VFNet(VarifocalNet) 논문 리뷰
- Abstract
- Introduction
- Motivation
- VarifocalNet
- Experiment
- VarifocalNet-X
[Abstract]
-
Dense Object Detector (one-stage)
수많은 ‘후보’ 들의 순위를 정확히 매기는 것이 성능 향상에 직결됨
기존 연구에서는 prediction score와 localization score를 결합시켜 후보의 순위를 매김
reliable ranking이 되기 때문에 detection 성능을 감소시킴?
-
IoU-Aware Classification Score 제안
-Presence confidence와 localization accuracy를 동시에 나타낼 수 있는 척도-IACS 예측을 위해 새로운 손실 함수 Varifocal loss를 제안
-9개의 점을 이용해 별 모양으로 Bounding box를 그리는 방법 제안
-
VFNet의 성능
Res2Net-101-DCN을 기반으로 한 single model의 COCO 데이터셋 single-scale AP 55.1 달성
-
Anchor box 기반 bbox 예측
중첩 bbox를 얻기 위해 미리 여러 개의 anchor box를 세팅해 두고, NMS를 이용해 중첩을 제거NMS (Non-Maximum Suppression)
confidence가 높은 제안들 중 다른 모든 제안과의 IoU가 임계값 이상인 것을 선택하는 방법
-
FCOS+ATSS 기반 구조
FCOS
anchor-free bbox 탐지 방법.
객체 중앙을 예측, 결과가 positive라면중심에서부터 객체 경계까지의 거리를 예측ATSS
bbox 내 객체의 positive/negative 여부를 나누는 알고리즘으로,
GT 박스 중심과 anchor box 중심(또는 point) 까지의 거리를 바탕으로 가장 가까운 k개의 후보를 골라서 GT와의 IoU가 가장 높은 후보를 positive로 선택하는 방법
[Introduction]
-
기존 모델의 bbox 탐지 방식
anchor를 이용해 bbox를 많이 만들고 NMS로 제거하는데, classification score(confidence)가 박스 제거 기준이 됨그러나 높은 confidence가 box localization의 정확도를 보장하는 것이 아니기 때문에 이를 보완하기 위해서 추가적으로 IoU를 계산하거나, 중심성 점수를 구해 이들을 곱한 것을 박스 제거 기준으로 사용하기도 함
이 방법은 보완책이 될 수 있지만 예측들이 모두 부정확할 경우 이들을 곱하는 것이 더 나쁜 결과를 가져올 수 있음
-
논문에서 제안하는 방식
localization score를 classification score에 병합시켜서 추가적인 계산이 필요 없도록 IACS 기반으로 예측하는 방식
→ 생성된 bbox에서 객체의 존재 여부와 localization 정확도를 연속적으로 나타낼 수 있음
-
Focal loss
Focal loss 등장 배경 : detection에서의 class imbalance 문제
(negative sample은 너무 많고 positive sample은 적다)쉽게 분류되는 negative sample의 가중치를 낮추고 positive sample의 가중치는 높이는 방법
-
Varifocal Loss
모델을 학습시킬 때 가중치를 비대칭적으로 주는 방법
negative sample의 가중치를 낮추고 positive sample의 가중치는 높여서 모델이 ‘좋은’ positive 샘플에 집중하게 함
-
Star-shaped bbox
9개의 샘플링 포인트를 사용해서 bbox를 deformable convolution으로 나타냄deformable conv : 커널을 이미지의 정위치에 곱하는 것이 아니라 커널의 각 픽셀이 offset 벡터만큼 이동한 위치에 곱해지는 방식. 이미지의 변형에 유연하게 대처할 수 있음
