배경
- 기존에 운영하던 사내 서비스를 환율 인상 등의 유지비용이 증가함에 따라 AWS -> IDC 이관하였습니다.
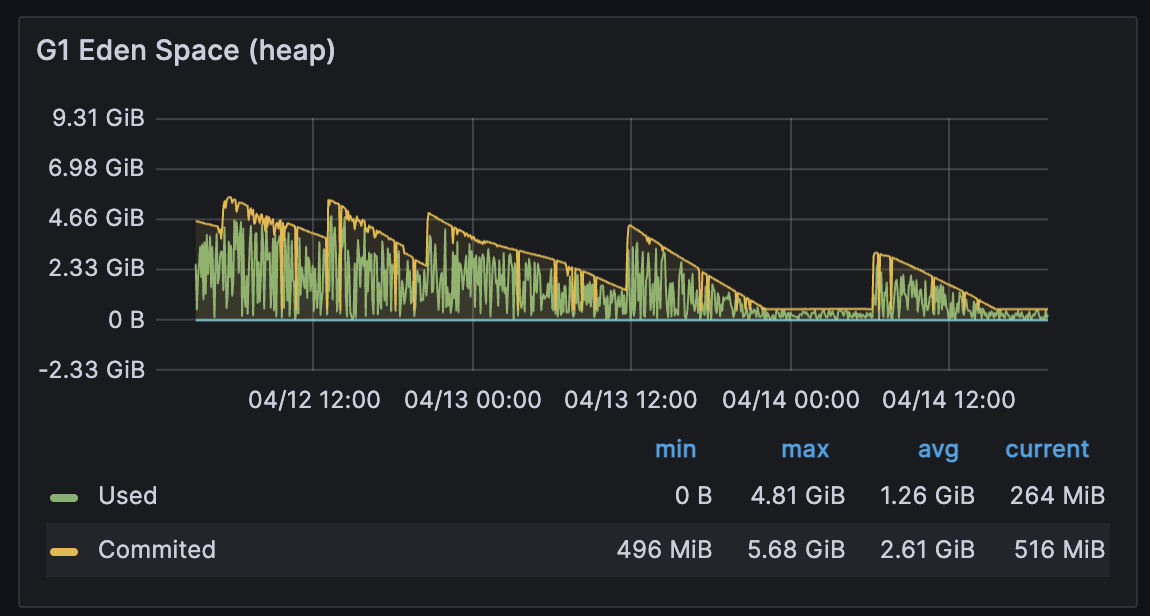
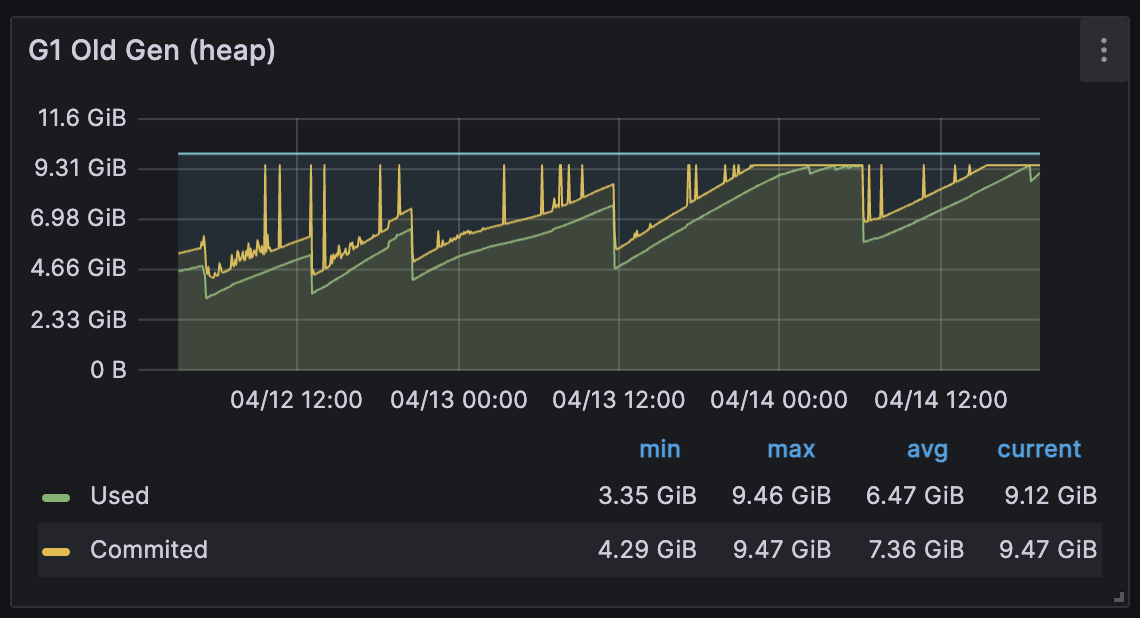
- 서비스 이관 이후 아래와 같이 메모리가 지속적으로 고갈되는 현상이 발생하는 것을 확인했습니다.
