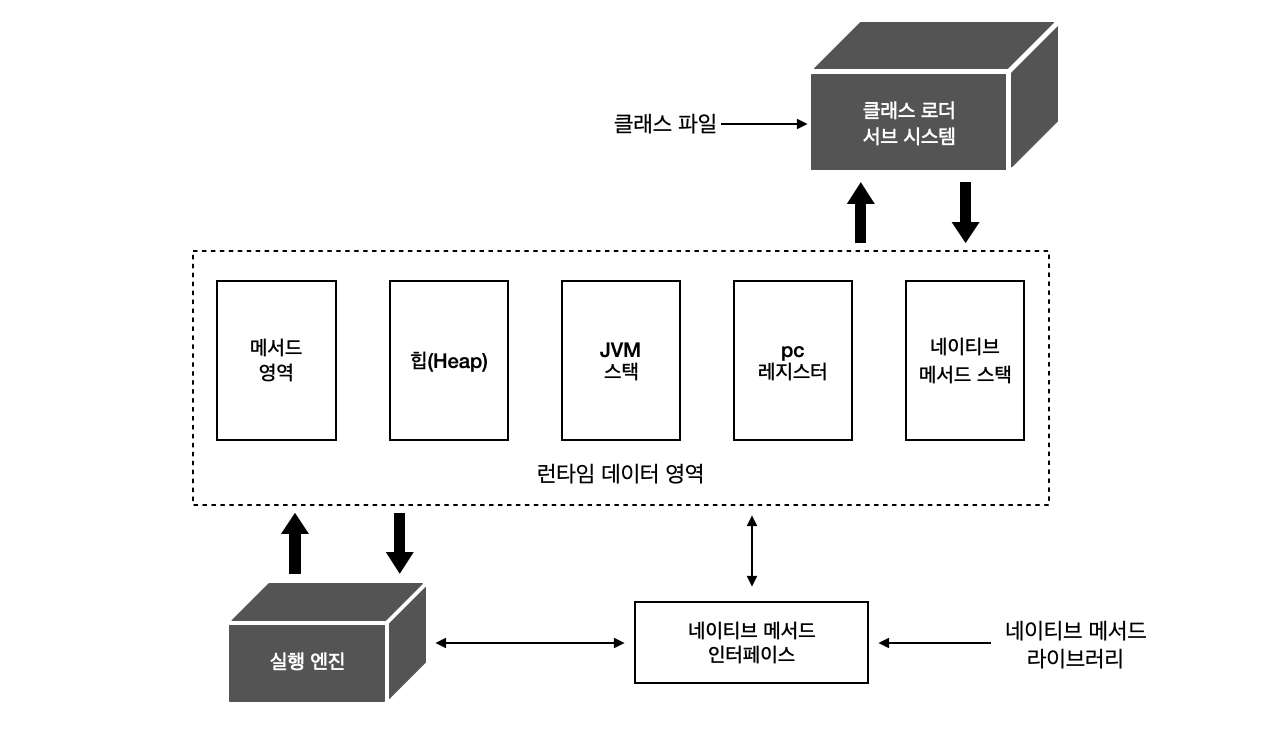
자바의 Runtime Data Area 구성
자바에서 사용하는 메모리 영역은 다음과 같다.
- PC 레지스터
- JVM 스택
- 힙 (HEAP)
- 메서드 영역
- 런타임 상수 (constant) 풀
- 네이티브 메서드 스택
이 영역중에서 GC 가 발생하는 부분은 힙 영역이다. 바꿔 말하면 나머지 영역은 GC 영역이 아니라는 것이다.
1) Heap 메모리
클래스 인스턴스, 배열이 이 메모리에 쌓인다. 이 메모리는 '공유 메모리' 라고도 불리며 여러 쓰레드에서 공유하는 데이터들이 저장되는 메모리다.
2) Non-Heap 메모리
이 메모리는 자바의 내부 처리를 위해 필요한 영역이다. 여기서 주된 영역이 바로 메서드 영역이다.