[Motivation]
-
FCOS
FPN 기반, (특성 맵 각 지점의 classification 점수 / 객체 경계까지 거리 / 중심성 점수)를 예측하는 head를 가지고 있음bbox의 순위를 매기는 데 classification 점수와 중심성 점수의 곱을 사용
FCOS+ATOS만 사용한 모델의 AP : 39.2 (훈련:COCO train2017, AP 검증:COCO val2017)
-
FCOS 개선 (IACS 측면)
bbox 제거 기준을 classification 점수에서 GT와의 IoU로 변경
→ 중심성 점수 없이도 AP 74.7 달성 (훈련:COCO train2017, AP 검증:COCO val2017)수많은 bbox 후보들 중에는 정확하게 localized된 것이 이미 존재하기 때문
모델이 고성능을 달성하기 위해서는 bbox 후보들 중 고품질의 탐지를 선택해야 함bbox를 생성하는 기준을 classification 점수가 아닌 GT와의 IoU로 대체하고 이 척도를 IACS라 명명함 (IoU-Aware Classification Score)
[VarifocalNet]
-
IACS
classification score 벡터의 스칼라 요소
(GT 레이블 위치의 값은 GT와의 IoU 점수, 다른 위치의 값은 0)ex: [ 0, 0, 0.64, 0 ]smoothing된 one-hot 벡터처럼 동작해서 클래스 분류와 bbox localization 점수를 동시에 챙길 수 있음
-
Varifocal Loss
focal Loss를 기반으로 만들어진 IACS를 위한 loss
positive sample의 가중치는 높이고 negative sample의 가중치는 낮춰서 학습 가능계수 p가 negative sample의 가중치를 감소시키는 역할을 함
(positive sample의 경우 계수 p가 없음)계수 q가 positive sample의 가중치를 증가시키는 역할을 함

-
VFNet 구조
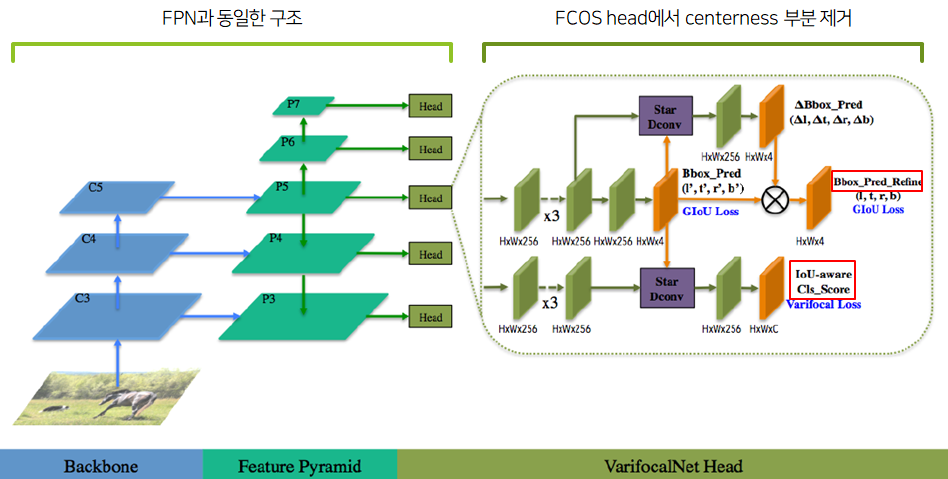
[Experiment]
-
mmdetection
COCO 2017 데이터셋 기반으로 훈련/평가 수행
Learning rate : 초기 학습률 0.01, Linear Warming up(0.1) 적용
backbone : 여러 가지 backbone 사용, epoch 24
입력 이미지 : multi scale train 적용, 1333 x[640:800] 범위의 입력 사용
augmentation : horizontal flip (random)
-
성능 평가
ResNet-50 backbone 모델(최저성능) 의 AP : 44.8, AP(50) : 63.1
Res2Net-101-DCN backbone 모델(최고성능) 의 AP : 50.4, AP(50) : 69.7
[VarifocalNet-X]
-
VFNet-X
FPN을 PAFPN으로 대체, DCN(deformable CNN)과 group normalization 적용
feature map 채널을 256에서 384로 확장
randomcrop, cutout 적용
multi scale train 범위 확대(750x500~2100x1400),
41 epoch로 훈련한 뒤 추가적으로 18 epoch 더 훈련?
stochastic weight averaging 적용
-
성능 평가
Res2Net-101-DCN backbone 모델의 AP : 55.1, AP(50) : 73.0
[참고한 블로그]
Non-Maximum Suppression
Fully Convolutional One-Stage object detection
deformable convolution
Focal Loss
Focal Loss
