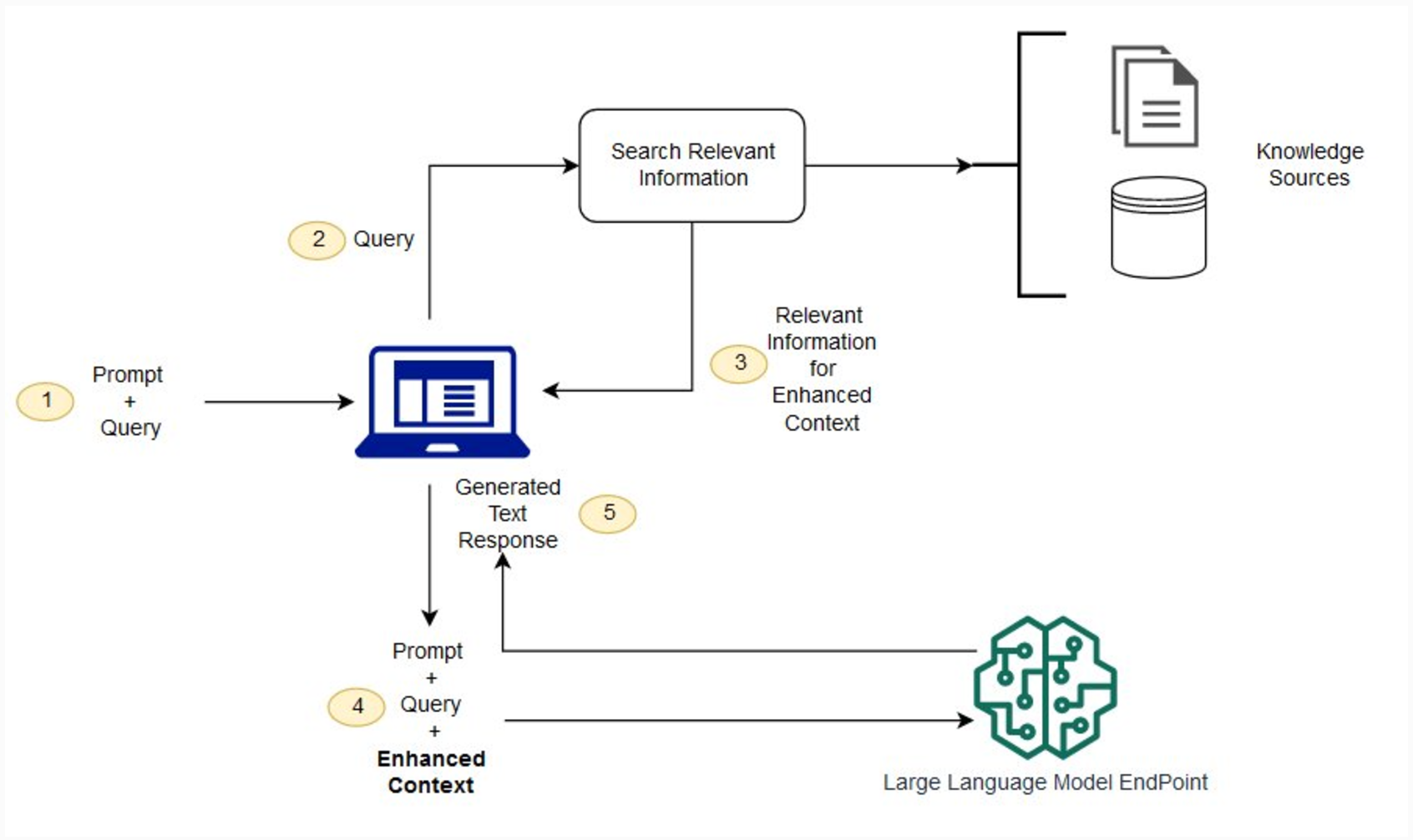
- LLM에 사용자 입력
- 불용어 처리, 변환을 통한 질의 전처리
- 사용자 요청에 맞는 정보를 DB에서 검색
- 상위 k개를 골라 LLM에 컨텍스트로 활용
- 생성 모델에 [질의]+[검색된컨텍스트]로 전달
모델은 컨텍스트를 참고하여 답변 생성. - 출력 생성
이게 정말 도움이 될까..?
꽤나 복잡한 과정이 추가되어 정말 도움이 되는지 궁금하신 분들을 위해서..!
"네 정말 도움됩니다."
밑은 이번 제 프로젝트에 활용한 결과입니다.
간단히 제 프로젝트를 설명해드리자면 "자소서 기반 면접예상질문생성AI"기능입니다.

