카프카의 역할
1) Before Kafka
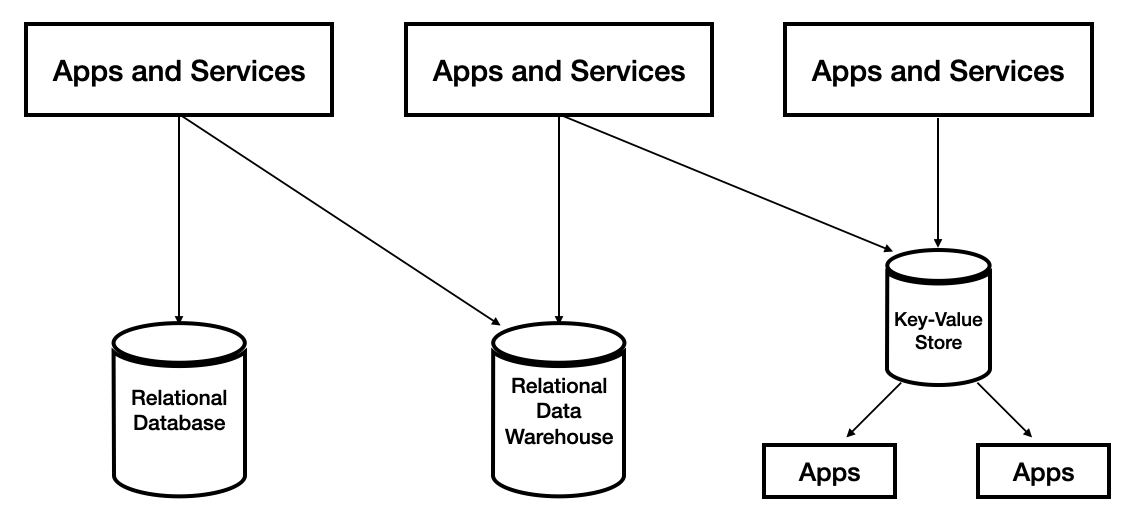
- 소스 애플리케이션과 타켓 애플리케이션이 데이터를 전송하는 라인이 매우 복잡해졌다.
- 데이터 전송 라인이 많아지면 배포와 장애에 대응하기 어렵다.
- 데이터 전송에 대한 프로토콜의 파편화가 심하다.
2) After Kafka
- LinkedIn 에서 개발하였다.
- OpenSource이다.
카프카의 특징
1) 역할
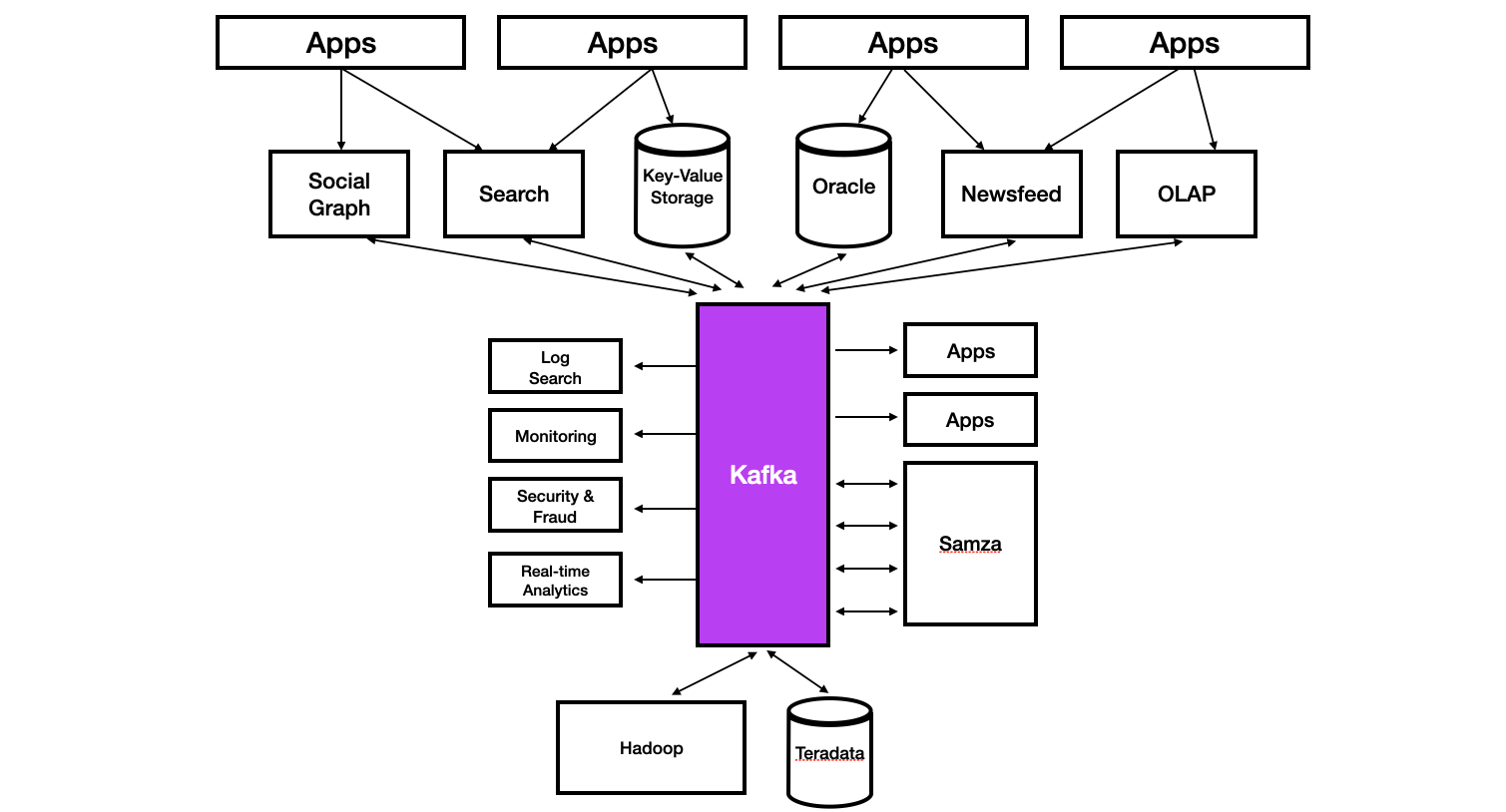
