PE File Format
PE란?
명령(OP Code)에 따라서 지시된 작업을 수행하는 파일을 Executable File, 실행파일이라고 한다. 이런 실행파일은 디스크 상에 저장되어 있다가 실행 시 메모리에 적재되어 실행된다.
실행 파일의 포맷 종류는 사용되는 운영체제 별로 다른데 윈도우 계열은 PE, 리눅스 같은 unix 계열은 ELF, Mac이나 ios 같은 곳에선 Mach-O, 안드로이드 계열에선 DEX 같은 걸로 불린다.
윈도우 운영체제에서 사용되는 실행 파일을 Portable Executable, 즉 PE라고 한다. 포터블이란 뜻이 붙은 것과 같이 다른 운영체제에 이식의 편의를 위해서 만들어졌지만 정작 윈도우 계열 OS에서만 사용되고 있다.
종류
PE 파일의 종류는 이런 표로 정리할 수 있다.
| 종류 | 주요 확장자 | 종류 | 주요 확장자 |
|---|---|---|---|
| 실행 계열 | exe, scr | 드라이버 계열 | sys, vxd |
| 라이브러리 계열 | dll, ocx, cpl, drv | 오브젝트 파일 계열 | obj |
엄밀하게는 obj 파일을 제외하고는 모두 실행가능한 파일이다. dll이나 sys 파일은 explore.exe 같은 셸에선 실행할 수 없지만 디버거 같은 다른 형태의 방법으로는 실행할 수 있다.
PE File Structure
기본
PE 파일의 구조는 기본적으로 크게 Header와 Body로 나눈다. 네트워크를 공부했다면 헤더와 바디라는 표현이 익숙할 것이다.
PE의 구조를 알려면 국룰처럼 사용되는 예시 이미지를 통해 설명하는 것이 편리하다.
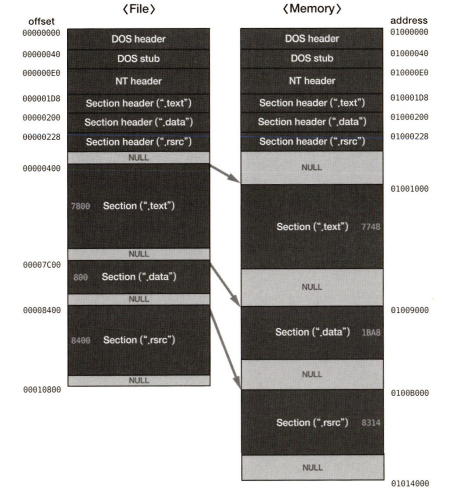
DOS 헤더, DOS Stub, NT 헤더, 섹션 헤더를 합쳐서 PE 헤더라고 한다.
그 아래의 섹션들을 바디라고 한다. 각각의 위치를 표현할 때 파일과 메모리에서 다른 방식이 사용된다는 것이 중요하다.
파일이 디스크 같은 저장매체에 저장되어 있는 상태에선 offset이라는 인덱스를 통해서 위치를 표현하고 접근할 수 있다. 하지만 파일이 메모리에 로드되어 실행되고 있을땐, VA(Virtual Memory)를 통해서 위치가 표현된다.
사진을 보면 한 섹션에서 다음 섹션 사이에 null 패딩이 들어간 것을 확인할 수 있다. 컴퓨터에선 파일, 메모리, 네트워크 패킷 등을 처리할 때 효율을 높이기 위해 최소 기본 단위 개념을 사용하는데, PE 파일에도 같은 개념이 적용된 것이라 볼 수 있다.
각 섹션이 시작하는 위치는 파일 또는 메모리에서 최소 기본 단위의 배수 위치여야 한다.
기본 단위가 1000이라 할 때, 첫 섹션은 4000이 시작이라면 다음 섹션은 5000, 그 다음은 6000이 시작 주소여야 한다는 것이다. 멋대로 5248 이런 번호에서 시작할 수 없다.
첫 섹션이 600 정도만 사용했다면 나머지 400을 null로 채워서 다음 섹션이 시작되는 자리를 1000의 배수로 맞춰주는 것이다.
VA & RVA
PE를 공부할 때 반드시 알아야 하는 개념이다. pe파일이 가상 메모리에 로드 되는 순간 그 위치에 다른 파일이 로드되어 있을 수 있다. 그럴 땐 다른 위치에 재배치 되어 로드되는데 이때 사용하는 주소 체계가 RVA이다.
RVA는 Relative Virtual Address로써, image base라는 기준점으로부터 상대적으로 얼마나 떨어져있는지를 알려준다. VA는 Virtual Address로 프로세스 가상 메모리의 절대 주소를 말한다.
VA = Image Base + RVA
만약에 Image base가 400000이고 RVA가 2000이면 VA=402000이 되는 것이다.
메모리가 아닌 디스크에 파일로 존재할 때는 file offset을 사용한다고 했는데 이걸 RAW 주소라고 한다.
Raw to RVA
되게 중요하다.
RVA에서 Raw를 찾거나 Raw에서 RVA를 계산할 줄 알아야 한다.
이것만 기억하자.
-
RVA에서 Image Base를 더해서 그게 메모리에 무슨 섹션에 위치했는지 찾는다.
예: rva가 5000인데 imagebase가 1000000이면 1005000인데 여긴 .text 섹션이구나 하고 찾는거다. -
위치한 섹션의 시작주소를 찾아서 지금 위치가 섹션 시작에서 얼마나 떨어진 값인지 찾는다.
예: .text는 1001000에서 시작하네. 그럼 1005000에서 4000만큼 차이나는 것) -
그 차이만큼 file offset에서 섹션 시작에서 더한다.
(예: .text가 파일에선 400에서 시작하네. 여기서 4000만큼 떨어진 건 4400이니까 내가 찾는 file offset은 4400이야)
파일이나 메모리에서나 위치의 차이(변위)만큼은 값이 같다.
RAW - PointerToRawdata = RVA - VitrualAddress
즉
RAW = PointerToRawdata + (RVA - VitrualAddress)
여기까지 했다면 이제 PE 파일의 구조를 진짜로 알아보자.
PE Header
PE 헤더는 많은 구조체로 이루어져있다.
DOS Header
PE 헤더 제일 앞부분에는 IMAGE_DOS_HEADER 라는 구조체가 존재한다. 총 40바이트짜리 크기의 구조체이다.
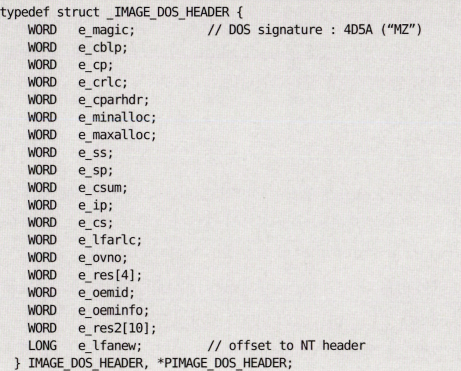
이중에서 맨처음과 마지막에 있는 멤버가 중요하다.
e_magic
모든 pe파일은 hex editor로 열어보면 DOS 시그니처인 4D 5A로 시작하는데 ASCII 값으로는 "MZ"가 나온다.
정말 시그니처라는 표현이 적절하다. JYP노래 시작할 때 "JYP~"하는거랑 비슷한거다.
e_lfanew
이 위치에는 어떤 값이 적혀있다. 이 값이 가리키는 위치로 이동하면 거기가 NT Header 구조체가 시작하는 곳이다.

