Upack
Ultimate PE Packer의 줄임말로 실행 압축기이다. 굉장히 독특하게 PE 헤더를 변형시켜버려서 pe view 같은 기존의 분석기들이 제대로 파일을 열어보거나 분석할 수 없었다.
특징
<리버싱 핵심원리>의 교재 순서대로 설명을 진해하기보단 좀 더 쉬운 순서라고 생각되었던 방법으로 진행하겠다.
미리 알아둬야 하는 UPack의 특징이 있다.
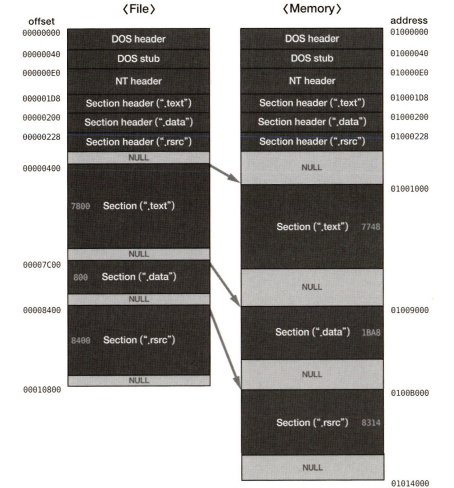
기존의 파일이 PE로더에 의해 메모리에 로드되는 모습이다.
UPack은 "겹쳐쓰기"라는 걸 적극적으로 이용해서 파일을 압축한다.
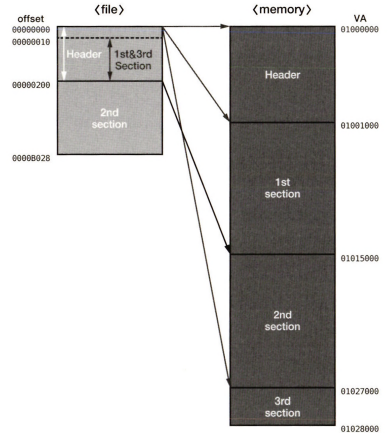
이 사진을 내가 굉장히 자주 반복할 것이다. 미리 기억둘 것을 정해줄게
- 헤더를 비롯해서 기존의 남는 공간들을 촘촘하게 겹쳐서 압축한다. 때론 원래 데이터 위에 값을 덮어쓰기도 한다.
- 헤더, 첫번째 섹션, 세번째 섹션이 파일에선 같은 위치에 겹쳐서 압축되어 있다.
- 그게 메모리에 로드될 땐 자기가 가진 RVA 값에 따라서 펼쳐지듯 로드된다.
- 파일에서 offset 200이 첫번째와 세번째 섹션의 끝이다.
- 메모리에서 첫번째 섹션의 크기는 14000인데 이건 원본 notepad.exe의 size of image와 같다.
- 두번째 섹션에 notepad.exe가 압축되어 들어있다.
- 압축된 그놈의 풀면은 첫번째 섹션에 전부 펼쳐진다. 그래서 첫번째 섹션 크기랑 원본의 size of image랑 같은 것이다.
UPack 실습 유의
UPack으로 실행 압축한 파일들은 기존의 pe 툴로 열리지 않았다. 그래서 악성코드들이 upack으로 실행 압축된 경우가 많았다. 결국, upack으로 압축된 모든 파일은 그냥 악성파일로 진단해버린다. 그래서 upack 패커를 다운받거나 upack으로 압축된 파일을 다운받으려고 하면 시스템에 있는 anti-virus 툴들이 전부 막아버리므로 잠깐만 이 실시간 검사 기능을 꺼놔야 한다.

겨우 다운받았네. 웹에서도 이걸 막아둔다.
이번 실습에선 pe view가 작동하지 않는다고 하니 Stud_pe를 쓸 것이다. 근데 교재가 옛날거였고 지금은 될 수도 있지 않을까 싶긴 하다.
집가서 밥먹고 마저 쓸게
왔다.
UPack 뜯어보기 실습
PE 헤더 비교
먼저 HxD로 기존 파일과 upack으로 압축된 파일의 헤더를 비교해보자.