- 위와 관련해서는 이전에는 발생하지 않던 REDIS 와 관련된 timeout 예외가 발생하는 상황입니다. (timeout == 50ms)
[ Eden Area ]
[ Heap Area ]
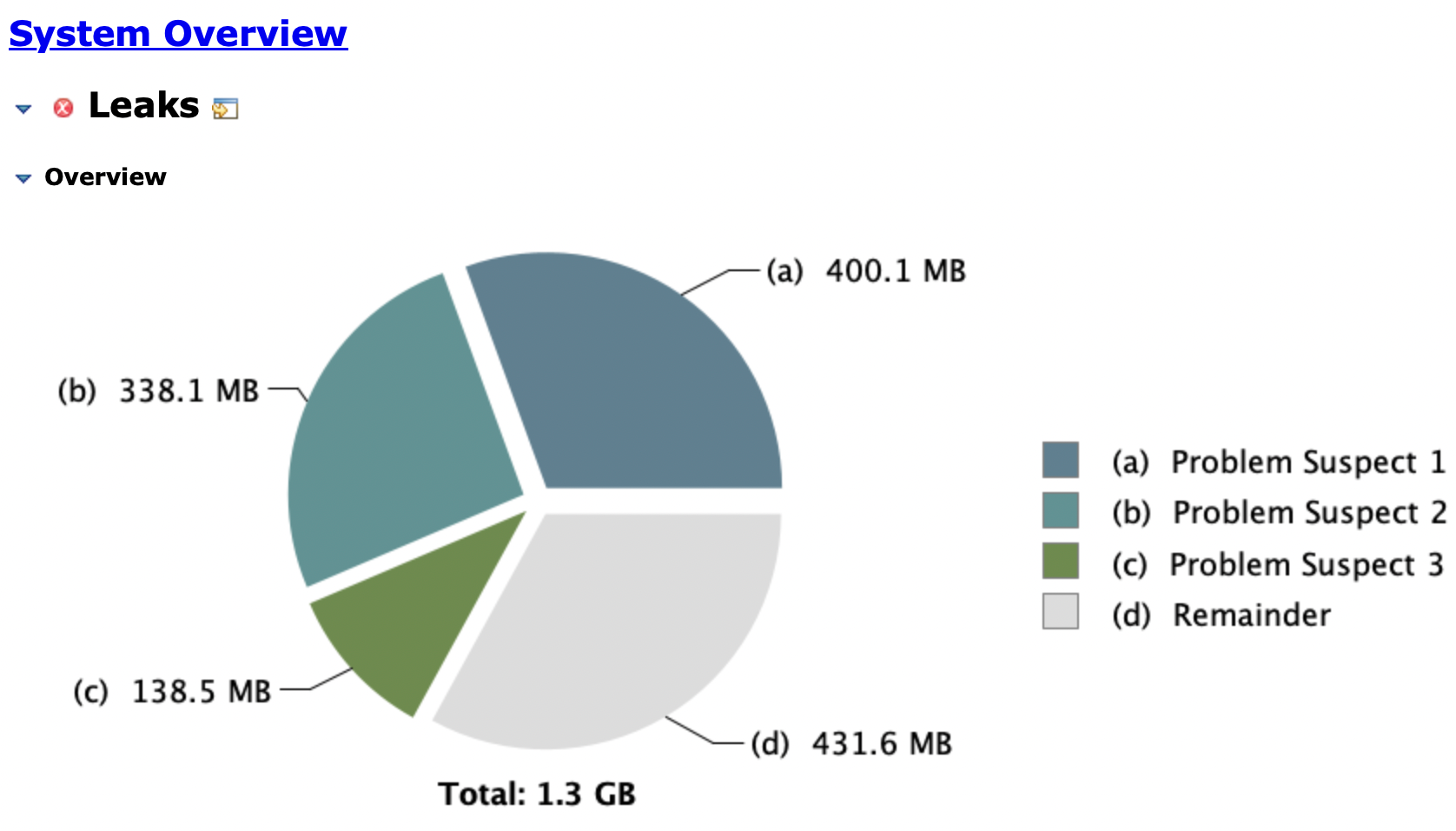
분석
위의 문제로 인해 Ecliipse 의 MemoryAnalyzer 