사진보면 맨처음 4D 5A로 시작하고 끝에는 EO 00 00 00라고 적혀있지만 리틀 엔디언으로 읽어야 하니까 e_lfanew는 000000E0이다.
에디터에서 스크롤을 내려서 000000E0 offset으로 가보면 NT 헤더가 나온다.
DOS Stub
도스 헤더 밑에 나오는 이것은 옵션이다. 옵션이니까 길이가 정해져있지도 않다. 없어도 된다. DOS 환경에서 실행할 때 사용되는 코드인데 요새 DOS를 잘 안 쓰니까...
NT Header
NT 헤더의 구조체는 IMAGE_NT_HEADERS이다.
이 구조체는 248바이트 크기인데 3개의 멤버를 가지고 있다.

1. Signature
: 4바이트 크기로 값이 50 45 00 00으로 정해져있다.
50 45를 아스키 코드를 해석하면 "PE"가 나온다. 이 파일이 PE파일임을 알려주는 시그니처이다.
2. IMAGE_FILE_HEADER
: 파일헤더라고도 하는 20바이트크기 구조체이다. 이걸 또 쪼개보면 이런 멤버들을 담고 있다.
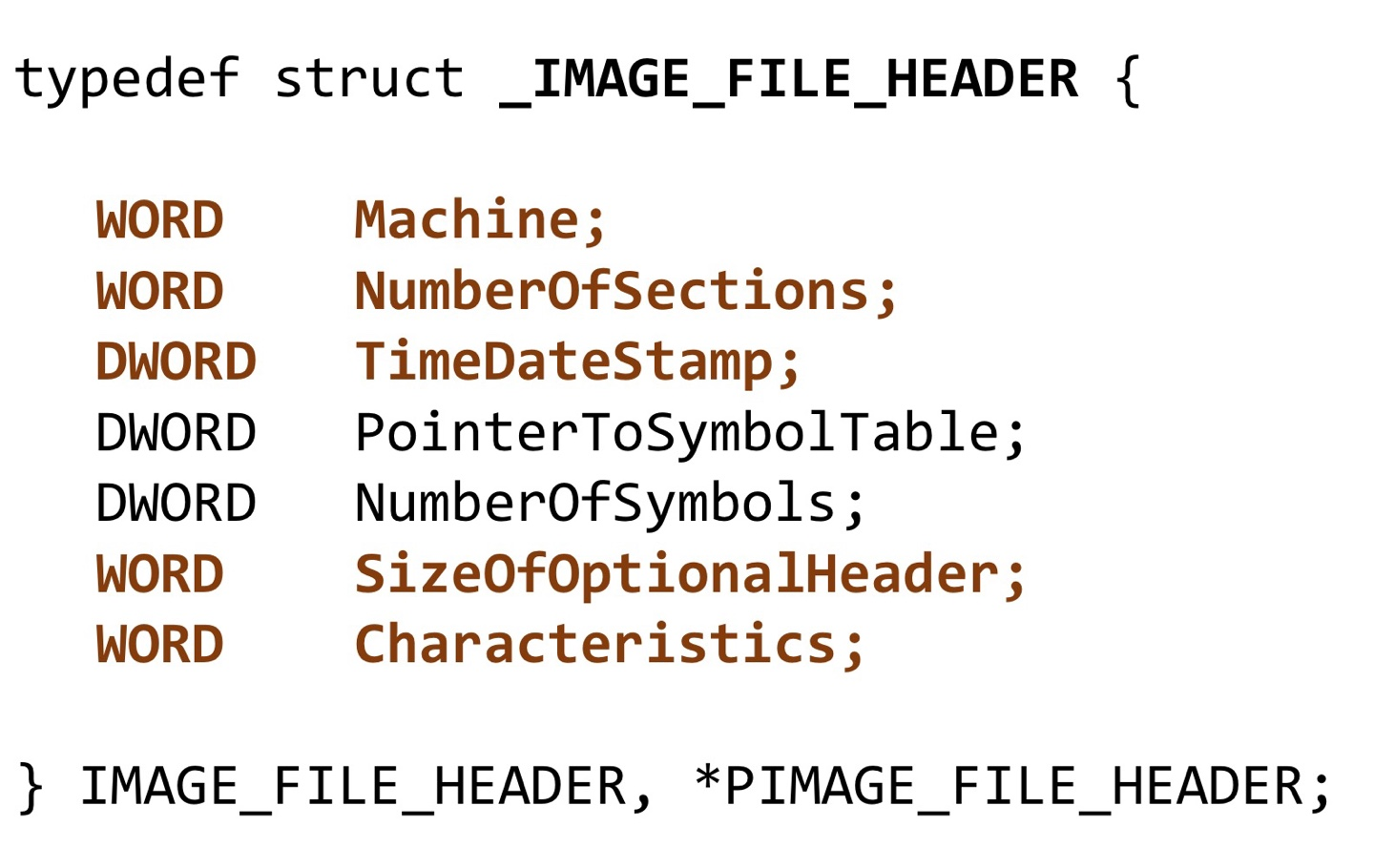
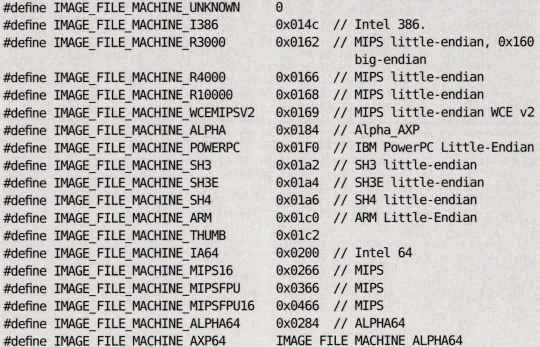
- Machine: 2바이트, cpu 아키텍처의 종류를 알려준다.
- Number of Section: 2바이트, 이 PE 파일에 들어간 섹션이 몇개인지 알려준다. 당연히 0보단 커야할 것이다. 실제 섹션 개수랑 이 값이 다르면 오류가 날 것.
- Time Date Stamp: 4qkdlxm, 컴파일된 시간을 알려준다.
- Size of Optional Header : 2바이트, 이 다음에 뒤따라올 image optional header의 사이즈를 알려준다.
- Characteristics : 이 PE파일이 exe인지, 32비트 환경용인지 등등 속성을 알려준다.
machine을 설명하면 이렇다. cpu별로 고유한 값을 가지는데 그 값에 따라서 어떤 cpu인지 알수 있는 것이다.
characteristic을 잘 이해하면 되는데 각 값마다 의미하는 바가 있다. pe파일에 적힌 값은 이 파일이 가지는 특징의 값들을 모두 더한 값이다.