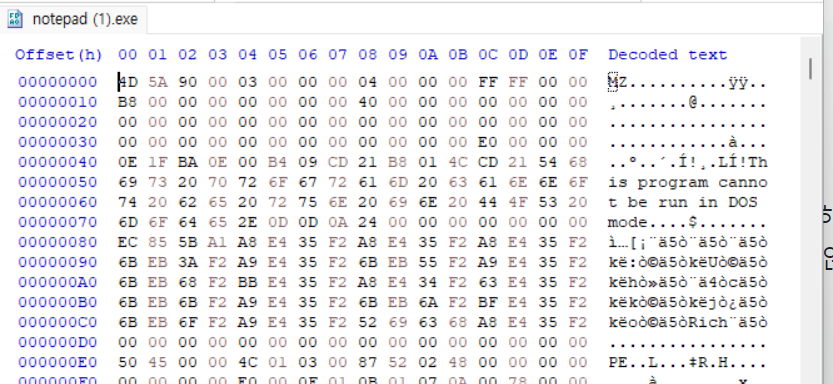
보면 기본적으로 우리가 아는 모습이다.
MZ 시그니처가 나오고 DOS Stub이 나오고 offset 3C 부분에 E0 00 00 00이 있다. 이 lfa_newd 값으로 가면 EO Offset에 PE 시그니처가 있는 것을 볼 수 있지.
이번엔 압축된 걸 보자.

MZ 시그니처가 나오고 그 다음 줄에 바로 PE 시그니처가 나오고 있다.
DOS Stub은 아예 사라졌다.
이러한 이유는 바로
헤더 겹쳐쓰기
때문이다. 헤더를 겹쳐쓰면 헤더 공간을 절약할 수 있다. 그리고 복잡성도 증가해서 분석을 어렵게 만들고.
맨처음 헤더의 구조를 생각해보자.
e_magic : offset 0에 위치한 멤버로 매직넘버 MZ (4D5A)
e_lfanew : offset 3C에 위치한 멤버로 새 exe 헤더의 파일 오프셋을 알림
이 두가지 멤버가 중요했었다. lfanew의 값을 지정하면 그 위치로 NT Header가 시작하는 것이다.

압축파일에선 그냥 이 e_lfanew 값을 10으로 해버린 것이다. 그래서 DOS Stub도 날리고 그 자리에 바로 NT 헤더가 들어서게 한 것이다.
IMAGE_FILE_HEADER
UPack은 IMAGE_FILE_HEADER에서 Size of Optional Header의 값을 변경한다. 이런 변경의 목적은 이따 설명하겠다.
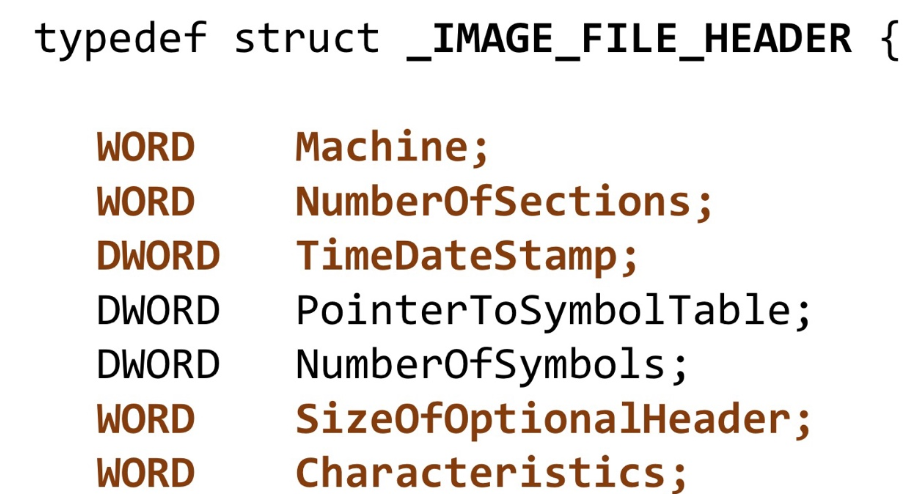
PE 헤더의 IMAGE_FILE_HEADER에는 Size of Optional Header라는 멤버가 있다. 이 값은 이 헤더 다음에 올 IMAGE_OPTIONAL_HEADER의 사이즈를 알려주는 것이다.

