수정 내역
[2023-02-13]
- 오타 수정 (도움 주신 분: nkjang 님) - 감사합니다!!
- Error-Handleing 파트에서 Batch 모드 활성화시 Error Handling 메커니즘 사용 불가 내용 추가
Spring Cloud Stream 을 사용하는 목적
- 데이터 중심 애플리케이션을 단독으로 빌드하고, 테스트하고 배포할 수 있다.
- 메세지 구성 요소에 모던한 마이크로 아키텍처 패턴을 적용할 수 있다.
- 이벤트 중심적 사고에서 애플리케이션간의 책임을 분리할 수 있다. 각 서버의 노드는 이벤트의 원본 발행자를 신경쓰지 않고 이벤트를 소비할 수 있다.
- 비즈니스 로직을 Kafka 나 RabbitMQ 에 연결할 수 있다.
- 프레임워크가 제공하는 Content-Type 서포트나 데이터 타입 변경 등을 자유롭게 사용할 수 있다.
기본 예제
1) application.yaml
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9092
function:
definition: basicConsumer; basicProducer
bindings:
basicProducer-out-0:
destination: cloud-stream
content-type: application/json
basicConsumer-in-0:
destination: cloud-stream2) Consumer
basicProducer: 1초에 한 번씩 Kafka 에 100 이라는 이벤트를 발행한다.basicConsumer: Kafka 에 발행되는 이벤트를 받아서 Log 로 출력한다.
@Slf4j
@Configuration
public class KafkaConfig {
@Bean
public Supplier<Integer> basicProducer() {
return () -> 100;
}
@Bean
pubilc Consumer<String> basicConsumer() {
return number -> log.info("message = {}", number);
}
}3) 결과 확인
2022-09-14 10:26:32.248 INFO 7981 --- [container-0-C-1] s.kafkastream.config.KafkaConfig : message = 100
2022-09-14 10:26:33.210 INFO 7981 --- [container-0-C-1] s.kafkastream.config.KafkaConfig : message = 100
2022-09-14 10:26:34.204 INFO 7981 --- [container-0-C-1] s.kafkastream.config.KafkaConfig : message = 100
2022-09-14 10:26:35.216 INFO 7981 --- [container-0-C-1] s.kafkastream.config.KafkaConfig : message = 100
2022-09-14 10:26:36.207 INFO 7981 --- [container-0-C-1] s.kafkastream.config.KafkaConfig : message = 100
2022-09-14 10:26:37.228 INFO 7981 --- [container-0-C-1] s.kafkastream.config.KafkaConfig : message = 100
2022-09-14 10:26:38.237 INFO 7981 --- [container-0-C-1] s.kafkastream.config.KafkaConfig : message = 100메인 컨셉
1) Application Model
Spring Cloud Stream 은 미들웨어에 중립적인 코어로 구성되어 있다.
- 애플리케이션은 Bindings 를 구성하여 외부에 노출되어 있는 브로커와 통신한다.
- 필수적인 구성정보는 특정 미들웨어 (Kafka, RabbitMQ)를 구현하는 Binder 가 Broker 에 연결 가능한 Bindings를 구성하는데 사용된다.