실행가능한 파일이고, 32비트 머신 환경이면서 dll이다 그러면 뭐 2 + 100 + 2000 =2102를 가지겠지. hex뷰에선 리틀 엔디언으로 가지는 걸 기억하자.
3. IMAGE_OPTIONAL_HEADER
: 224바이트로 NT헤더 중에서 가장 큰 사이즈의 녀석이다.
다양한 값들을 담고 있고, 중요한 값들도 많다.
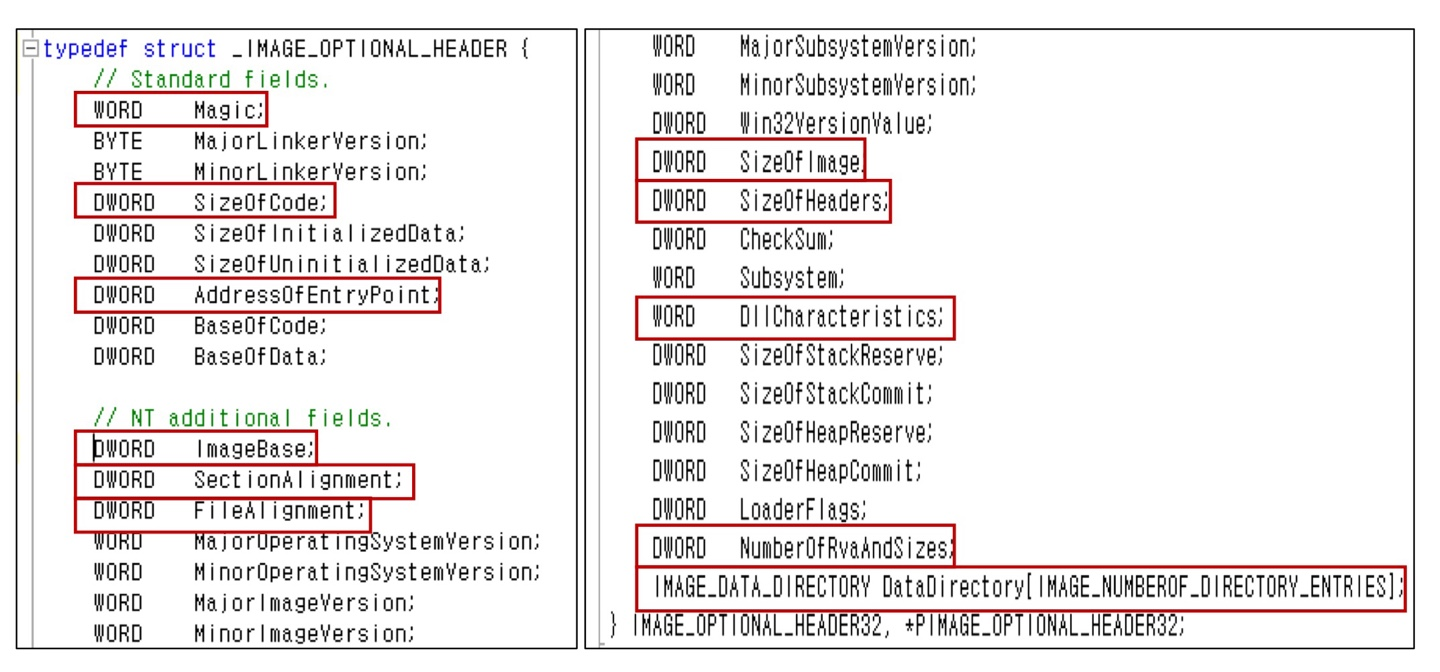
하나씩 살펴보자.
-
Magic
정해진 값을 가진다. header32 구조체면 10b, header64구조체면은 20b를 가진다. 심플 -
Size of Code
.text 섹션의 코드 사이즈를 알려준다. -
Address of Entry Point
매우 중요하다. 프로그램에서 가장 처음으로 실행되는 코드가 시작하는 주소인 EP를 RVA로 담고 있다. -
Image Base
rva를 사용하기 위해서 기준이 되는 베이스 값을 갖고 있다.
32비트 환경의 경우 프로세느는 0부터 ffffffff의 주소 범위를 갖고 있다. 이것도 값이 정해져 있다.
exe 파일은 0x00400000
dll 파일은 0x01000000프로세스가 실행되면 운영체제의 pe로는 프로세스를 메모리에 로딩하고 eip 레지스터를 어디로 둬야겠어? 맨 처음 시작하는 ep로 가야겠지. 그 값을 어떻게 읽어내냐면 Image Base + Address of Entrypoint 이 두개를 합쳐서 읽는다. -
Section Alignment, File Alignment
아까 효율을 위해서 파일/메모리에서의 섹션 크기의 최소단위를 정해둔 거 기억나니.
그 단위를 적은 값이다.
Section alignment는 0x1000가 보통이며 이건 rva에서의 단위이다.
File alignment는 0x200이 보통이며 raw에서의 단위이다. -
Size of Image
PE 파일이 로드될 때 가상 메모리에서 헤더를 포함한 pe image가 차지하는 크기이다. 디스크의 파일 크기와 메모리의 로딩된 크기는 다를 수 있다. 당연히 section alignment의 배수가 되어야 한다. -
Size of Header
DOS 헤더, NT 헤더, Section 헤더를 모두 합친 헤더만의 크기이다.
File alignment의 배수가 되어야 한다.
즉 첫번째 섹션의 위치를 찾으려면 파일 시작에서 size of header의 offset만큼 이동하면 된다. -