를 활용해 힙덤프를 떠서 분석한 결과 3개의 문제가 될 수 있는 지점이 확인되었습니다.
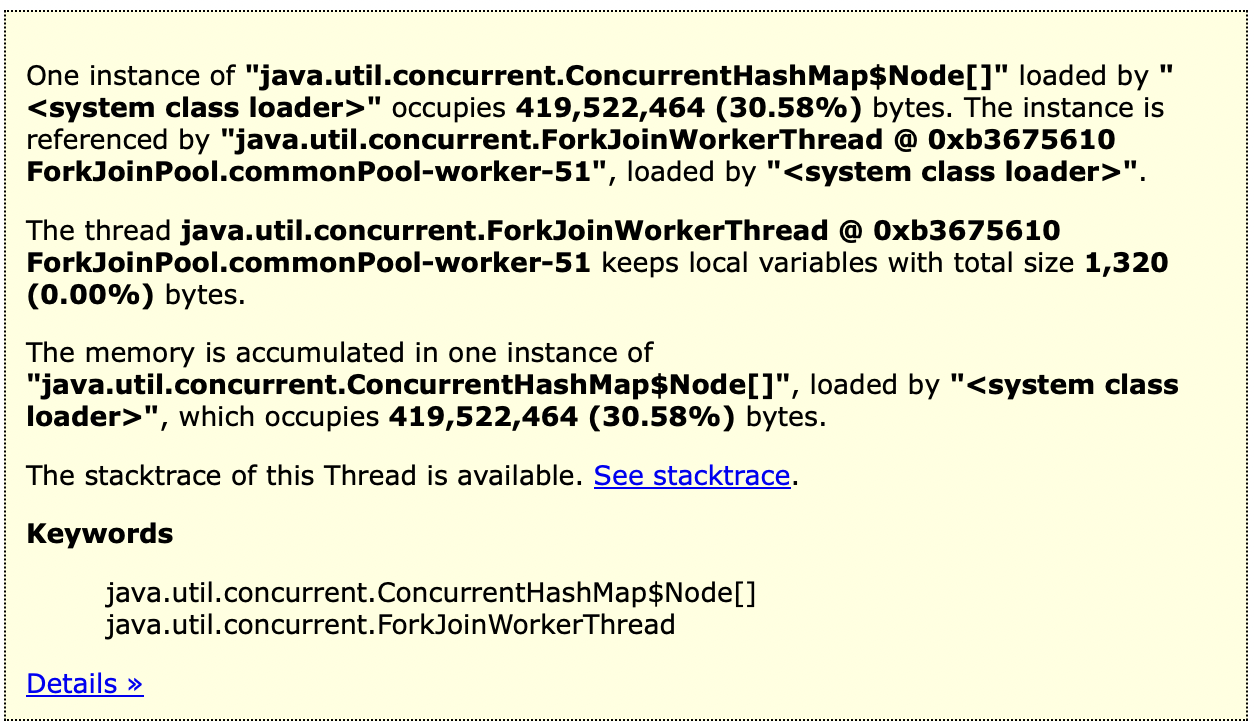
- java.util.concurrent.ConcurrentHashMap$Node[]
- io.netty.buffer.PoolChunk