- Source Application과 Target Application 사이의 coupling 을 약하게 한다.
- 고가용성: 서버가 갑작스럽게 이슈가 생기거나, 전원이 내려가도 데이터를 손실없이 보구할 수 있다.
- 맞은 지연과 높은 처리량: 빅데이터 처리에 용이하다.
Topic
1) 개념
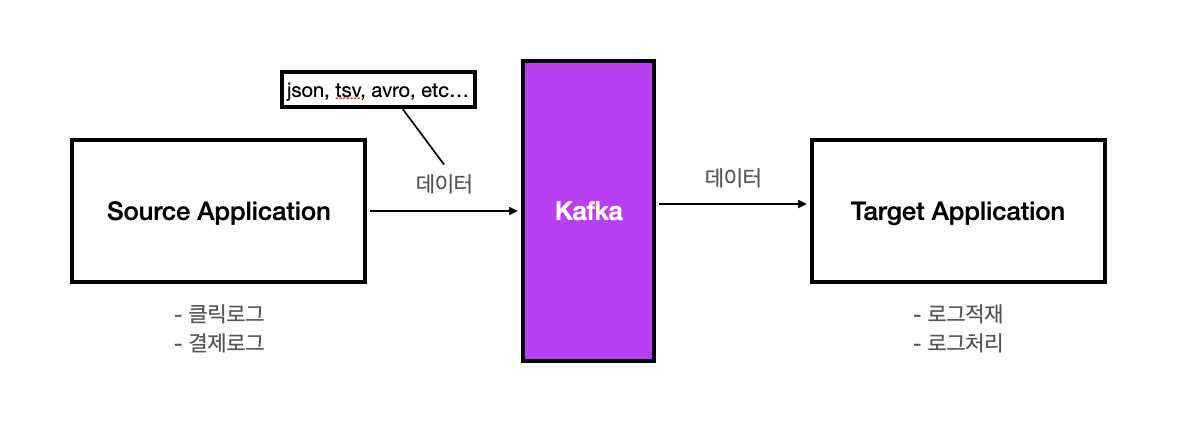
- 카프카 내부에서 데이터를 보관하는 컨테이너로 일종의 큐(Queue)라고 볼 수 있다.