Subsystem
이 값을 보고 시스템 드라이버 파일(.sys)인지, .exe나 .dll로 끝나는 일반 실행파일인지 알 수 있다.
| 값 | 주요 의미 | 설명 |
|---|---|---|
| 1 | driver file | 시스템 드라이버(dP ntfs.sys) |
| 2 | Graphic User Interface(GUI) 파일 | 창 기반 애플리케이션(예:notepad.exe) |
| 3 | Console User Interface(CUI) 파일 | 콘설 기반 애플리케이션(예:cmd.exe) |
-
Number of RVA and Sizes
이거 좀 어렵다. 이 값 다음에 뒤따르는게 optional header에 마지막 멤버는 DataDirectory인데, 이 값은 이 Data Directory의 배열의 개수를 나타낸다.
Data Directory엔 이미 IMAGEOF_DIRECTORY_ENTRIES (16)에서 알 수 있듯이 16이라고 적혀있지만 운영체제는 그건 모르겠고 이 Number of RVA and Sizes를 읽고 판단한다. -
Data Directory
이건 하나의 값이 아니라 IMAGEOF_DATA_DIRECTORY라는 구조체으 배열이다. 이 디렉토리는 16개의 엔트리로 구성되어 있다. 사진으로 보자.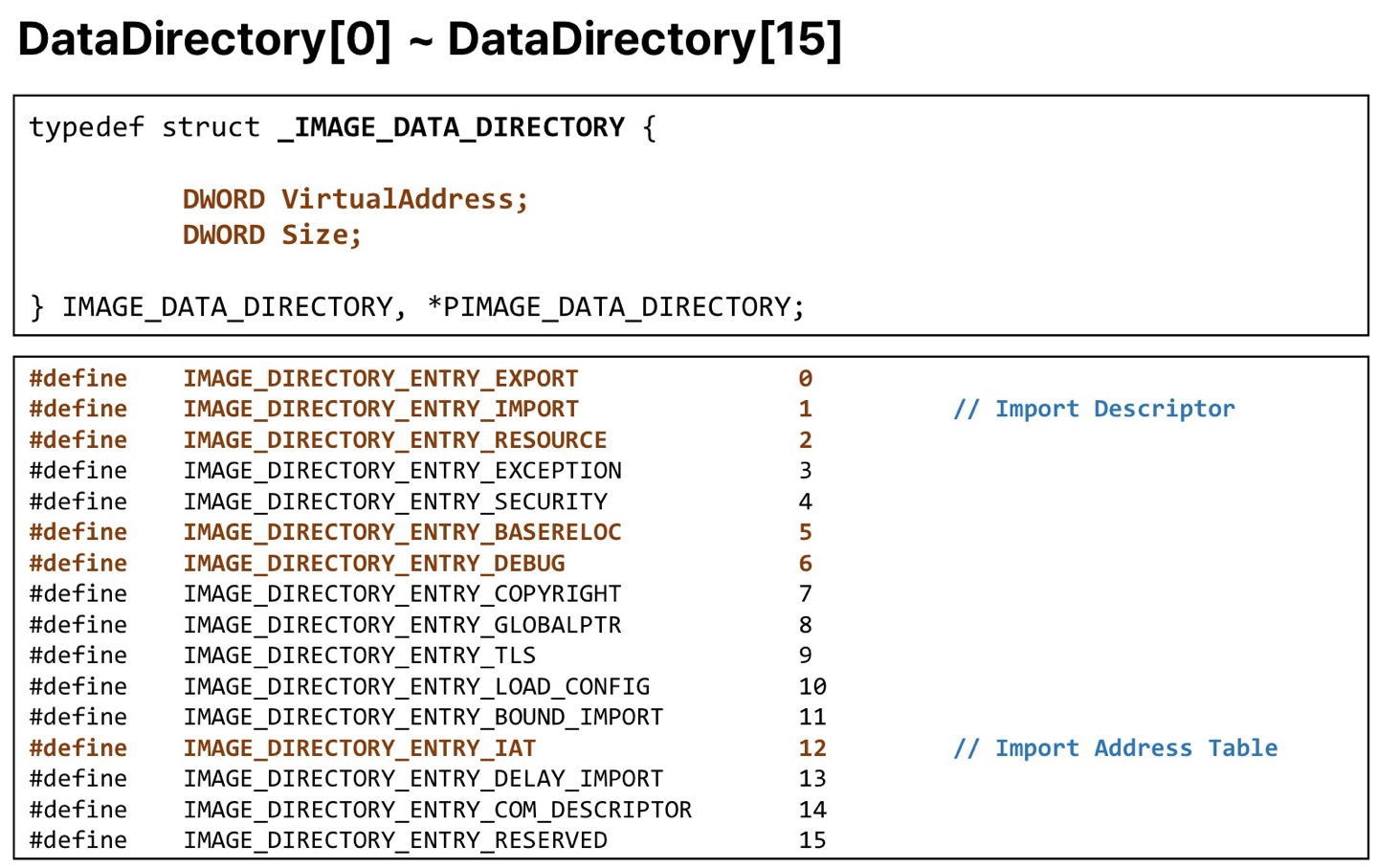
어렵지? 나도 그래.. Export, Import가 중요하니 따로 설명하겠다.
Section Header
각 섹션의 property(속성)을 정의해두었다. code, data,r esource를 여러 섹션으로 구분해두어서 안정성을 꾀어둔게 PE파일의 구조이다. data가 있고 그 뒤에 null padding이 나온 뒤에 code가 있다면, data가 오버플로우로 덮어씌여도 code까지 덮어쓰여질 일이 없게 되는 것이다.
그래서 섹션을 나누게 되었고, 각 섹션이 특징을 설명해줄 헤더가 필요한 것이다. code, data, resource는 모두 권한이 다르다는 것을 먼저 이해해야 한다.
| 종류 | 액세스 권한 |
|---|---|
| code | 읽기(r), 실행(x) |
| data | 읽기(r), 쓰기(w) |
| resource | 읽기(r) |
section 헤더는 다음과 같은 구조체를 가진다.