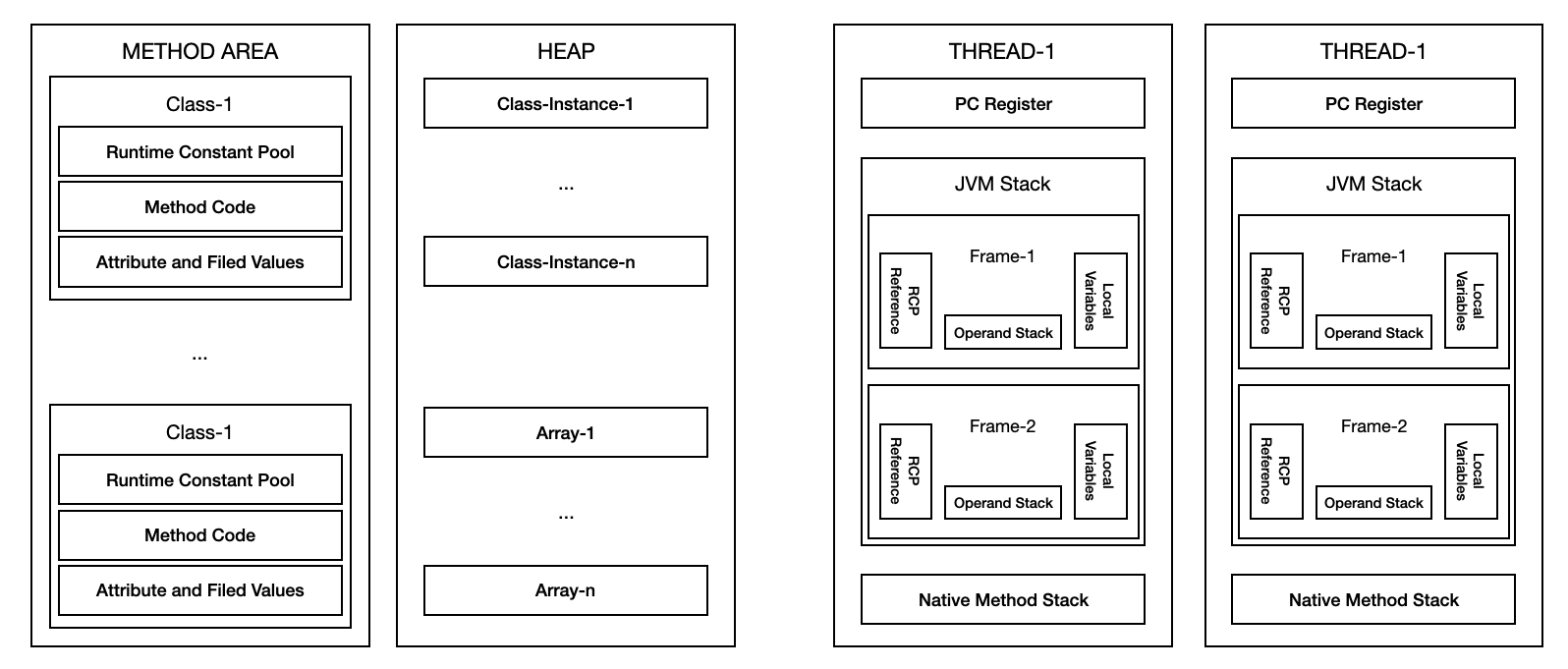
메서드 영역
메서드 영역은 모든 JVM 쓰레드에서 공유한다. 이 영역에 저장되는 데이터들은 다음과 같다.
-
런타임 상수 풀: 자바의 클래스 파일에는 constant_pool 이라는 정보가 포함되어 있다. 이에 대한 정보를 실행시에 참조하기 위한 영역이다. 실제 상수값도 포함될 수 있지만, 실행시에 변하게 되는 필드 참조 정보도 포함된다.
-
필드 정보에는 메서드 데이터, 메서드와 생성자 코드가 있다.
JVM 스택
쓰레드가 시작할 때 JVM 스택이 생성된다. 이 스택에는 메서드가 호출되는 정보인 프레임이 저장된다. 그리고 지역 변수와 임시 결과 메서드 수행과 리턴에 관련된 정보들도 포함된다.
네이티브 메서드 스택
자바 코드가 아닌 다른 언어로 된(보통은 C) 코드들이 실행하게 될 때의 메서드 스택 정보를 관리한다.
PC 레지스터
자바의 쓰레드들은 각자의 pc(program counter) 레지스터를 갖는다. 네이티브한 코드를 제외한 모든 자바 코드들이 수행될 때 JVM 인스터럭션 주소를 pc 레지스터에 보관한다.