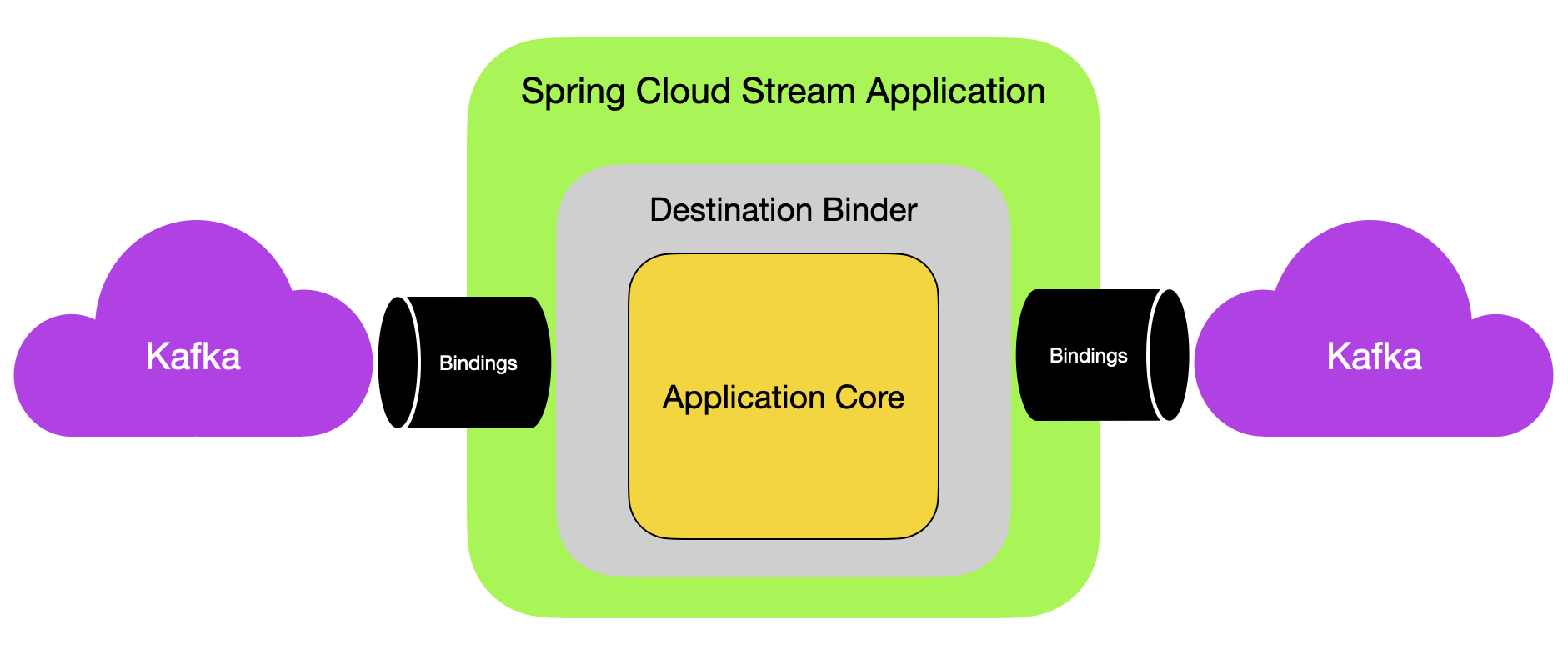
2) Binder Abstraction (바인더 추상화)
Spring Cloud Stream 은 kafka 와 RabbitMQ 를 구현하는 Binder 를 기본으로 제공한다. 프레임워크는 테스트 Binder 를 제공하여 통합(Integration) 테스트를 지원한다. 자세한 것은 Testing를 확인하자.
또한 Binder 는 확장 포인트로서 개발자가 직접 Binder 를 구현하여 Custom Binder 를 만들 수 있다. 자세한 것은 How to create a Spring Cloud Stream Binder from scratch 를 참조하자.
Spring Cloud Stream은 Spring Boot 설정을 사용할 수 있다. 따라서 Binder 추상화는 유연하게 미들웨어와 연결할 수 있다. 예를 들면 배포자는 런타임에 동적으로 Kafka, RabbitMQ 와 같은 외부 목적지를 매핑할 수 있다. 이러한 설정은 application.yaml, application.properties등을 사용하여 설정할 수 있다.
spring.cloud.stream.bindings.<input>.destination에서 설정할 수 있다.<input>은 네이밍 컨벤션에 의하여 개발자가 직접 설정해야 한다.
3) Consumer Groups
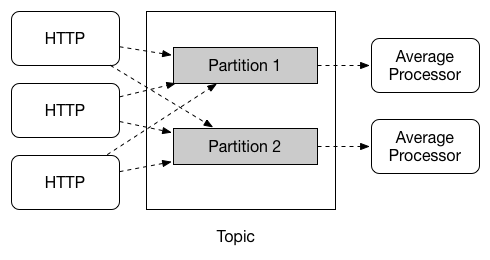
publish-subsribe 모델이 공유 토픽 사이에서 애플리케이션을 연결하는 것을 쉽게 만들어주지만, 주어진 애플리케이션에서 여러 인스턴스를 만들어 scale-up 하는 것 역시 이에 못지 않게 중요하다. 그렇게 함으로써 애플리케이션의 다른 인스턴스는 경쟁적 Consumer 관계에 놓이고, 오직 하나의 인스턴스만 주어진 메세지를 처리하도록 기대한다. → 메세지 중복처리 X
Spring Cloud Stream은 이러한 행동을 Consumer 그룹이라는 개념으로 모델링하였다.