- Name : 대응하는 섹션의 이름이다.
- Virtual Size: 메모리에서 섹션이 차지하는 크기
- Vitrual Address : 메모리에서 섹션의 시작주소(RVA)
- Size of Raw Data : 파일에서 섹션이 차지하는 크기
- Pointer to Raw Data : 파일에서 섹션이 시작하는 offset 위치
- Characteristics : 섹션의 속성이다.
name의 경우 정해진 규칙은 없어서 변경하거나 규칙은 없다. 하지만 보통 많이 쓰는 정보들이 있다.
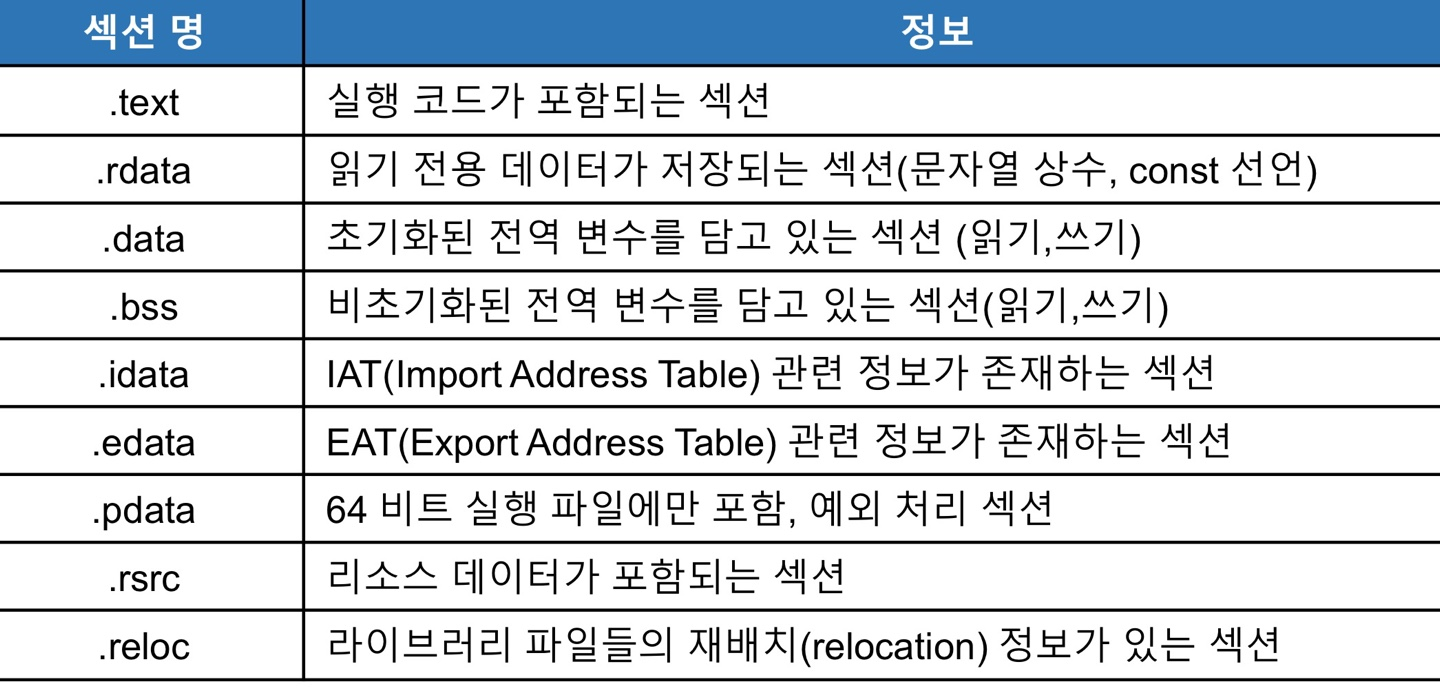
Characteristics에 대해 얘기하자마면 여러 값들의 bit OR조합으로 이루어진다.
IAT (Import Address Table)
PE를 공부하면서 내가 가장 어려워한 부분이다. Import Address Table, 즉 IAT이다. 여기에는 윈도우 운영체제 핵심인 process, memory, dll 구조 등의 내용이 들어가 있다. IAT란 프로그램이 어떤 라이브러리에서 어떤 함수를 사용하고 있는지를 적은 것이다.
DLL
Dynamic Linking Library는 프로그램이 자주 쓰는 라이브러리들을 소스 코드에 다 포함시키지 말고 별도의 파일로 만들어서 필요할 때마다 호출해서 연결시키겠단 개념에서 탄생했다.
DLL을 사용하면 한번 로딩된 dll을 memory mapping 기술로 여러 프로세스에서 공유해서 쓸 수 있다는 점과, 라이브러리가 업데이트하거나 패치해야 할 때 그 라이브러리를 쓴 모든 프로그램을 패치하는게 아니라 dll 파일만 교체하면 된다는 장점이 있다.
IAT에서 DLL을 로딩하기 위해 말하는 방식은 Implicit linking이다. 프로그램이 시작될 때 같이 로딩되고 프로그램이 종료될때 같이 메모리에서 해제되는 것이다.
프로그램이 사용되는 순간 로딩하고 사용 끝나면 메모리에서 해제되는 건 Explicit linking이라고 한다.
프로그램은 다음과 같은 식으로 API를 호출한다.
CALL 메모리 주소 ~~
메모리 주소 ~~는 IAT 메모리 영역이다. 이 주소에는 또 어떤 값이 적혀있겠지. aaaaaa라고 하자. 이 aaaaaa가 바로 내가 호출하기 원하는 dll파일의 함수 주소이다.
CALL aaaaaa라고 바로 하면 안되냐? 안된대....
모든 환경에서 정확하게 함수의 호출을 보장하기 위해서는 함수의 주소를 어떤 곳에다 따로 보관하고, 그 곳을 따로 호출하는게 맞다고 한다. 그리고 여러 dll을 로딩할 때 비어있는 메모리 공간마다 relocating을 시켜야 하기 때문에 call aaaaaaa같은 하드코딩을 할 수 없는 것이다. 하드코딩이라고 적으니까 괜히 있어보인다.
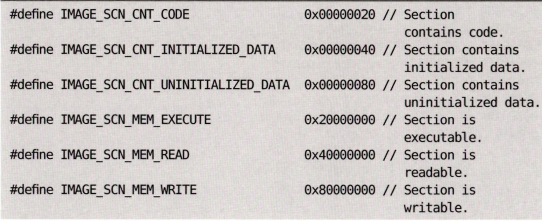
IMAGE_IMPORT_DESCRIPTOR
PE파일이 어떤 라이브러리를 import하는 지는 IMAGE_IMPORT_DESCRIPTOR라는 구조체에 명시하고 있다.
IMAGE_IMPORT_DESCRIPTOR(IID)를 IMPORT Directory Table이라고도 하니 둘다 알아두자.
이건 어느 위치에 속해있냐고? 아까 NT Header에 Image Optional Header에 가면 IMAGE_DIRECTORY_ENTRY_IMPORT가 있다. 거기에서 찾아가는 것인데 정답은 바로 PE Body에 있다.
아까 IMAGE_DATA_DIRECTORY를 보면은 DataDirectory 각각은 VirtualAddress와 Size라는 멤버를 가진걸 볼 수 있다.
이 중에서 DataDirectory[1]에 있는 Virtual Address 멤버가 바로 IID 구조체의 시작 주소이다.
암튼 이 구조체는 이런 것을 멤버들을 가진다.
| 항목 | 의미 |
|---|---|
| Original First Thunk | INT(Import Name Table)의 주소(Rva) |
| Nmae | library 이름 '문자열'의 주소 (RVA) |
| First Thunk | IAT(Import Address Table)의 주소 |
난 여길 공부할 때마다 너무 헷갈렸던게 왜 Thunk가 뭐길래 오리지널 퍼스트랑 퍼스트로 쪼갤까, 그리고 왜 어떤 이름을 따로 어디다가 a에 보관해두고, 그 a의 주소를 b에 넣어둘까 참....
몇가지를 미리 알아두자면
- IAT와 INT는 4바이트 long 타입으로 크기가 서로 같다.
- INT에서 각 원소의 값은 IMAGE_IMPORT_BY_NAME 구조체 포인터다. 뭔 말이냐고? 모르면 넘어가
이제 이 열받는 그림을 이해해야 한다. 그러기 위해선 이 개념을 알아야 한다.
무언가를 호출할 땐,
호출되는 놈의 이름
호출되는 놈의 실제 함수
를 따로 따로 불러와서 합친다는 개념이다. 이름이랑 몸체랑 한번에 보관하면 좋을거 같은데 안 그러신대.
PE로더가 임포트하는 함수의 주소를 IAT에 채워넣는 건 이런 과정을 거친다.
1. IID(image_import_descriptor)의 Name 멤버를 읽어서 라이브러리 이름 문자열을 읽어옵니다. 뭐 예컨대 "kernel32.dll"이라고 적혀있는걸 읽어서 얻는거지
2. 그 라이브러리를 로딩해.
3. IID에서 Original First Thunk를 읽어서 INT 주소를 읽어
4. 그 INT 주소로 찾아가서 놓여진 배열을 하나씩 읽으면서 내가 찾는 해당 IMAGE_IMPORT_BY_NAME 주소(RVA)를 얻어내
5. IMAGE_IMPORT_BY_NAME의 Name이나 Hint(ordinal) 멤버를 이용해서 해당 함수가 시작하는 주소를 얻어내.
(명령어로는 GetProcAddress("GetCurrentThreadId"라고 하나봐)
6. IID에서 First Thunk를 읽어서 IAT 주소를 읽어
7. 그 IAT 주소로 가서 5번에서 얻어낸 함수 시작 주소를 입력해서 채워놔.
8. INT가 끝날 때까지 4~7 반복하는거야. INT가 끝난다는 건 Null을 만날 때까지란 뜻.이건 notepad.exe를 실제로 뜯어보면서 이해하는게 훨 낫다.
자 봐봐 IMAGE_OPTIONAL_HEADER32.DataDirectory[1]로 찾아가면은 이런걸 볼 수 있어.
 offset 158은 DataDirectory[0]이니까 Export라서 지금 볼 필요 없고 160을 봐봐. 첫번째 4바이트가 Virtual Address고 두번째가 Size야.
offset 158은 DataDirectory[0]이니까 Export라서 지금 볼 필요 없고 160을 봐봐. 첫번째 4바이트가 Virtual Address고 두번째가 Size야.
첫번째 바이트 봐봐 04 76 00 00 C8 00 00 00이 있지 리틀엔디언으로 읽으면 7604 이게 Import Directory의 rva야. c8이 사이즈고.
7604 rva를 raw로 바꾸는 거 기억나지? 바꾸면 file offset은 6A04야. 파일 offset에서 6A04를 보자.
(자꾸 RAW로 보는 건 PE 뷰어에서는 실행된걸 보는게 아니기 때문에 파일로 들여다보려면 offset을 알야아 하는거다)