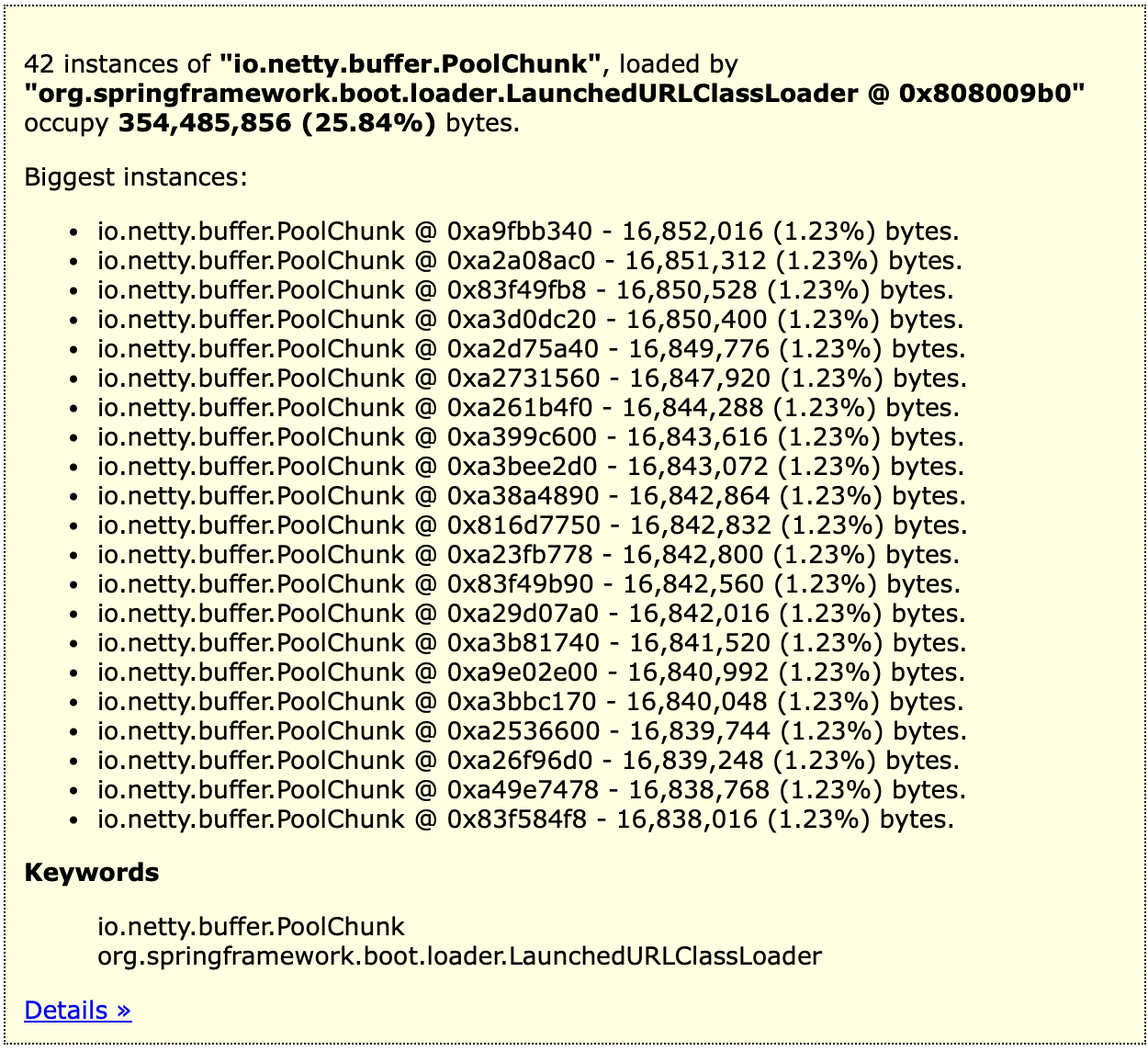
- io.netty.buffer.PoolThreadCache

위에서 java.util.concurrent.ConcurrentHashMap$Node[] 는 업체별 요청 QPS 정보를 담아두는 일종의 보관함인데 해당 부분이 의심되는 경우 가능성은 다음과 같이 2개로 추정합니다.