- 일반적인 AMQP와는 다르게 동작한다.
- DB 의 테이블이나 파일 시스템의 폴더와 유사한 성질을 가지고 있다.
2) 특징
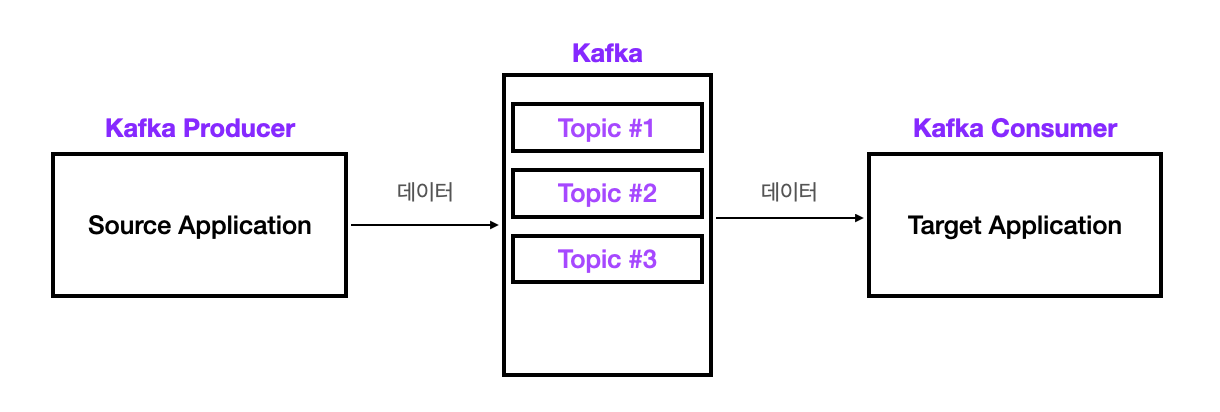
1. 목적에 따라 이름을 가질 수 있다.
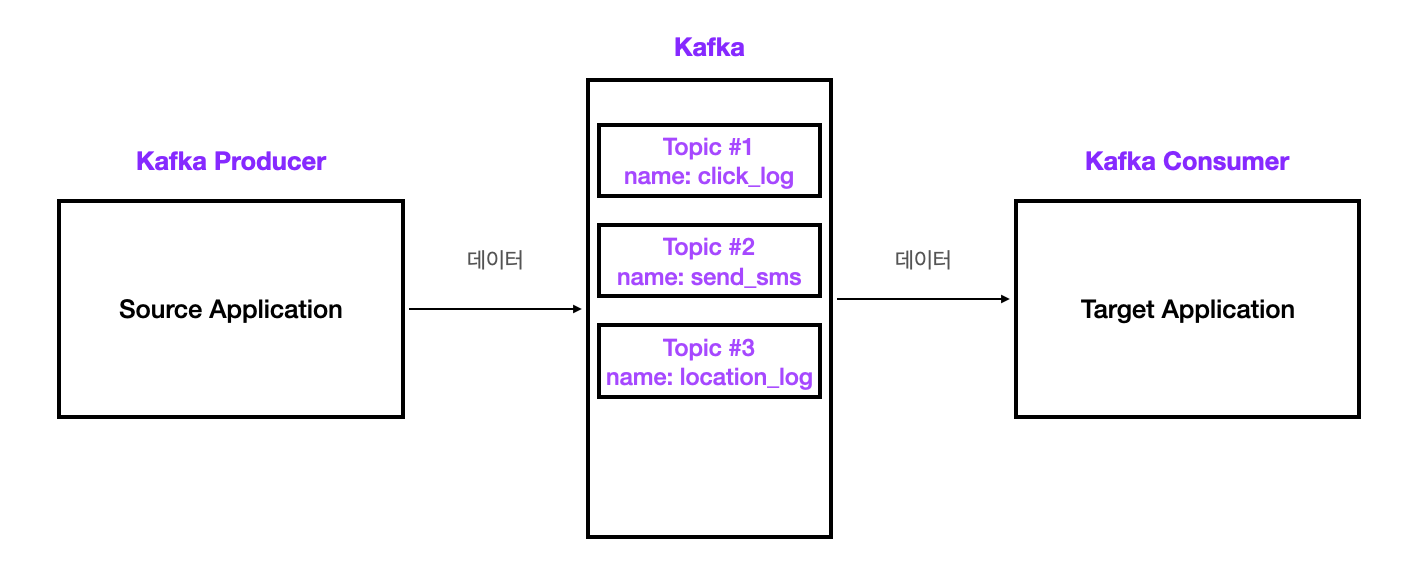
2. 토픽의 내부에는 파티션이 있다.
- 토픽의 내부에는 실질적인 데이터가 위치하는 파티션이 있다.