회색칠해진 곳이 전부 다 IMAGE_IMPORT_DESCRIPTOR(IID) 구조체들의 배열이고 박스쳐진 곳이 첫번째 원소이다. 이 첫번째 구조체의 멤버를 살펴보자.
- 90 79 00 00 : Original First Thunk를 의미한다. INT의 RVA 주소가 00007990이란 걸 알 수 있다.
- FF FF FF FF : Time Date Stamp. 안 중요하겠지.
- FF FF FF FF : ForwarderChain. 대체 뭘까
- AC 7A 00 00 : Name이다. 라이브러리 이름 문자열의 주소가 7AAC란 것이지.
- C4 12 00 00 : First Thunk. IAT의 RVA 주소가 12C4란거지.
| 항목 | 의미 |
|---|---|
| Original First Thunk | INT(Import Name Table)의 주소(Rva) |
| Nmae | library 이름 '문자열'의 주소 (RVA) |
| First Thunk | IAT(Import Address Table)의 주소 |
이제 이 표에 있었던 어려운 것들을 하나씩 뜯어보면서 공부하자구.
Name
Name의 주소인 7aac부터 raw로 바꾸면 6eac가 된다. 6EAC 파일 offset에 가보면 dll의 이름이 보인다。comdlg32.dll이래.
INT
INT로 가보자. 7990을 RAW로 바꾸면 6D90이다.