기존 32비트 exe 파일에선 이 값이 0xE0, 즉 228바이트로 고정된 사이즈였다.
그런데 upack으로 압축된 파일에선 이 멤버의 값이 달라져있다.

바로 0148로 바뀌어있다. 사이즈가 더 커진 것이다.
여기서 생각해봐야할 것이 있다.
Image of Optional Header가 끝나면 Section Header가 나타난다. 하지만 엄밀하게 말해보자면, Image of Optional Header는 사실 구조체라 E0으로 사이즈가 고정된 것이지만 이게 시작되고 Size of Optional Header의 값만큼 지나고나서야 섹션 헤더가 시작될 수 있다.
즉 실제론 옵셔널 헤더는 다 끝났지만, 사이즈 값이 실제 크기보다 크다면 텅빈 공간이 생기고 그리고 나서야 섹션헤더가 시작되는 것이다.
Upack은 이걸 노린 것이다. EO에서 148로 Size of Optional Header를 늘려서 생기는 Optional Header와 섹션 헤더의 사이에 압축을 해제하는 디코딩 코드를 박아둔 것이다.
한번 확인해보자.
PE 헤더 복습하는 겸으로 상세하게 해보자.
 offset 10에서 NT 헤더 시작. 맨처음 DWORD 00 00 45 50은 시그니처.
offset 10에서 NT 헤더 시작. 맨처음 DWORD 00 00 45 50은 시그니처.
 그 다음 20바이트가 IMAGE_FILE_HEADER
그 다음 20바이트가 IMAGE_FILE_HEADER
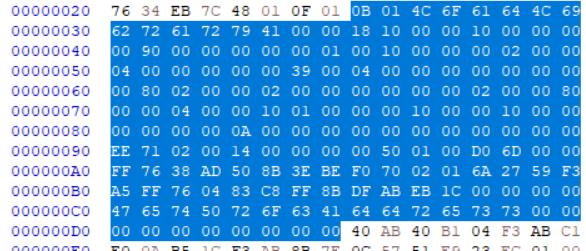 그 다음 이만큼이 IMAGE_OPTIONAL_HEADER. 근데 이럼 176바이트 밖에 안되는데? B0사이즈인데? 이건 대체 왤까.
그 다음 이만큼이 IMAGE_OPTIONAL_HEADER. 근데 이럼 176바이트 밖에 안되는데? B0사이즈인데? 이건 대체 왤까.
왜냐면 뒤에 나오는 NumberOfRvaAndSizes 조정때문에 여기까지만 되었다. 원래는 더 있어야 하는거 맞아.
그치만 Size of Optional Header은 148로 되어있어서 offset 170까지가 Optional Header한테 할당된 공간이다.
실제로 IMAGE_OPTIONAL_HEADER가 끝나는 오프셋은 D7이다.
그리고 그 다음 헤더인 IMAGE_SECTION_HEADER가 시작되는 것은 170이다. 0x99 바이트만큼의 갭 공간이 있다. 이 공간엔 뭐가 들어가있을까
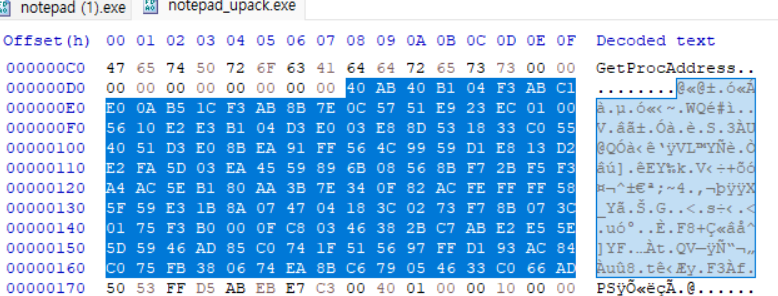
이 데이터를 어셈블리 코드로 인식해서 디스어셈블링해보면 upack에서 사용하는 코드가 나온다고 한다. 어케 디버거로 돌린건진 모르겠다.
