역할
- Topic의 Partition으로부터 데이터 polling (데이터를 가져가는 주체)
- Partition offset(파티션 데이터의 번호) 위치를 기록(commit)
- Consumer Group을 통해 병렬 처리
- 각 Consumer Group은 다른 Consumer 그룹에게 영향을 끼치지 못한다.
코드에서 살펴보기
1) 의존성 추가
implementation group: 'org.apache.kafka', name: 'kafka-clients', version: '3.1.0'2) 코드 작성
public class Consumer {
public static void main(String[] args) {
Properties configs = new Properties();
configs.put("bootstrap.servers", "localhost:9092");
configs.put("group.id", "click_log_group");
configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
configs.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
//어느 토픽에서 데이터를 가져올지 결정한다.
consumer.subscribe(Array.asList("click_log"));
//데이터를 실질적으로 가져오는 폴링 루프: poll 메서드가 포함된 무한 루프
while(true) {
ConsumerRecords<String, String> records = consumer.poll(500);
for(ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}
}
}- 특정 파티션에서만 데이터를 가져오는 경우
public class Consumer {
public static void main(String[] args) {
Properties configs = new Properties();
configs.put("bootstrap.servers", "localhost:9092");
configs.put("group.id", "click_log_group");
configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
configs.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
//어느 토픽에서 데이터를 가져올지 결정한다.
consumer.subscribe(Array.asList("click_log"));
// === 추가된 코드 === //
TopicPartition partition0 = new TopicPartition(topicName, 0);
TopicPartition partition1 = new TopicPartition(topicName, 1);
consumer.assign(Arrays.asList(partition0, partition1));
//데이터를 실질적으로 가져오는 폴링 루프: poll 메서드가 포함된 무한 루프
while(true) {
ConsumerRecords<String, String> records = consumer.poll(500);
for(ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}
}
}이미지로 살펴보기
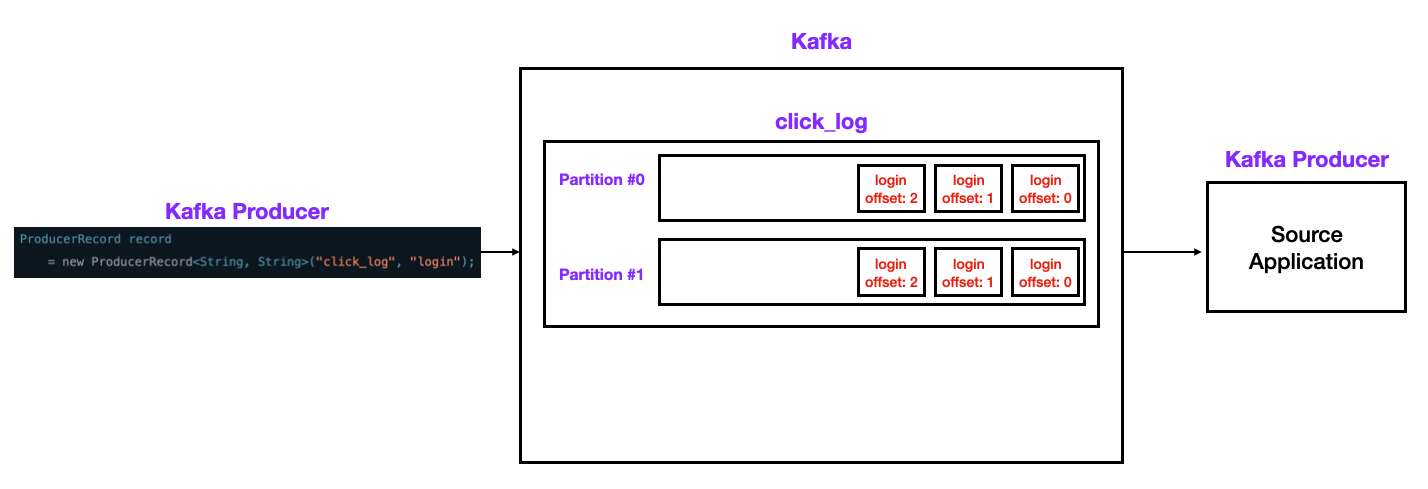
1) OffsetNumber
- 각 Topic 별, Partition별로 Offset이 존재한다.