여기 적혀있는 것들은 다 주솟값들이다. (마지막에 NULL들 빼고) 주소 하나하나는 각각 IMAGE_IMPORT_BY_NAME 구조체를 가리킨다.
첫번째 구조체는 00007A7A 주소이다. 이 RVA를 RAW로 바꾸면 6E7A이다. 이 offset을 따라가면 프로세스가 임포트하는 dll의 API 함수 이름들이 나타난다.
IMAGE_IMPORT_BY_NAME

아까 함수가 임포트되는걸 IAT에 채워넣는 과정에서 5번 과정을 읽어보면 "IMAGE_IMPORT_BY_NAME의 Name이나 Hint(ordinal) 멤버를 이용해서 해당 함수가 시작하는 주소를 얻어내." 라고 적혀있었지.
즉 이게 그 IMAGE_IMPORT_BY_NAME인데 여기서 Hint나 Name 멤버를 볼 수 있다.
0F 00 : Hint(Oridinal)을 의미한다. 이 값 000F는 라이브러리에서 함수의 고유 번호이다.
그 뒤에 보이는게 바로 함수의 이름 문자열 값이다. 읽으면 'PageSetupDlgW'라는 함수다.
이런 식으로 이 comdlg32.dll이 임포트하는 함수의 이름을 모두 알아낼 수 있다.
IAT
IAT의 RVA는 12C4였고 이걸 RAW로 바꾸면 06C4이다. 찾아가보자.

06C4부터 06EB까지가 아까의 comdlg32.dll 라이브러리가 IAT 배열에서 차지하는 영역이다.
06 49 32 76 : 이미 IAT 첫번째 원소가 76324906으로 하드코딩 되어있다. 의미없는 값이라고 한다. nopepad.exe가 메모리에 로드되면 이 값이 정확한 주솟값으로 변경된다고 한다. 또는 이미 정확한 주솟값일 수도 있다.
디버거를 이용해서 보자.
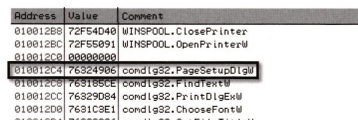
ImageBase까지 합쳐진 가상 주소 10012C4에는 76324906이 적혀 있고 이 주소는 comdlg32.dll 라이브러리으l PageSetupDlgW 함수를 의미한다는 것이다. 이 주소로 가면 이 함수의 시작을 볼 수 있다.

짱이지
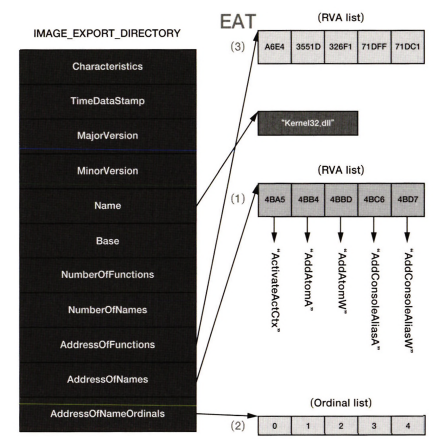
EAT (Emport Address Table)
EAT는 라이브러리 파일에서 제공하는 함수를 다른 프로그램으로 내보내서 그 프로그램이 가져다 쓸 수 있도록 해주는 매커니즘이다. EAT를 통해서만 내가 원하는 라이브러리에서 export하는 함수의 시작 주소를 정확히 알아낼 수 있다.
IAT가 이해되었은가 조금 더 탄력적이게 가보자. 이 Export 정보는 IMAGE_EXPORT_DIRECTORY 구조체에 담겨있다.
PE 파일이 여러개 라이브러리를 동시에 import하기에 IID는 여러 IID 구조체들의 배열로 존재할 수 있지만, 이 IED는 PE파일에 하나만 존재한다.
NT Header에 Image Optional Header에 가면 IMAGE_DIRECTORY_ENTRY_EXPORT가 있고
IMAGE_DATA_DIRECTORY[0]의 Virtual Address 멤버가 바로 IMAGE_EXPORT_DIRECTORY의 시작 주소이다.
IMAGE_EXPORT_DIRECTORY
IMAGE_EXPORT_DIRECTORY 의 구조체는 이런 멤버를 가지고 있다.