IMAGE_OPTIONAL_HEADER
IMAGE_OPTIONAL_HEADER에도 건드려진 부분이 있다. 바로 NumberOfRvaAndSizes 멤버이다. 이 멤버는 뒤따르는 DataDirectory 배열의 개수를 정한다. 실제로는 16개로 정해졌어도 PE로더는 이 멤버의 값을 읽어서 그 값만큼의 DataDirectory만 읽는다.
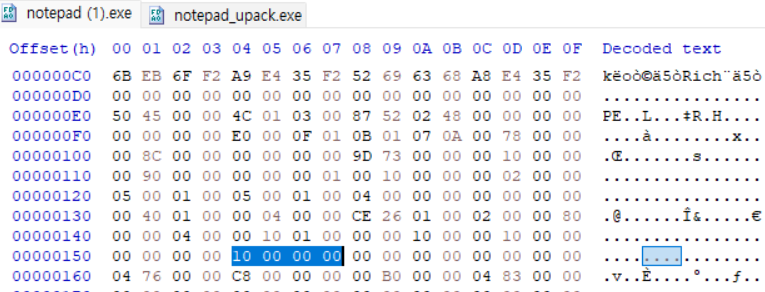 기존 PE파일에는 Data Directory의 개수를 0x10개(16개)로 정해진대로 적혀있다.
기존 PE파일에는 Data Directory의 개수를 0x10개(16개)로 정해진대로 적혀있다.
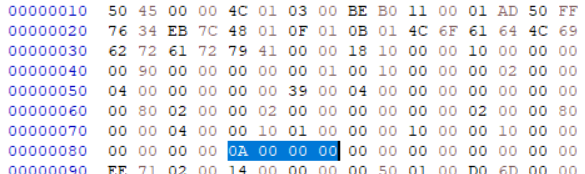 값이 0A개로 되어있다. 즉 10개이다. DataDirectory 구조체 배열에서 DataDirectory[0]~[9]까지만 읽고 뒤에 3개는 날리겠단 것이다.
값이 0A개로 되어있다. 즉 10개이다. DataDirectory 구조체 배열에서 DataDirectory[0]~[9]까지만 읽고 뒤에 3개는 날리겠단 것이다.  즉 Load_Config Directory부터는 무시되고 그 위에 UPack 코드가 덮이게 되는 것이다. NumberOfRvaAndSizes인 0A 00 00 00 다음에 이어지는 Data Directory를 8칸씩 끊어서 10개를 세어보자.
즉 Load_Config Directory부터는 무시되고 그 위에 UPack 코드가 덮이게 되는 것이다. NumberOfRvaAndSizes인 0A 00 00 00 다음에 이어지는 Data Directory를 8칸씩 끊어서 10개를 세어보자.
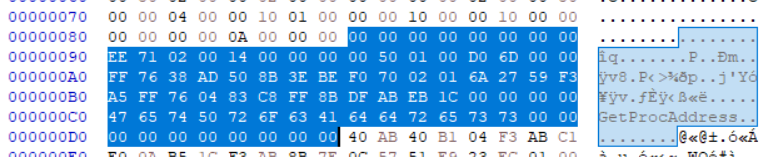
즉 IMAGE_DATA_DIRECTORY가 여기까진 사용되는 것이고,  나머지 6개블럭, 여기가 DataDirectory라고 여겨지지 못하게 되는 부분이다. 이 부분은 Upack자체의 디코딩 코드가 적혀있다.
나머지 6개블럭, 여기가 DataDirectory라고 여겨지지 못하게 되는 부분이다. 이 부분은 Upack자체의 디코딩 코드가 적혀있다.
IMAGE_SECTION_Header
UPack은 PE 헤더에서 잘 쓰이지 않는 영역 구석구석을 찾아서 자신의 데이터를 기록해뒀다. IMAGE_SECTION_HEADER에도 실행에 사용되자 않는 영역이 있다. 섹션 헤더는 아까 offset 170부터 시작한다고 했지?

이런 부분 쓸데없는 거임.
아예 쓸데없는거 모아서 정리해보자.