- 각각의 Consumer 바인딩은
spring.cloud.stream.bindings.<bindingName>.group설정을 사용하여 그룹을 지정할 수 있다. - 아래의 이미지로 예를 들면 Consumer 그룹 설정은 다음과 같다.
spring.cloud.stream.bindings.<bindingName>.group=hdfsWrite
spring.cloud.stream.bindings.<bindingName>.group=average

4) Consumer Types
Consumer 의 종류는 2가지 타입이 지원된다.
- Message-Driven 방식 - Asynchronous
- Polled 방식 - Synchronous
5) Partitioning Support
Spring Cloud Stream은 다수의 인스턴스에 대하여 데이터를 파티셔닝하는 것을 지원한다. 파티션된 시나리오에서, broker topic 같은 물리적인 커뮤니케이션 대상은 다수의 파티션으로 구성된것으로 간주한다. 한 개 이상의 Producer 애플리케이션이 다수의 consumer 애플리케이션 인스턴스로 데이터를 보내면 해당 데이터를 인지하고 계속해서 같은 consumer 인스턴스가 해당 데이터를 처리하도록 보장한다.
Spring Cloud Stream 은 파티셔닝된 데이터 처리 케이스에 대하여 사용할 수 있는 추상화된 구현체를 제공합니다. 이를 사용하여 실제 파티셔닝을 사용하는 구현체인 Kafka 뿐만 아니라 이를 제공하지 않는 RabbitMQ 에서도 파티셔닝을 사용할 수 있습니다.
프로그래밍 모델
프로그래밍 모델을 이해하기 위해서는 아래의 주요 개념을 이해해야 한다.
- Destination Binders: 외부 메세지 시스템과 통합을 제공하는 역할을 담당하는 구성요소
- Bindings: 메세지 시스템과 애플리케이션 사이에서 Producer 와 Consumer 의 메세지를 제공하는 연결점
- Message: 정형화된 데이터로 Producer 와 Consumer 가 Destination Binders 와 커뮤니케이션하기 위해 사용한다. → 결과적으로는 애플리케이션이 외부의 메세지 시스템과 연결

1) Destination Binders
Destination Binder는 Spring Cloud Stream 의 확장 요소로서 필요한 설정과 외부 메세지 시스템과 통합을 가능하게 하는 구현을 담당합니다. 이러한 통합은 Consumer 와 Producer 에 대한 연결, 위임, 메세지의 라우팅에 대한 책임을 가지고 있으며 그 밖에도 데이터 타입 변환, 사용자 코드 실행 등을 담당합니다.
Binders 는 많은 진부한 책임을 개발자로 부터 가져갑니다. 하지만 이를 달성하기 위해서는 사용자의 최소한의 도움을 필요로 합니다. 이는 주로 Bindings 의 설정과 관련이 있습니다.
2) Bindings
아래의 예제는 메세지의 pay-load를 String의 형태로 받아서 로그를 기록하고 대문자로 변경하여 down-stream 으로 전달합니다.
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringAppliation.run(SampleApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> {
System.out.println("Receieved: " + value);
return value.toUpperCase();
}
}
}Spring Cloud Stream 의존성을 추가하면 Supplier, Function, Consumer 를 사실상 메세지를 처리 핸들러로 취급한다. 일종의 Trigger 등록으로 생각하면 쉽다.
Binding And Binding names
Binding은 Binder와 사용자의 코드에서 데이터 Source 와 Target을 연결하는 추상적인 다리 역할을 수행한다. 이때 이를 수행하는 과정에서 per-binding 설정이 필요한데 이때 이름(name) 이 필수적이다.
이 문서를 보면서 다음과 같은 설정을 많이 보는데, 여기서 input 에 들어가는 것이 binding 의 이름이다.
spring.cloud.stream.bindings.input.destination=myQueue
Function binding names
함수형 프로그래밍 모델에서는 기본적으로 함수의 이름을 기본적인 Binding 이름으로 지정하는 간단한 규칙을 따른다. 따라서 애플리케이션의 설정이 간단하다. 아래의 예를 확인해보자.
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}여기서는 Function 을 사용했기 때문에 Kafka 나 RabbitMQ로 부터 데이터를 받는 input 과 output이 모두 가능하다. 이 경우 네이밍 규칙은 아래와 같다.
- input:
<functionName> + in + <index> - output:
<functionName> + out + <index>
따라서 최종적인 설정은 다음과 같다.