GC 의 원리
GC 작업을 하는 가비지 콜렉터(Garbage Collector) 는 다음의 역할을 한다.
- 메모리 할당
- 사용중인 메모리 인식
- 사용하지 않는 메모리 인식
사용하지 않는 메모리를 인식하는 작업을 수행하지 않으면, 할당한 메모리 영역이 꽉차서 Hang에 걸리거나, 더 많은 메모리를 할당하려는 현상이 발생할 것이다. 만약 JVM 의 최대 메모리 크기를 지정해서 전부 사용한 다음 GC 를 해도 더 이상 사용 가능한 메모리 영역이 없는데 계속 메모리를 할당하려고 하면 OutOfMemoryError 가 발생하여 JVM 이 다운될 수 있다.
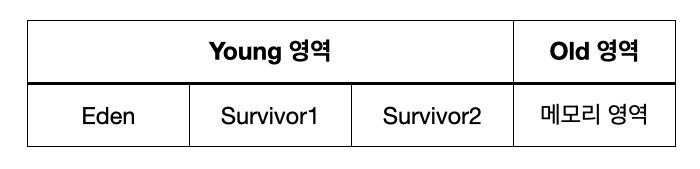
힙 영역은 Young 영역과 Old 영역 일부가 남는다. Young 영역은 다시 Eden 영역 및 두 개의 Survivor 영역으로 나뉘므로 우리가 고려해야 할 자바 메모리 영역은 총 4개 영역으로 나뉜다고 볼 수 있다.
- Perm 영역도 있으나 이는 JDK8 부터는 사라졌다.
-
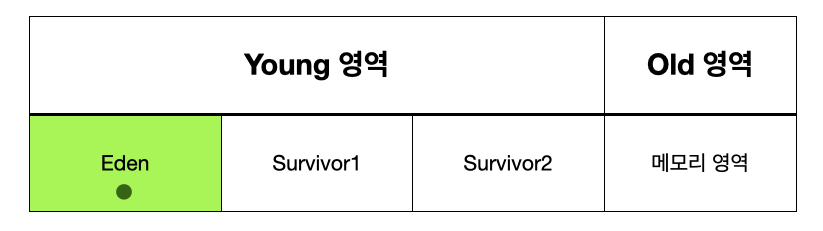
객체 생성
일당 메모리에 객체가 생성되면, 아래 그림의 가장 왼쪽인 Eden 영역에 객체가 지정된다.
-
Eden 영역에 데이터가 꽉차는 경우
Eden 영역에 데이터가 꽉 차면, 이 영역에 있던 객체가 어디론가 옮겨지거나 삭제되야 한다. 이때 옮겨지는 위치가 Survivor 영역이다. 위의 그림에서는 구분을 하기 위해 1과 2로 나눈 것이며, 우선순위가 있는것은 아니다. 이 두 개의 영역 중 한 영역은 반드시 비어있어야 한다. 그 비어있는 영역에 Eden 영역에 있던 객체 중에 GC 후에 살아남은 객체들이 이동한다.
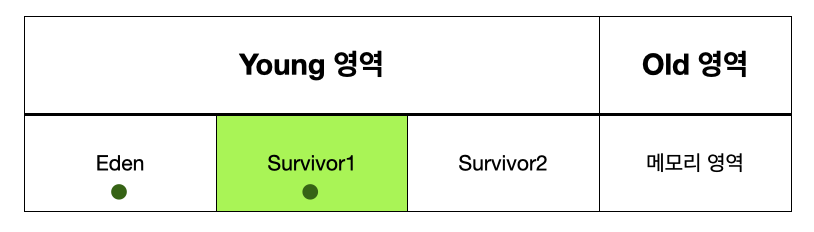
혹은 다음과 같이 할당된다.