- offset 정보는 카프카의
__consumer_offsets토픽에 저장된다. - 작업이 외부 요인으로 중단되어도 작업을 수행하기 위한 위치를 offset으로 기억하고 있기 때문에 이슈가 발생해도 다음 작업을 이어서 수행할 수 있다.
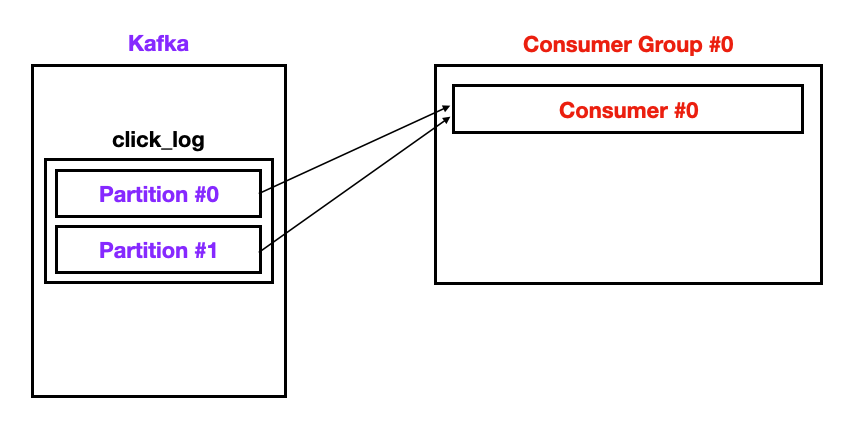
2) Multiple Consumer
- 컨슈머가 1개인 경우
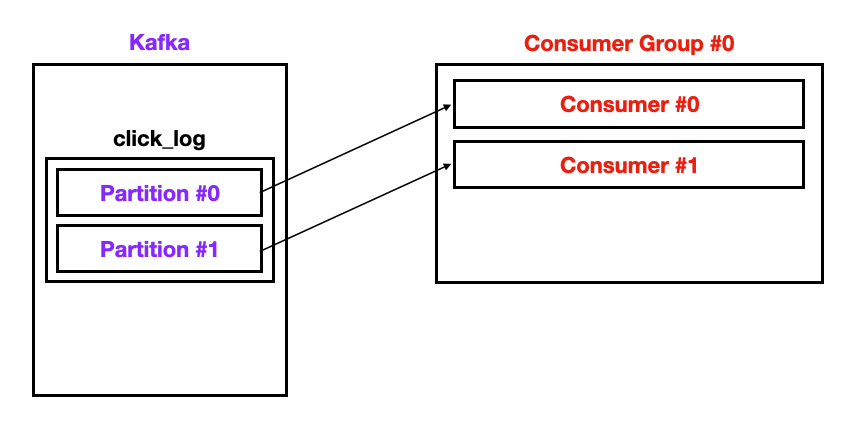
- 컨슈머가 2개인 경우
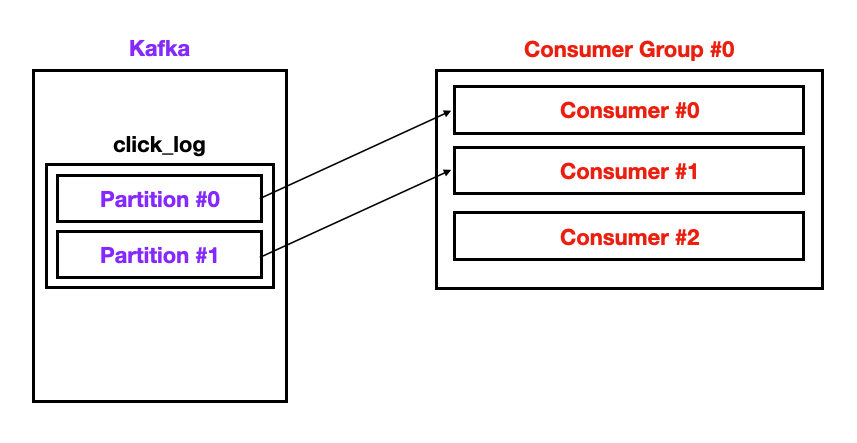
- 컨슈머가 3개인 경우
Consumer Commit
1) 오토 커밋
enable.auto.commit = true
- 일정 간격(
auto.commit.interval.ms), poll() 메서드 호출시 자동 commit - commit 관련 코드를 작성할 필요가 없다. → 편리함
- 속도가 가장 빠르다.
- 중복 또는 유실이 발생할 수 있다.
→ 중복 / 유실을 허용하지 않는 곳(은행 / 카드 등) 에서는 사용하면 안된다.
→ 일부 데이터가 중복 / 유실 되도 상관없는 곳(센서, GPS 등)에서 사용
2) 데이터 중복을 막을 수 있는 방법
오토 커밋을 사용하지 않는다. Kafka Consumer의 commitSync(), commitAsync() 사용
enable.auto.commit = false
-
commitSync(): 동기 커밋- ConsumerRecord 처리 순서를 보장한다.
- 가장 느림(커밋이 완료될 때 까지 block)
- poll() 메서드로 변환된 ConsumerRecord 의 마지막 offset을 커밋
- Map<TopicPartition, OffsetAndMetadata>을 통해 오프셋 지정 커밋 가능
-
commitAsync(): 비동기 커밋- 동기 커밋보다 빠르다.
- 중복이 발생할 수 있다: 일시적인 통신 문제로 이전 offset 보다 이후 offset이 먼저 커밋될 때
- ConsumerRecord 처리 순서를 보장하지 못한다.
Consumer Rebalance
리밸런스: 컨슈머 그룹의 파티션 소유권이 변경될 때 일어나는 현상
-
리밸런스를 하는 동안 일시적으로 메시지를 가져올 수 없다.
-
리밸런스 발생히 데이터 유실 / 중복 발생 가능성이 있다.
→commitSync()또는 추가적인 방법으로 데이터 유실 / 중복 방지 -
언제 리밸런스가 발생하는가?
→consumer.close()호출시 또는 consumer 세선이 끊어졌을 때