각 모델별 자기소개서 해당 문장에 대한 출력결과를 나타낸것이고, 이를 실제 reference와 BERT유사도 검사를 통해 수치화 하였습니다/
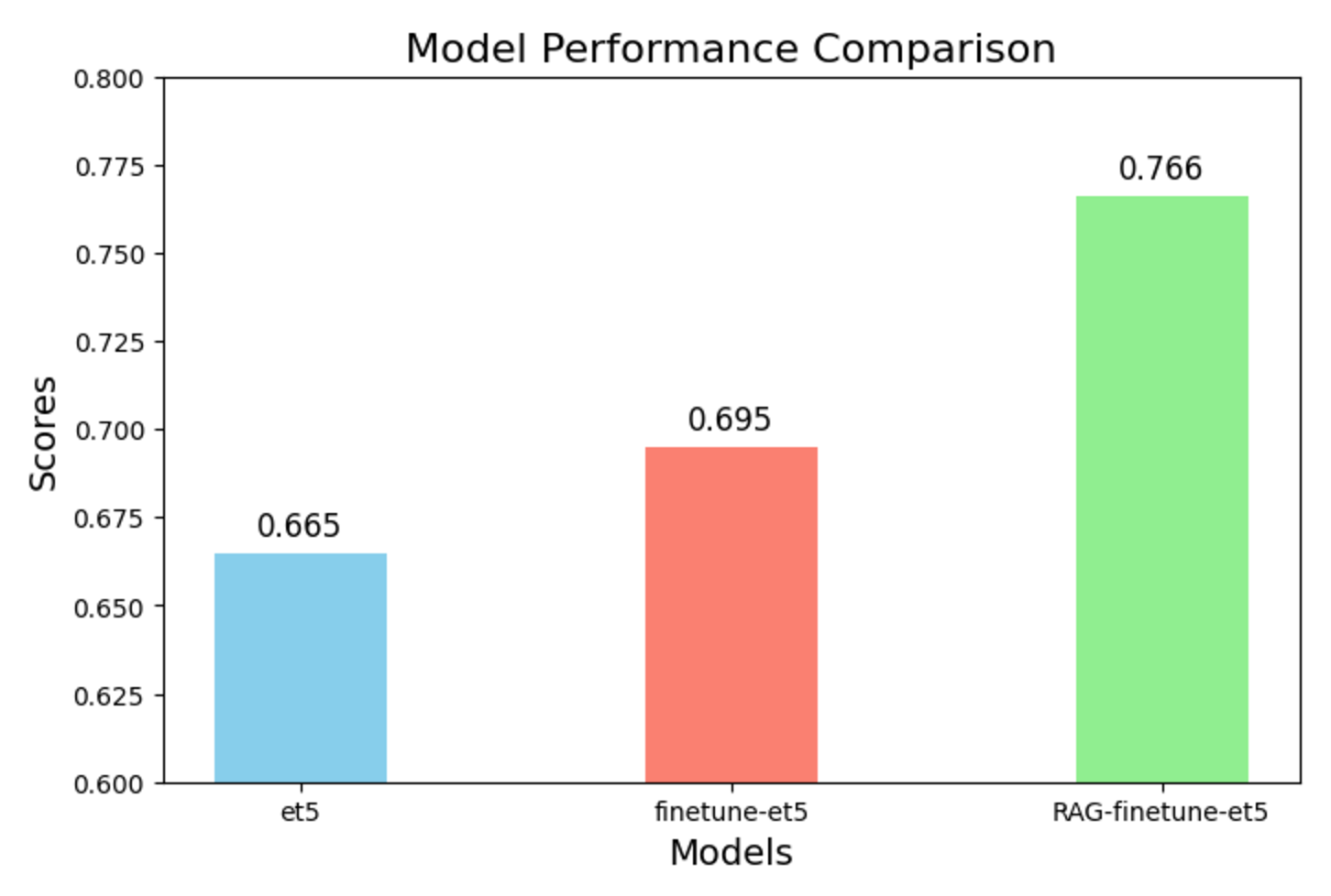
확실히 그래프로 보니 RAG가 아무것도 하지 않은 기존 모델보다 월등한 성능을 보여주는군요!!
마치며
이번 프로젝트를 통해 많이 알게된 인사이트중에 제일 대중적인것으로 가져왔습니다. 아시는 분은 지루하고 가볍다고 생각하실 수 있지만! 처음 보는분들께 소개드리고 싶었습니다.
이상 5cean 서희건이었습니다. :)