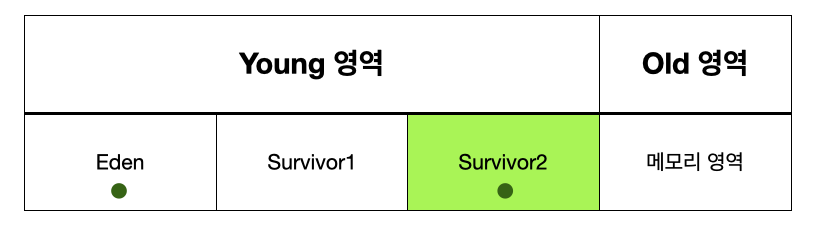
- Survivor 영역이 다 차는 경우
Survivor 영역이 차면 GC 가 되면서 Eden 영역에 있는 객체와 꽉 찬 Survivor 영역에 있는 객체가 비어있는 Survivor 영역으로 이동한다. 이런 작업을 반복하면서 Survovir 영역을 왔다갔다 하던 객체는 Old 영역으로 이동한다.
Young 영역에서 Old 영역으로 넘어가는 객체 중 바로 Old 영역으로 이동하는 객체가 있을 수 있다. 객체의 크기가 아주 큰 경우인데, 예를 들어 Survivor 영역의 크기가 16MB 인데 20MB 를 점유하는 객체라면 바로 Old 영역으로 이동하게 된다.
GC의 종류
GC는 크게 두 가지 타입으로 나뉜다. 마이너 GC 와 메이저 GC 의 두가지 GC가 발생할 수 있다.
- 마이너 GC: Young 영역에서 발생하는 GC
- 메이저 GC: Old 영역이나 Perm 영역에서 발생하는 GC
이 두가지 GC 가 어떻게 상호작용 하느냐에 따라 GC 방식에 차이가 나며, 성능에도 영향을 준다.
JDK7 이상에서 지원하는 GC 방식에는 다섯 가지가 있다.
1. Serial Collector: 시리얼 콜렉터
2. Parallel Collector: 병렬 콜렉터
3. Parallel Compacting Collector: 병렬 콜렉팅 콜렉터
4. Concurrent Mark-Sweep (CMS) Collector: CMS 콜렉터
5. Garbage First Collector: G1 콜렉터
1) 시리얼 콜렉터
Young 영역과 Old 영역이 시리얼하게(연속적으로) 처리되며 하나의 CPU를 사용한다. Sun 에서는 이 처리를 수행할 때 이를 Stop-the-world 라고 표현한다. 다시 말하면 콜렉션이 수행될 때 애플리케이션 수행이 정지된다.
해당 콜렉터는 일반적으로 클라이언트 종류의 장비에서 많이 사용된다. 다시 말하면, 대기 시간이 많아도 크게 문제되지 않는 시스템에서 사용된다는 의미다.
기본적인 수행 과정은 다음과 같다.
1. 일단 살아있는 객체들은 Eden 영역에 있다.
2. Eden 영역이 꽉차게 되면 To Survivor 영역으로 살아 있는 객체들이 이동한다. 이때 Survivor 영역에 들어가기 너무 큰 객체는 바로 Old 영역으로 이동한다. 그리고 From Survivor 영역에 살아있는 객체는 To Survivor 영역으로 이동한다.
3. To Survivor 영역이 꽉 찼을 경우, Eden 영역이나 From Survivor 영역에 남아 있는 객체들은 Old 영역으로 이동한다.
- Young 영역의 시리얼 콜렉션

- 시리얼 콜렉션 이후 Young 영역의 상태

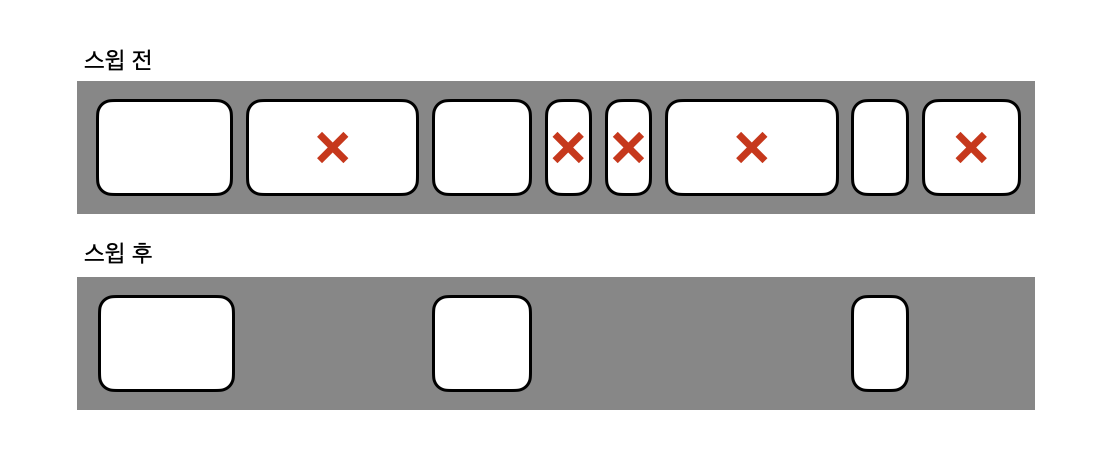
이후에 Old 영역에 있는 객체들은 Mark-Sweep-Compact 콜렉션 알고리즘을 따른다. 간단히 말하면 쓰이지 않는 객체를 표시하고 삭제하고 한 곳으로 모으는 알고리즘이다. 해당 알고리즘 수행은 다음과 같다.