-
IDC 의 경우 네크워크 timeout 발생이 상대적으로 더 잦으므로 해당 저장소에서 데이터를 삭제하는 과정에서 처리가 밀릴 가능성이 존재
-
네트워크 처리와는 별개로 요청량 자체가 많으므로 timeout 이 없어도 순수하게 요청처리가 밀릴 가능성이 존재 (aws 였을 때보다 인스턴스당 요청량이 2.5배 가량 늘어난 상황)
-> 관련 스케줄러는 5ms 마다 동작하여 QPS 정보를 REDIS 에 업데이트 하는데, concurrent-hash-map 특성상 하나의 스케쥴러 쓰레드만 접근하여 저장된 데이터를 지울 수 있습니다.
반면, io.netty.buffer.PoolChunk 와 io.netty.buffer.PoolThreadCache 는 레디스와 통신하는 네트워크 커넥션과 관련된 것으로 이와 관련된 원인은 다음 2개로 추정합니다.
-
IDC 의 경우 네트워크 환경이 AWS 보다 좋지 않으므로 관련한 네트워크 커넥션 문제가 발생할 수 있음 (IDC 의 경우 기존의 AWS 연동 등의 문제로 인해 요청이 도달하는 과정이 몇 단계 더 추가된 상태)
-
REDIS 와 통신하여 QPS 정보를 업데이트 하는 부분의 코드가 비효율적으로 되어있어, 관련해서 문제가 발생할 가능성이 있음.
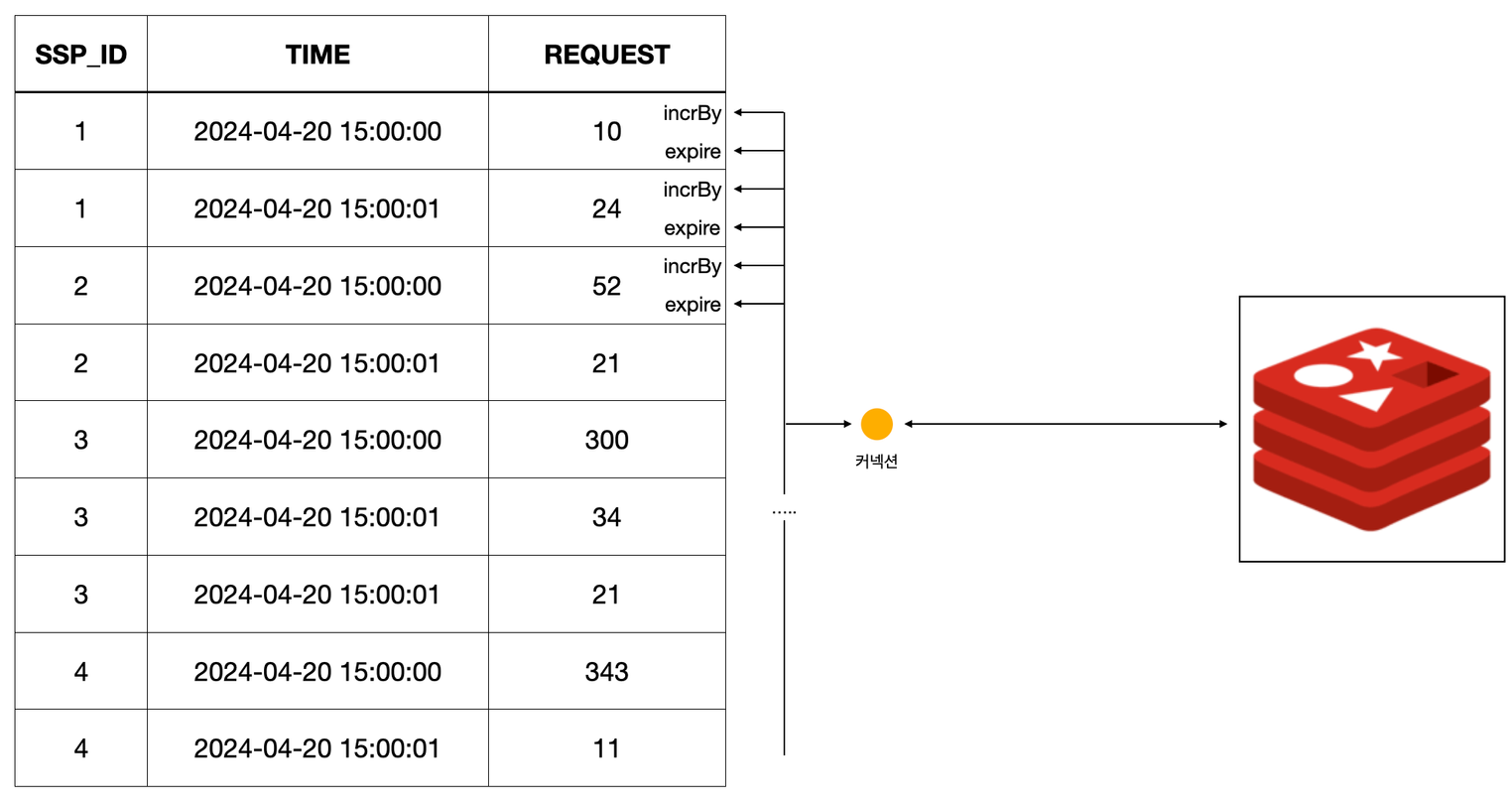
-> 현재 각 업체별 QPS 를 레디스에 반영하는 커넥션 발생수 공식:업체 수 X 시간(초) X 2(incr 작업 1개, expire 작업 1개)

간단히 정리하자면, IDC 서버로 이전 이후 늘어난 요청량에 비해 네트워크에 들어가는 비용이 증가함에 따라 데이터 처리에 병목이 지속적으로 발생하는 상황으로 보입니다. 이로인해 네트워크 및 이와 연결된 데이터가 정상적으로 삭제되지 않아 발생하는 문제로 보입니다.