- 이러한 함수형 프로그래밍 방식으로는
Supplier,Function,Consumer를 사용할 수 있다. - 여기서 Supplier 는 동작 방식이 조금 다른데 자세한 내용은 다음을 참조하자: https://docs.spring.io/spring-cloud-stream/docs/current/reference/html/spring-cloud-stream.html#_suppliers_sources
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9092
function:
definition: uppercase;
bindings:
uppercase-out-0:
destination: cloud-stream
uppercase-in-0:
destination: cloud-stream3) Producing And Consuming Message
Sending arbitrary data to and output
Kafka 나 RabbitMQ 같은 메세지 방식이 아닌 고전적인 REST API 으로 데이터를 받아서 보내야 하는 경우에는 다음과 같은 방식을 사용한다.
- 이 경우에는 yaml 설정 파일에는 bindings 를 지정했지만, 실제 @Bean 으로 등록하지는 않았다. (등록하면 1초당 데이터를 보낸다)
- 이렇게 하면 기본적으로 한 번 사용될 때 해당 Bindings 를 만들고 이후 호출에는 캐싱해놓은 Bindings를 불러와서 사용하게 된다.
- 이를 사용하면 런타임에 동적으로 값을 설정할 수 있다.
@Controller
@SpringBootApplication
public class Application {
@Autowired
private StreamBridge streambridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("basicProducer-out-0", body);
}
}- yaml 설정
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9092
bindings:
basicProducer-out-0:
destination: cloud-stream
content-type: application/json
basicConsumer-in-0:
destination: cloud-streamFunctional Composition
2개의 함수형 Bean 을 조합하여 사용할 수 있다.
@Slf4j
@Configuration
public class KafkaConfig {
@Bean
public Supplier<Integer> basicProducer() {
return () -> 100;
}
@Bean
public Function<Integer, Integer> firstInput() {
return value -> {
System.out.println(value * 2);
return value * 2;
};
}
@Bean
public Function<Integer, String> secondInput() {
return value -> {
String result = value.toString() + ": 원래는 숫자";
System.out.println(result);
return result;
};
}
}- yaml
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9092
function:
definition: basicProducer;firstInput|secondInput;
bindings:
firstInput|secondInput-in-0:
destination: cloud-stream
basicProducer-out-0:
destination: cloud-stream
content-type: application/json- 결과
200
200: 원래는 숫자
200
200: 원래는 숫자
200
200: 원래는 숫자
...Batch Consumers
MessageChannelBinder 를 사용하면 Batch 리스너를 지원한다.
이를 위해서는 spring.cloud.stream.<binding-name>.consumer.batch-mode 를 true 로 설정하면 된다.
- 해당 모드를 true 로 설정할 경우, Batch 가 아닌 데이터는 무시하고 가져오지 않는다.
- 버전 문제 (2.5 기준): 가져온 데이터를 파싱하는 과정에서 문제가 발행하므로 쓰지 않는 것이 좋을듯 하다.
- 인스턴스를 저장시 serialize 하여 List 에 저장하고 가져올 때 byte[] 타입으로 가져와서 deserialize 하여 사용할 수 있는 것은 확인하였다.
@Bean
public Supplier<List<byte[]>> basicProducer() {
List<byte[]> memberList = new ArrayList<>();
Member member1 = new Member(UUID.randomUUID().toString(), "xellos");
memberList.add(SerializationUtils.serialize(member1));
Member member2 = new Member(UUID.randomUUID().toString(), "zenon");
memberList.add(SerializationUtils.serialize(member2));
Member member3 = new Member(UUID.randomUUID().toString(), "crimson");
memberList.add(SerializationUtils.serialize(member3));
return () -> memberList;
}
@Bean
public Consumer<List<byte[]>> basicConsumer() {
return members -> {
for (byte[] member : members) {
Member real = (Member) SerializationUtils.deserialize(member);
System.out.println(real);
}
log.info("message = {}", members);
};
}- 버전 문제 해결(3.2 기준): 위의 문제가 해결되므로 아래와 같이 코드를 작성할 수 있다.