1. Old 영역으로 이동된 객체들 중 살아있는 객체를 식별한다. (표시 단계)
2. Old 영역의 객체들을 훑는 작업을 수행하며 쓰레기 객체를 식별한다. (스윕 단계)
3. 필요 없는 객체들을 지우고 살아 있는 객체들을 한 곳으로 모은다. (컴팩션 단계)
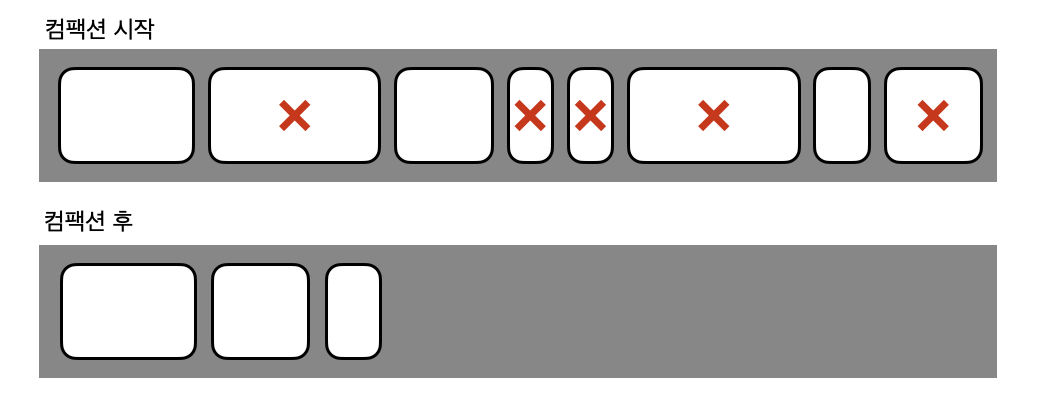
2) 병렬 콜렉터
이 방식은 스루풋(throughput collector) 로도 알려진 방식이다. 이 방식의 목표는 다른 CPU가 대기 상태로 남아 있는 것을 최소화 하는 방식이다.
시리얼 콜렉터와 달리 Young 영역에서의 콜렉션을 병렬(Parallel)로 처리한다. 많은 CPU 를 사용하기 때문에 GC의 부하를 줄이고 애플리케이션의 처리량을 증가시킬 수 있다. Old 영역은 시리얼 콜렉터와 마찬가지로 Mark-Sweep-Compack 콜렉션 알고리즘을 사용한다.

3) 병렬 콤팩팅 콜렉터
병렬 콜렉터와 다른 점은 Old 영역 GC에서 새로운 알고리즘을 사용한다느 ㄴ것이다. 그러므로 Young 영역에 대한 GC는 병렬 콜렉터와 동일하지만, Old 영역의 GC 는 다음의 3단계를 거친다.
1. 표시 단계: 살아 있는 객체를 식별하여 표시하는 단계
2. 종합 단계: 이전 GC 를 수행하여 컴팩션 된 영역에 살아있는 객체의 위치를 조사하는 단계
3. 컴팩션 단계: 컴팩션을 수행하는 단계. 수행 이후에는 컴팩션 영역과 비어있는 영역으로 나뉜다.
병렬 콜렉터와 동일하게 이 방식도 여러 CPU 를 사용하는 서버에 적합하다.
GC 를 사용하는 쓰레드 개수는 -XX:ParallelGCThreads=n 옵션으로 조정할 수 있다.