- 데이터의 큐와 마찬가지로 FIFO 구조로 적재된다.
- Consumer가 데이터를 가져가도 데이터는 삭제되지 않는다.
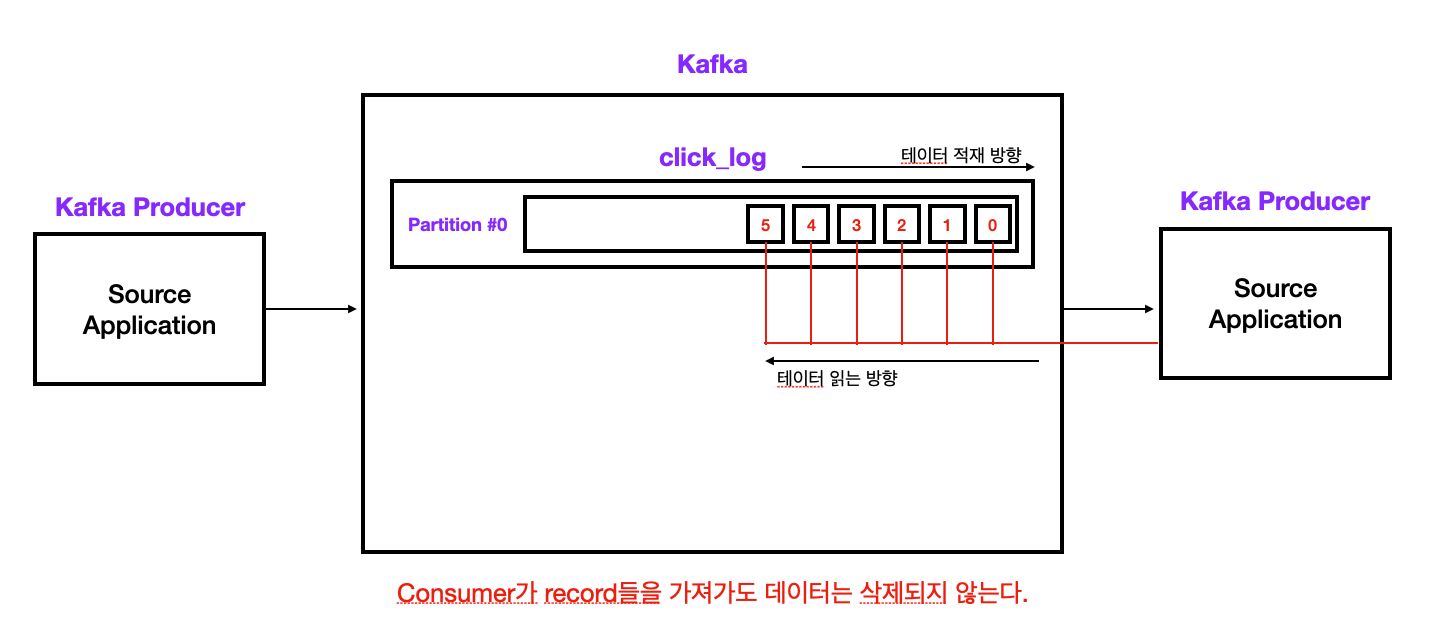
Consumer가 데이터를 가져가도 데이터가 삭제되지 않기 때문에 다른 Consumer가 붙어도 여전히 데이터에 접근할 수 있다. 다만 아래와 같은 조건이 붙는다.