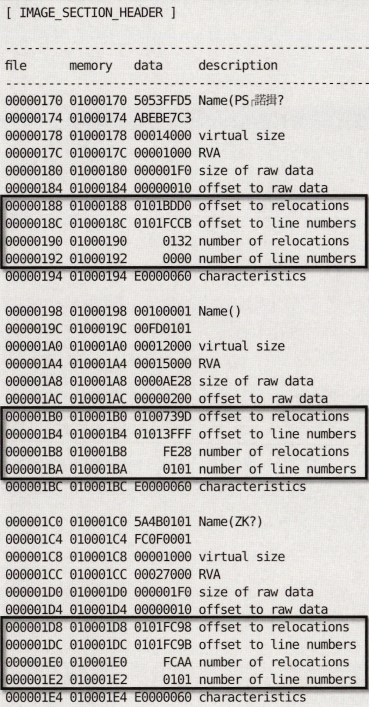
이렇게 된다.
섹션-헤더 겹쳐쓰기
아까 이 사진 기억나지? 지금 파일을 보면 섹션과 헤더가 겹쳐져있다. 이걸 설명할 것이다.
 Stud PE로 열어보면 첫번째 섹션과 세번째 섹션이 이상한게 있다.
Stud PE로 열어보면 첫번째 섹션과 세번째 섹션이 이상한게 있다.
바로 RawOffset이 동일하다는 것이다. 게다가 RawSize도 똑같다. 즉 둘다 offset 10에서 시작하면서 크기도 1F0이란 것이다. (offset 010~1ff까지 차지한다는 소리)
근데 아까 offset 10은 NT 헤더가 시작하는 곳이기도 했다.
이게 가능한 이유는 PE의 규칙에서 이러지 말란 법은 없기 때문이다. 섹션들과 헤더의 메모리에서의 시작주소인 RVA와 메모리 크기인 Virtual Size만 다르다면 파일에서는 서로 같아도 별반 상관이 없다.
아까 저 그림에서 두번째 섹션에 담긴 압축된 notepad.exe를 압축해제해서 첫번째 섹션에 풀어버린다고 했었다. 그럴 때 첫번째 섹션을 들여다보면 이런 구조로 되어있다.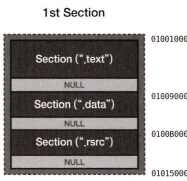
RVA to RAW 계산 (Offset 강제 변환)
UPack에서 가장 특이한 점이라고 볼 수 있다.
기존에 우리가 RVA에서 RAW 주소를 알아내는 방법은 어떤 거였나.
- 해당 RVA가 어느 섹션에 위치하는지, 혹은 헤더에 위치하는지 찾아낸다.
- 해당 섹션의 Entrypoint Virtual Address를 빼준다. 즉 섹션의 시작에서 얼마나 떨어져 있는건지.
- 그 차이만큼 파일에서의 Pointer to Raw Data offset에서 더해준다.
이런 방식대로 우리가 계산하면 실패하게 된다. 한번 Entry Point를 찾아보자.
 File header에서 Address of EntryPoint 멤버는 RVA 1018이다.
File header에서 Address of EntryPoint 멤버는 RVA 1018이다.

Section header에서 찾은 pointer to raw 값은 10이다.
RVA 1018은 첫번째 섹션에 존재하는 위치다. 첫번째 섹션의 시작 Virtual Address는 1000이었다. 아까 그림에 있더라.
그러면 1018과의 차이는 18이다. Pointer to Raw인 offset 18에서 더해주면 28
그럼 과연 offset 28에 EP가 적혀있느냐? 그런거 없다.
그런거 없다.
이유는 왜냐.
Pointer To Raw는 강제 변환되어야 하니까!
뭔 말인지 설명하겠다.
pointer to raw는 각 섹션이 파일에서 시작되는 시작 offset이지?
근데 파일에서 각 섹션의 크기는 file alignment의 배수여야 하는거 아니야?
section alignment는 200이잖아.
첫번째 섹션의 pointer to raw가 10이라고 적혀있어도 실제로 10이 가능하냐 묻는다면 불가능이다. 0이나 200, 400같이 file alignment의 배수여야지.
그래서 pointer to raw 10은 그와 비슷한 file alignment의 배수인 0으로 강제 변환된다.
그럼 다시 계산해보자.