몇가지 중요한 멤버들을 보자.
| 항목 | 의미 (여기서 주소는 모두 RVA이다) |
|---|---|
| Number of Functions | 실제 export 함수 개수 |
| Number of Names | Export 함수 중에서 이름을 갖는 함수 개수, 당연히 전체 Number of Functions 이하일 것 |
| Address of Functions | Export 함수 주소 배열, 배열된 원소 개수=NumberOfFunctions이다. |
| Address of Names | 함수 이름 주소 배열, 배열된 원소 개수=NumberOfNames |
| Address of NameOrdinals | Ordinal 배열, 배열된 원소 개수=NumberOfNames |
아까 IAT 볼때 Hint랑 name 개수가 같은 거 알았지? 그래서 둘다 number of names랑 같은거야.
라이브러리에서 함수 주소를 얻는 API는 GetProcAddress()였다. 이 api가 함수 이름으로부터 어떻게 함수 주소를 얻어내는지 보자.
<GetProcAddress() 동작원리
1. AddressOfNames 멤버로부터 '함수 이름 배열'로 간다.
2. '함수 이름 배열'엔 문자열 주소가 저장되어 있다. strcmp이란 문자열 비교함수로 내가 원하는 함수 이름ㅇ르 찾는다.
3. AddressOfNameOrdinal 멤버로부터 'ordinal 배열'로 간다.
4.'ordinal 배열'에서 아까 함수 이름 배열 인덱스 순서로 해당 ordinal 값을 찾는다.
5. AddressOfFunction 멤버를 이용해 '함수 주소 배열(EAT)'로 간다.
6. '함수 주소 배열(EAT)'에서 아까 구한 ordianl을 배열 인덱스로 하여 원하는 함수의 시작 주소를 얻는다.이 과정이 이해되면 좋을텐데.
자 함수 이름 배열에 문자열 주소들이 이렇게 있다고 보자
aaaa | bbbb | cccc | dddd | eeee ...
내가 원하는 게 eeee라고 하자. strcmp로 eeee를 찾아낸다. 이때 다섯번째에서 찾았으니까 이 5번째 인덱스란걸 기억하는거야.
ordinal 배열로 가자
가 | 나 | 다 | 라 | 마 | 바 ...
아까 기억한 5번째 인덱스에서 이 함수의 oridinal이 '마'라는걸 알아낸다.
EAT 배열로 간다.
AAA | BBB | CCC | DDD | EEE | FFF ...
ordinal이 '마', 다섯번째란 거에서 이 함수의 시작 주소가 'EEE'라는 걸 알아낸다.
내가 이해한 것은 이런 원리였다. 그림으로 보면 이렇다.
실습으로 보자. kernel32.dll 파일의 EAT에서 AddAtomW 함수 주소를 찾아내는 것이다.

교아까 notepad.exe로 실습 시작할 때 offset 158부터 15F까지가 export지만 그건 notepad.exe고 이건 kernel32.dll이다. 168부터 16F까지가 DataDirectory[0]인 Export 부분이다.
아까랑 마찬가지로 첫번째 바이트 0000262C가 Export Directory의 rva가 되는거고 00006D19 바이트가 Export Directory의 크기인것이다.
262C rva를 raw로 바꾸면 1a2c이다. 1A2C offset으로 가보자.

이게 IMAGE_EXPORT_DIRECTORY 구조체다. 각 offset의 적힌 value마다 어떤 멤버인지를 보자.
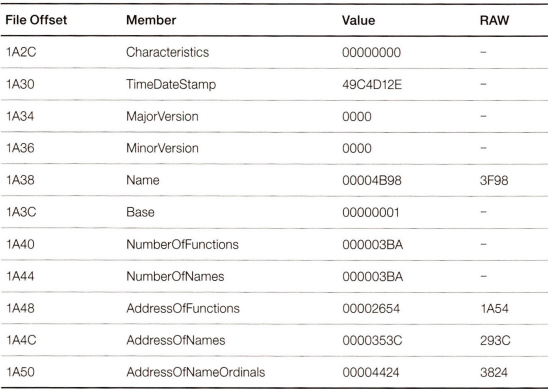
이제 이 멤버에서 GetProcAddress() 동작 원리 순서대로 진행하자.
1. 함수 이름 배열
Number of Names는 3BA였다. Address of Names 멤버 값 rva는 353C였고 RAW로 변환한게 293C였다. 이 offset을 찾아가자.

저 rva 들을 하나씩(4바이트씩) 다 찾아보면 함수 이름 문자열들이 나온다.
2. 원하는 함수 이름 찾기
하나씩 찾아봤는가? 세번째 원소 00004BBD를 가면 AddAtomW() 함수의 이름 문자열을 찾을 수 있다. 4BBD를 offset으로 하면 3FBD이다. 확인해볼까.

진짜지? 이제 이게 3번째에 나왔단걸 기억해야 한다. 세번째니까 인덱스로는 0이다. 인덱스는 0부터 시작하니까!
3. Ordinal 배열
AddAtomW 함수의 ordinal을 알아내자. Address of Name Ordinal 멤버 rva 값은 4424였고 raw로 바꾸면 3824이다.
기사님 3824로 가주세요

2바이트 단위의 ordinal이 보인다.
4. ordinal 찾기
아까 인덱스가 2였지. 즉 세번째 ordinal을 구할 수 있다. '0002'이거다.
5. 실제 함수 주소 찾기
마지막이다. Address of Function 멤버의 rva값은 2654였지. raw로 바꾸면 1A54란다. 그리로 가자.

4바이트 단위씩 RVA 배열들이 나타난다. 아까 ordinal이 2였으니까 세번째 rva를 읽어보면 000325F1이 나온다.
kernel32.dll의 imagebase는 7C7D0000이었으니까 절대 주소 VA는 7C7D0000 + 325F1 = 7C8026F1이다. 다 구해놓고 16진법으로 계산 안하고 10진법으로 계산하는 실수를 하지 말자.
디버거로 확인해볼까.
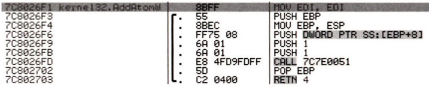
이 VA 주소에 정확히 kernel32.dll의 AddAtomW 함수가 시작하는 걸 알 수 있다.