1. 컨슈머 그룹이 달라야 한다.
2. auto.offset.reset = earliest
3. 파티션이 두 개인 경우
-
키가 null이고, 기본 파티셔너를 사용할 경우: 라운드 로빈(Round-Robin)으로 각 파티션별로 번갈아가며 순차적으로 데이터를 적재한다. (아래 이미지)
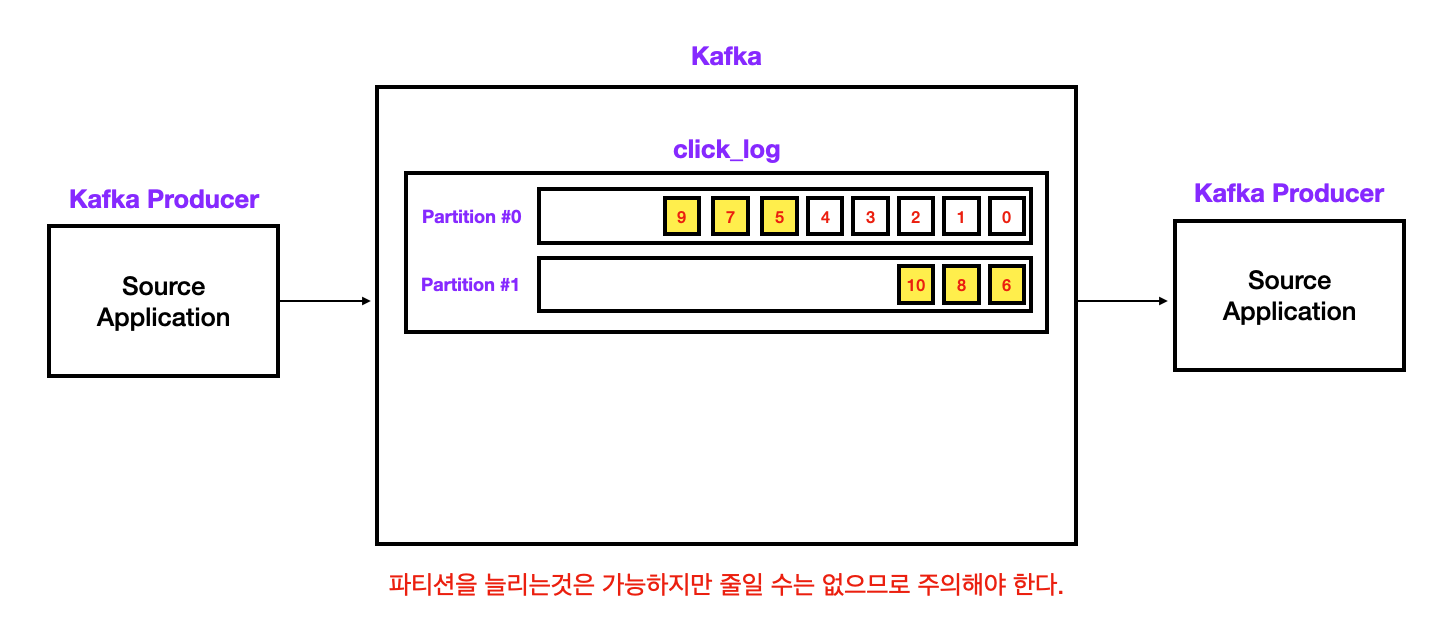
-
키가 있고, 기본 파티셔너를 사용할 경우: 키의 해시값을 구하고, 특정 파티션에 할당한다.