1018 - 1000 + 0(강제변환) = 18,
즉 entrypoint offset은 18이다. 가보자.

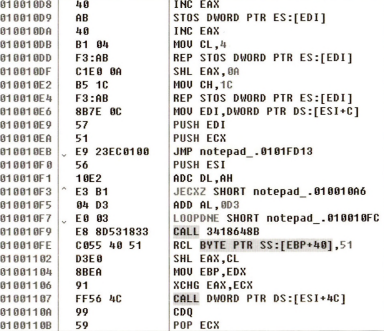
바로 여기가 EP 코드가 위치한 곳이다. 디버거로 이 코드를 살펴볼 수 있다고 한다. 이거 어떻게 하는건지는 찾아봐야겟따.
BE B01101
AD
50
FF76 34
EB 7C
질문. 근데 이런 헥스값 주소로 읽을 땐 다 리틀엔디언으로 읽으면서 왜 instruction으로 읽을땐 빅엔디언으로 읽음? 얼탱
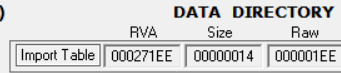
Import Table
IMAGE_IMPORT_DESCRIPTOR 구조체에서 Import Directory Table의 주소를 얻어와야 한다는데 이건 대체 어떻게 얻어낸 건지 모르겠네;

Stud_PE에서 알려준 Import Table 주소 271EE 덕분에 해결.
Raw로 바꿔야 하는데 이미 1ee라고 알려주네.
어케 나온건지 해볼게.
271EE는 메모리에서 3번째 섹션이지. 기준 Virtual offset이 27000이네.
세번째 섹션의 시작부터 1EE만큼 떨어진거다.
파일에서 세번째 섹션의 Pointer to Raw는 10일지라도 file alignment의 배수인 0이 된다.
그래서 271EE - 27000 + 0 = 1EE가 된다.
HxD로 1EE 가보자.
 여기에 UPack의 트릭이 숨겨져 있다고 해. 설명을 위해서 다시 한번 IMAGE_IMPORT_DESCRIPTOR 구조체를 살펴볼게.
여기에 UPack의 트릭이 숨겨져 있다고 해. 설명을 위해서 다시 한번 IMAGE_IMPORT_DESCRIPTOR 구조체를 살펴볼게.
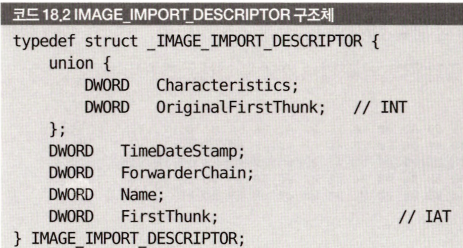
Import Table은 이런 구조체들이 주욱 이어진 배열이고 그 다음에 null로 끝나야 한다.
이거 다시 보면은 드래그한 부분은 첫번째 구조체가 맞거든? 근데 그 다음은 이상하다. null도 아니고, 그렇다고 두번째 구조체라 하기에도 형식에 안 맞아.
설명한다.
아까도 봤지만 offset 200은 세번째 섹션의 끝이지. 근데 그럼 offset 200부터는 메모리에 매핑되면 안되겠지? 그래서 아예 무시된다.
즉 오프셋 0부터 1EF까지는 메모리 27000~271EF에 매핑되고 그 밑에 오프셋부분은 무시되고 271EF부터 28000까지는 그냥 null로 다 채워진다 이거다. 그럼 메모리에서는 결국 PE의 스펙 형식에 어긋나게 되는 것이 아닌거지.
이게 굉장한 트릭이라고 한다. PE 툴들이 import table을 읽는데 메모리 참조 에러에 걸린다고 한다.
IAT (Import Address TABLE)
어떤 DLL에서 어떤 API를 임포트하는지 알려면 IAT를 봐야한다고 배웠다. 자 저 구조체대로 읽어볼게.
1EE는 Original First Thunk(INT)의 RVA야. 0이라고 되어있네.
1FA는 Name의 RVA야. 2라고 되어있네.
1FE는 First Thunk (IAT)의 RVA야.11E8이라고 되어있네.