실제로 해당 문제는 네트워크 비용이 상대적으로 적은 AWS 인스턴스에는 발생하지 않는 문제입니다.
해결 방안
1) 병렬 처리: ConcurrentHashMap 으로 인한 문제 완화
- 각각 업체 ID 를 기준으로 짝수, 홀수로 나누어 보관할 저장소를 2개로 분리
private final Map<Pair<Long, Long>, LongAdder> evenNumberSspIdRequestMap = new ConcurrentHashMap<>();
private final Map<Pair<Long, Long>, LongAdder> oddNumberSspIdRequestMap = new ConcurrentHashMap<>();
public void addRequest(long sspId, long time) {
if(sspId % 2 == 0) {
evenNumberSspIdRequestMap.computeIfAbsent(Pair.of(sspId, time), (k) -> new LongAdder()).add(1);
} else {
oddNumberSspIdRequestMap.computeIfAbsent(Pair.of(sspId, time), (k) -> new LongAdder()).add(1);
}
}- 각각 홀수, 짝수 업체 정보를 가진 저장소를 처리하도록 별도의 스케쥴러를 등록
@Scheduled(fixedDelayString = "${schedule.request-update}")
public void evenNumIdUpdateRequestCnt() {
if (isStop) {
isRunning = false;
return;
}
isRunning = true;
Set<Map.Entry<Pair<Long, Long>, LongAdder>> requestEntry = evenNumberIdRequestMap.entrySet();
...