4. 파티션 데이터의 삭제
레코드가 삭제되는 시간과 크기를 옵션으로 설정하여 데이터를 삭제할 수 있다.
log.retention.ms: 최대 record 보존 시간log.retention.byte: 최대 record 보존 크기(byte)
Kafka Broker
- 카프가가 설치되어 있는 서버의 단위를 말한다.
- 보통 3개 이상의 브로커로 구성하여 사용하는 것을 권장한다.
Kafka Replication
- 원본 파티션: Leader Partition
- 복제 파티션: Follower Partition
- ISR(In-Sync-Replica): 같이 싱크되는 Leader Partition과 Follower Partition 의 묶음.
- Replication 의 개수는 Broker의 개수를 초과할 수 없다.
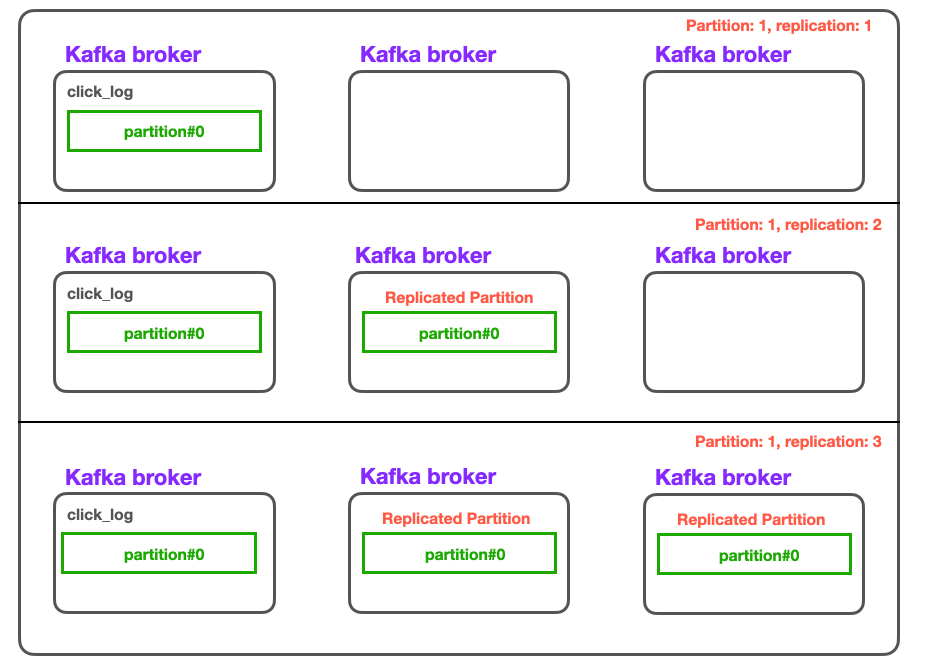
1) Replication의 사용 이유
Application의 고가용성을 위하여 사용된다.
2) Producer 의 옵션: ack
ack옵션: 파티션의 replication과 관련이 있다.
ack = 0: Leader Partition에 데이터를 전송하고 응답값은 받지 않는다. 데이터의 유실 가능성이 있다.ack = 1: Leader Partition에 데이터를 전송하고 응답값을 받는다. 나머지 파티션은 모른다. (default)ack = all: Leader Partition → Replication Partition 데이터를 전송하고 응답갓을 받는다. 데이터 유실은 없으나 속도가 현저히 느려진다.