Name 살펴보기
RVA가 2인데 그럼 Header 영역이네.
offset으로 바꿔도 2네. Offset 2로 가보자. 역시 이 주소에는 어떤 dll을 import하는지 그 이름 문자열이 담겨있다.
역시 이 주소에는 어떤 dll을 import하는지 그 이름 문자열이 담겨있다.
원래 Dos 헤더의 안 쓰는 공간을 이렇게 살뜰하게 잘 쓴거다.
DLL이 어떤 API를 임포트하는지 보자.
IAT 살펴보기
원래는 INT, 즉 Original First Thunk를 쫓으면 API 이름 문자열이 나오는데 UPack에선 INT가 0이라서 IAT (First Thunk)를 따라간다. INT나 IAT나 둘중 하나에서 API 이름 문자열을 얻으면 되는거 아니겠어?
IAT의 RVA 1128은 첫번째 섹션 영역이니까 RAW로 바꾼다. Pointer to Raw 0으로 강제 변환되는거 잊지말고.
11E8 - 1000 + 0 = offset 1E8
 지금 여기는 IAT이면서 INT 역할도 겸하고 있다 여기 적힌게 뭐냐면 어떤 API 임포트하는지 이름 문자열이 적힌 주소야.
지금 여기는 IAT이면서 INT 역할도 겸하고 있다 여기 적힌게 뭐냐면 어떤 API 임포트하는지 이름 문자열이 적힌 주소야.
첫번째는 00 00 00 28
두번째는 00 00 00 BE
세번째는 그냥 Null 값이다.
rva 28이나 rva be나 전부 헤더영역이니까 raw 계산하면 그냥 raw 28이고 raw be다.
 오프셋 28가보니까 LoadLibraryA() API가 나오네.
오프셋 28가보니까 LoadLibraryA() API가 나오네. 오프셋 BE가니까 GetProcAddress() API가 나오네.
오프셋 BE가니까 GetProcAddress() API가 나오네.
즉 이렇게 UPack이 임포트하는 api를 알수 있다. 이 함수는 모두 원본 notepad.exe의 IAT를 구성할 때 편리해서 일반 패커이든 악성패커든 많이 임포트해서 사용하는 것이다.
UPack 디버깅 - OEP 탐색
디버깅해야 하는데 upack으로 실행압축된 notepad는 x96dbg에 안 올라가는데...?
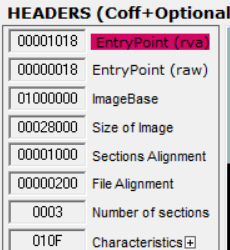 그래도 할 수 있는건 해야지. 지금 EP의 RVA가 1018이다. imagebase가 1000000이니까 1001018 메모리 주소로 가봐야 한다.
그래도 할 수 있는건 해야지. 지금 EP의 RVA가 1018이다. imagebase가 1000000이니까 1001018 메모리 주소로 가봐야 한다.
근데 내 디버거는 안되는데.
이런 upack으로 실행압축된 파일을 디버깅할 때 해당 주소로 EIP를 설정하는게 안될 수도 있다. 그러면 강제로 EIP를 변경하는 명령을 해야 한다고 한다.
지난번에 실행압축된 파일에서 oep 찾으려고 할 때 디버깅으로 실행하면 루프를 많이 만나서 그 루프 막 자동으로 계속 실행하고 적절히 건너뛰고 그랬어야 한다.
디버깅 시작
암튼 1001018로 가보자. 여기선 책의 ollydbg로 했던 캡쳐화면을 쓸 수 밖에. 드래그된 부분 위의 두개의 명령어부터 말해볼게.
드래그된 부분 위의 두개의 명령어부터 말해볼게.
10011B0 주소를 ESI에 복제해. 그리고 이 주소에서 적힌 값 ([esi]를 읽으라고 했으니까) 4바이트를 읽어놔.
그리고 드래그한 부분이 그 4바이트를 EAX에 저장하라는 것이다.
그 EAX를 stack에 푸시한 결과가 100739D 주소인데 이게 원본 notepad.exe의 Original Entry Point 주소이다.
그래서 여기에 하드웨어 BP를 설치해서 실행하면 OEP에서 멈춘다.
그치만 학습을 위해 더 진행.