@Bean
public Supplier<List<Member>> basicProducer() {
List<Member> memberList = new ArrayList<>();
memberList.add(new Member(UUID.randomUUID().toString(), "xellos"));
memberList.add(new Member(UUID.randomUUID().toString(), "zenon"));
memberList.add(new Member(UUID.randomUUID().toString(), "crimson"));
return () -> memberList;
}
@Bean
public Consumer<List<Member>> basicConsumer() {
return members -> {
for (Member member : members) {
System.out.println(member);
}
log.info("message = {}", members);
};
}Batch Producers
@Bean
public Function<String, List<Message<String>>> batch() {
return p -> {
List<Message<String>> list = new ArrayList<>();
list.add(MessageBuilder.withPayload(p + ":1").build());
list.add(MessageBuilder.withPayload(p + ":2").build());
list.add(MessageBuilder.withPayload(p + ":3").build());
list.add(MessageBuilder.withPayload(p + ":4").build());
return list;
};
}4) Error Handling
메세지 핸들러에서 예외가 던져지면 이는 Binder 로 전달되고, Binder는 이를 messaging system 으로 전달한다. 프레임워크는 RetryTemplate 에 의해 몇 번의 재시도를 실행한다.
그 이후의 처리는 해당 메세지 시스템의 정책에 의존하게 된다. RabbitMQ 와 Kafka 의 경우는 다음의 시스템을 갖추고 있다.
- Message Drop
- Re-Queue Message
- Re-Processing for Send Fail Message To DLQ(Dead Letter Queue)
(Flux 등을 이용한 Reactive 처리에서 발생한 에러의 처리는 위의 경우와는 조금 다르게 동작한다. 자세한 내용은 다음을 참조: https://docs.spring.io/spring-cloud-stream/docs/current/reference/html/spring-cloud-stream.html#spring-cloud-stream-overview-error-handling)
Drop Failed Messages
기본적으로 어떠한 설정이 주어지지 않으면 메세지 시스템은 실패한 메시지를 버린다. 따라서 이러한 문제를 피하기 위해서 recovery-mechanism 이 필요하다.
Handle Error Messages
위에서 언급한 것처럼 기본적인 에러 처리 방식은 logged-and-drop 방식이다. 만약에 에러 발생시 handling 메커니즘을 원하다면 아래와 같이 ErrorMessage 를 받는 Consumer 를 추가하면 된다.
- 만약 Consumer 가 아닌 Function 으로 선언할 경우, Output 으로 어떠한 것도 발행하지 않는다.
- 다만, Function 의 경우 여러 조합을 사용하여 다양한 에러 처리 Handler 를 구성할 수 있다.
- 3.2.5 부터 사용 가능한 기능으로 그 이전엔 이러한 기능이 없다.
@Bean
public Consumer<ErrorMessage> KafkaErrorHandler() {
return e -> {
errorOccur++;
log.error("에러 발생: {}, 횟수: {}", e, errorOccur);
}
}- yaml 설정
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:9093
bindings:
basicConsumer-in-0:
consumer:
resetOffsets: true
start-offset: earliest
function:
definition: basicConsumer;
bindings:
basicConsumer-in-0:
destination: cloud-stream
content-type: application/json
error-handler-definition: kafkaErrorHandlerDLQ - Dead Letter Queue
아마도 가장 일반적인 방식은 DLQ 방식으로 실패한 메세지를 특정할 목적지(토픽)으로 보내는 방식일 것이다.
- DLQ 가 설정되어 있는 경우, 실패한 메세지를 후속 처리를 위해 설정한 목적지로 전송된다.
- DLQ 메커니즘을 특성상 반드시 group 이 지정되어야 합니다. (실패한 메세지를 전송할 토픽에 group 이름이 들어간다)
spring.cloud.stream.bindings.uppercase-in-0.consumer.max-attempts=1를 다음과 같이 설정하면 재시도 없이 바로 DLQ 를 실행합니다.
Kafka Binder 에서 자세한 설정은 다음 문서에서 참고 - 기본적으로 Kafka 바인더에서 DLQ 는 false 이다.
Spring Cloud Stream Kafka Binder Reference Guide
Retry Template - 재시도 프로퍼티 속성 목록
주의사항
batch-mode: true로 설정하여 배치모드로 spring-cloud-stream 에서 데이터 스트림을 소비할 경우에는 retry 가 적용되지 않고 가져온 값이 버려지므로 조심해야 한다.

잘 읽었습니다. 요약이 잘 되어 있네요.
레퍼런스 읽다가 지치고, 중도 포기했는데, 이 글을 읽으니 쏙쏙 들어오네요.
(도중에 오타가 있는 것 같지만 기분탓일 겁니다만, 몇 가지 오해의 소지가 있는 것만.. 알려드립니다)