4) CMS 콜렉터
이 방식은 로우 레이턴시 콜렉터(low-latency collector) 로도 알려져 있으며, 힙 메모리 영역의 크기가 클 때 적합하다. Young 영역에 대한 GC 는 병렬 콜렉터와 동일하다. Old 영역의 GC는 다음 단계를 거친다.
1. 초기 표시 단계: 매우 짧은 대기 시간으로 살아 있는 객체를 찾는 단계
2. Concurrent 표시 단계: 서버 수행과 동시에 살아 있는 객체에 표시를 해놓는 단계
3. 재표시 단계: Concurrent 표시 단계에서 표시하는 동안 변경된 객체에 대해서 다시 표시하는 단계
4. Concurrent 스윕 단계: 표시되어 있는 객체를 정리하는 단계
CMS는 컴팩션 단계를 수행하지 않기 때문에 메모리를 몰아넣는 작업을 하지 않는다.
-XX:CMSInitiatingOccupancyFraction=n 옵션을 사용하여 Old 영역의 % 를 n 값에 지정한다. 여기서 n 의 기본값은 68이다.
- CMS 콜렉터
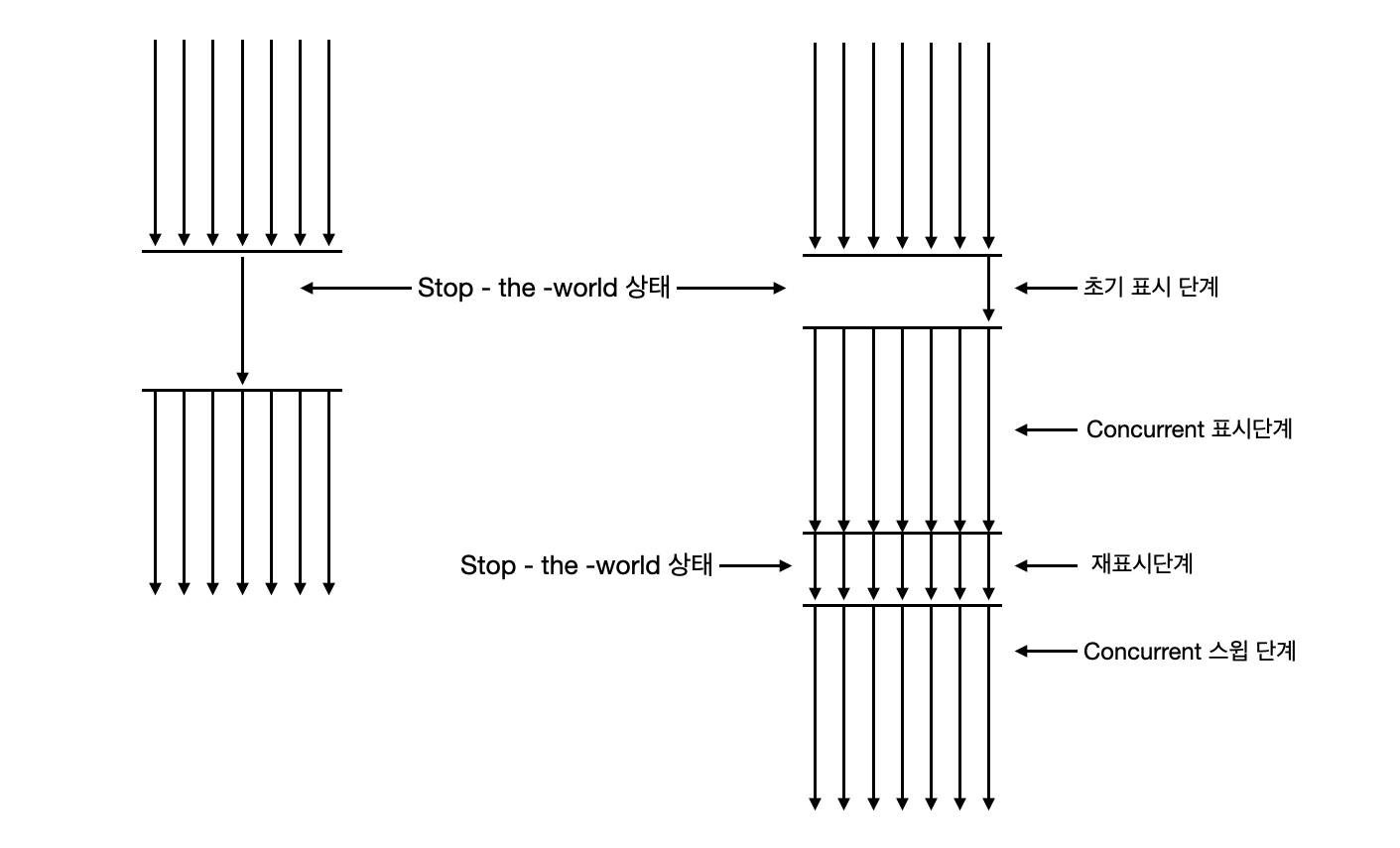
- GC 이후의 CMS 콜렉터
이 방식은 2개 이상의 프로세서를 사용하는 서버에 적당하다. 적당한 대상으로는 웹 서버가 있다.
