프로젝트 3 - FCN 개선 모델
- FCN의 한계
- Decoder 개선
- Skip connection 적용
- Receptive field 확장
[FCN의 한계]
객체의 크기가 크거나 작은 경우 예측을 잘 하지 못한다. 큰 객체는 지역적인 정보만으로 예측하는데, 예를 들어 큰 버스의 정면 사진이 있다면 버스 앞부분 범퍼를 보고 버스로 인식하지만 버스 전면 창에 비친 자전거를 보고 해당 부분은 버스가 아니라고 인식하는 등의 문제가 있다.
Deconvolution(Transposed convolution) 절차가 간단해 경계를 학습하기 어려워서 객체의 디테일한 모습이 사라지는 문제도 존재한다.
[Decoder 개선]
-
DeconvNet
FCN을 성능적으로 개선하기 위해 디코더와 인코더를 대칭으로 만든 형태로, convolution network(VGG16)과 deconvolution network(unpooling, deconv, ReLU)가 대칭형으로 1:1 매핑된다. -
unpooling
max pooling할 때 남게 되는 최대값의 위치(인덱스)를 기억해 뒀다가 unpooling에 사용한다.
pooling을 하면 노이즈는 사라지지만 activation map에서 경계면의 정보가 흐려지는데, unpooling을 통해 경계면을 남겨둘 수 있다. 경계면만 남고 안쪽의 정보가 사라진다는 문제가 있긴 하지만 그건 deconvolution을 통해 채울 수 있다. deconvolution 레이어를 여러 개 쌓아서 입력된 객체의 모양을 복원할 때 얕은 층은 전반적인 모습을 잡아내고, 깊은 층은 세부적인 모습을 잡아내게 된다. -
SegNet
자율 주행 등을 위해 FCN을 속도적 측면으로 개선한 모델이다. pretrained VGG16의 13개 conv 레이어를 인코더로 사용하고, 이를 뒤집어 디코더로 사용한다는 점은 동일하지만 가운데 있던 FC(fully conv)레이어를 모두 제거해서 파라미터의 수를 줄였다. 디코더 부분에서는 transposed conv가 아닌 일반 conv 레이어를 사용하였다.
[Skip connection 적용]
-
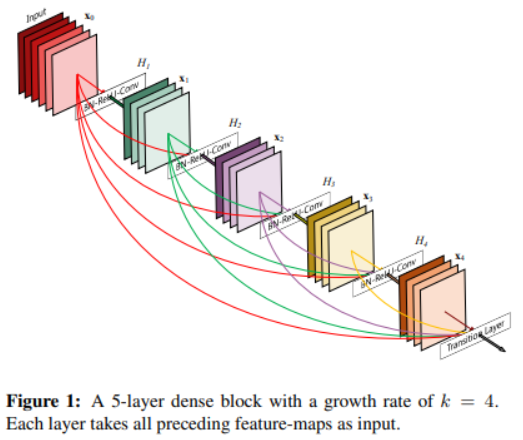
FC DenseNet
ResNet의 skip connection : 레이어를 건너뛰어서 몇 단계 전의 output을 이후 레이어의 입력으로 제공하는 것
FC DenseNet에서도 같은 블록 내의 conv 레이어들의 출력을 skip connection으로 받아온다.
-
Unet
인코더와 디코더가 U자 형태로 결합된 모델로, 인코더를 통과한 결과를 디코더에 concat하는 skip connection 과정이 4번 일어난다. 후속 연구들에 큰 영향을 끼친 논문이다.
[Receptive field 확장]
Receptive field란 뉴런이 '바라보고' 있는 영역이다. Receptive field가 넓으면 전체적인 모습을 볼 수 있어서 segmentation 작업을 효과적으로 할 수 있다.
Receptive field는 conv 연산을 다 하고 나서 나오는 output feature map의 1픽셀이 원본 이미지에서 어느 정도 영역을 커버하는지를 뜻하는데, conv 층 사이에 max pooling 층을 섞어넣어 output feature map의 크기를 작게 만들면 receptive field가 더 넓어지는 효과가 있다. 하지만 resolution 측면에서는 효과가 떨어진다. output feature map이 너무 작아져서 upsampling을 할 때 문제가 생기기 때문이다. 이를 해결하기 위해 제안된 것이 output의 크기를 줄이면서도 효율적으로 receptive field를 넓히는 Dilated convolution(atrous conv)이다.
- DeepLab v1
- DeepLab v2
- DeepLab v3
- DilatedNet
- PSPNet
[피어 세션]
albumentation의 crop을 쓰면 이미지와 json 둘 다 넣기 때문에 알아서 레이블도 잘 잘라 준다
cutmix를 사용하면?
inference는 512으로 하는데 submission은 256
-> 원본, resize, 랜덤크롭256 모델 3개의 성능을 비교해서 별 차이 없거나 작은 이미지가 더 좋으면 계산량을 줄이기 위해 작은 이미지 사용
k-fold 할 때 데이터 유출을 막기 위해서
stratified 클래스 안 쓰고 데이터셋 물리적으로 나눠서 모델도 나누기?