계속 실행을 반복하다보면 함수 호출 코드를 만난다고 한다.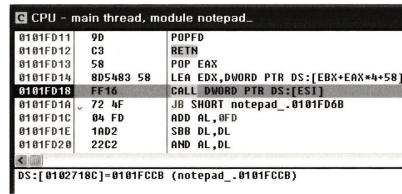
ESI에 적힌 주소로 이동하래. ESI에 이때 값은 101FCCB이다. 이게 압축된 파일을 디코딩하는 decode() 함수 주소다.
이 decode() 함수를 좀 살펴볼 필요가 있대.
101FCCB로 가봐.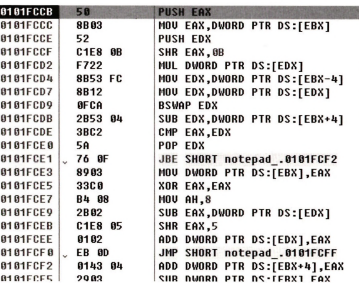 여기서 쭉 이동해봐.
여기서 쭉 이동해봐.
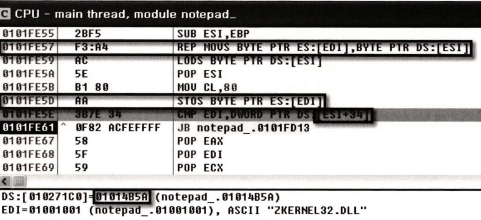 긴 주소를 다 적으면서 설명하면 힘드니까 끝에 두 자리만 써서 설명할게
긴 주소를 다 적으면서 설명하면 힘드니까 끝에 두 자리만 써서 설명할게
57, 5D : EDI 값이 가리키는 곳에 가서 뭔가를 적어. 여기서 EDI 값은 첫번째 섹션 내의 주소를 가리켜.
우리는 두번째 섹션에 압축파일을 풀어서 첫번째 섹션에 풀어놓을 것이란 걸 전에 말해서 알지?
5E, 61 : CMP나 JP 명령어로 EDI 값이 [ESI+34]가 될 때까지 루프를 돌려.
여기서 [ESI+34]는 1014B5A야.
IAT 세팅
디코딩 루프가 끝나면 원본 파일에 맞는 IAT를 새로 구성해줘야 한다. 이건 일반 패커도 그렇고 Upack도 그래.
위에서 UPack이 LoadLibraryA랑 GetProcAddress를 import 하던거 알지. 그 api를 이용해서 뭐하는거냐면 루프를 돌면서 원본 notepad.exe가 임포트하는 함수들의 실제 메모리 주소를 얻어서 원본 IAT 영역에 값을 채우는거다.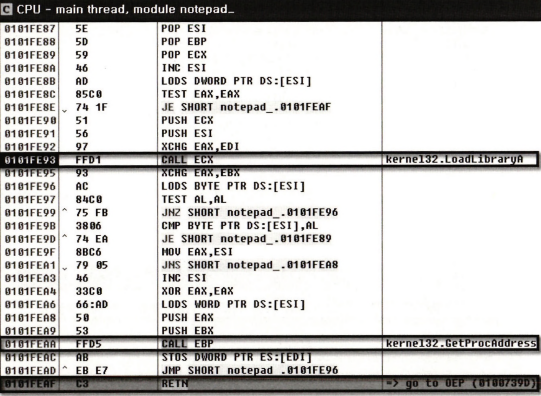 그게 이거래. 근데 여기까지 도달하는 건 그냥 트레이싱을 계속하면 나오는 걸까?
그게 이거래. 근데 여기까지 도달하는 건 그냥 트레이싱을 계속하면 나오는 걸까?
암튼 루프를 돌면서 원본 IAT를 다 채우면 마지막에 RETN 명령어로 OEP로 이동하는 거다.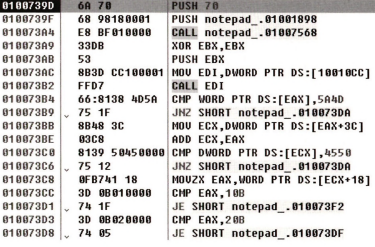 이게 원본 OEP야...
이게 원본 OEP야...