CMS 콜렉터는 추가적인 오션으로 점진적 방식을 지원한다. 이 방식은 Young 영역의 GC 를 더 잘게 쪼개어 서버의 대기 시간을 줄일 수 있다. CPU 가 많지 않고 시스템의 대기 시간이 짧아야 할 때 사용하면 좋다.
점진적인 GC 를 사용하려면 -XX:+CMSIncrementalMode 옵션을 지정하면 된다. 하지만 이 옵션을 지정할 경우 예기치 못한 성능 저하가 발생할 수 있으므로 충분한 테스트 후 운영에 반영해야 한다.
5) G1 콜렉터

G1은 위와 같이 되어있다. 편하게 생각하면 바둑판 모양이다. 여기서 각 바둑판의 사각형을 region 이라고 하는데 Young 영역이나 Old 영역이라는 단어와 구분하기 위해 한국말로 '구역' 이라고 하자 (이 구역의 기본 크기는 1MB 이며 최대 32MB 까지 지정 가능)
위에서 보듯 Young과 Old 구역이 물리적으로 나뉘어 있지 않고, 각 구역의 크기는 모두 동일하다. 이 바둑판 모양의 구역이 각각 Eden, Survivor, Old 영역의 역할을 변경해가면서 수행하고 Humongous 라는 영역도 포함된다.
G1 의 Young GC는 다음과 같다.
1. 몇 개의 구역을 선정하여 Young 영역으로 지정한다.
2. 이 구역에 객체가 생성되면서 데이터가 쌓인다.
3. Young 영역으로 할당된 구역에서 데이터가 꽉차면 GC를 수행한다.
4. GC를 수행하면서 살아있는 객체들만 Survivor 구역으로 이동시킨다.
이렇게 살아남은 객체들이 이동된 구역은 새로운 Survivor 영역이 된다. 그 다음에 Young GC가 발생하면 Survivor 영역에 계속 쌓는다. 그러면서 멏 번의 aging 작업을 통해서 Old 영역으로 승격된다.
G1의 Old 영역 GC는 CMS GC 의 방식과 비슷하며 아래 여섯 단계로 나뉜다. 여기서 SWT 라고 표시된 단계는 모두 Stop-The-World 가 발생한다.
1. 초기 표시 단계 (STW): Old 영역에 있는 객체에서 Survivor 영역의 객체를 참조하고 있는 객체들을 표시한다.
2. 기본 구역 스캔 단계: Old 영역 참조를 위해서 Survivor 영역을 훑는다. 참고로 이 작업은 Young GC 발생 이전에 수행된다.
3. 컨커런트 표시 단계: 전체 힙 영역에 살아있는 객체를 찾는다. 만약 이때 Young GC 가 발생하면 잠시 멈춘다.
4. 재표시 단계 (STW): 힙에 살이있는 객체들의 표시 작업을 완려한다. 이때 snapshot-at-the-beginning(SATB) 라는 알고리즘을 사용하며, 이는 CMS GC 에서 사용하는 방식보다 빠르다.
5. 청소 단계 (STW): 살아 있는 객체와 비어있는 구역을 식별하고, 필요없는 객체들을 지운다. 그리고나서 비어있는 구역을 초기화 한다.
6. 복사 단계 (STW): 살아있는 객체들을 비어있는 구역으로 모은다.