}
@Scheduled(fixedDelayString = "${schedule.request-update}")
public void oddNumIdUpdateRequestCnt() {
if (isStop) {
isRunning = false;
return;
}
isRunning = true;
Set<Map.Entry<Pair<Long, Long>, LongAdder>> requestEntry = oddNumberIdRequestMap.entrySet();
...
}2) 커넥션 연결 최소화
기존: 각 한 번의 스케쥴러 작업당 업체수 X 시간 X 2 만큼의 커넥션 생성
- QPS 업데이트 관련 스케쥴러 코드
requestEntry.parallelStream()
.filter(it -> it.getKey().getSecond() < (System.currentTimeMillis() / 10))
.forEach(it -> {
String redisKey = getRedisKey(it.getKey().getFirst(), it.getKey().getSecond());
try {
redisService.incrBy(redisKey, it.getValue().sum());
redisService.expire(redisKey, 5);
removeEntry.add(it);
} catch(SspException e) {
log.info("[ERROR]: msg: {}, stack: {}", e.getMessage(), e.getStackTrace());
removeEntry.add(it);
}
});- QPS 업데이트 관련 레디스 코드
public class RedisService {
public long incrBy(String key, long incr) {
try {
return connection.async().incrby(key, incr).get(100, TimeUnit.MILLISECONDS);
} catch (Exception e) {
throw new SspException(SspErrorCode.REDIS_ERROR);
}
}
public void expire(String key, long ttlSecond) {
try {
connection.async().expire(key, ttlSecond).get(100, TimeUnit.MILLISECONDS);
} catch (Exception e) {
throw new SspException(SspErrorCode.REDIS_ERROR);
}
}
...
}- 개선: 하나의 스케줄러 작업당 하나의 커넥션만 생성후 이를 모든 업체 요청 QPS 반영에 사용하도록 수정
public Set<Map.Entry<Pair<Long, Long>, LongAdder>> incrAndExpire(Set<Map.Entry<Pair<Long, Long>, LongAdder>> requestEntry) {
Set<Map.Entry<Pair<Long, Long>, LongAdder>> removeEntry = new HashSet<>();
RedisAsyncCommands<String, String> async = connection.async();
requestEntry
.parallelStream()
.filter(it -> it.getKey().getSecond() < (System.currentTimeMillis() / 10))
.forEach(it -> {
String redisKey = getRedisKey(it.getKey().getFirst(), it.getKey().getSecond());
removeEntry.add(it);
try {
async.incrby(redisKey, it.getValue().sum()).get(100, TimeUnit.MILLISECONDS);
async.expire(redisKey, 5).get(100, TimeUnit.MILLISECONDS);
} catch(Exception e) {
log.info("[ERROR]: msg: {}, stack: {}", e.getMessage(), e.getStackTrace());
}
});
async.shutdown(true);
return removeEntry;
}
개선 결과 (테스트 배포)
테스트 배포: 2024-04-20 02:00:00
요청 흐름

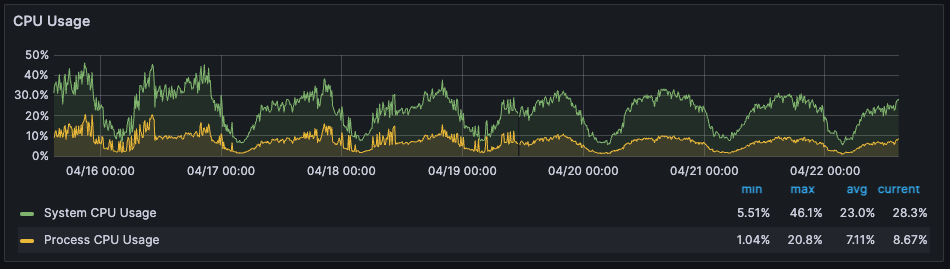
1) CPU
배포 이후, 종종 불안정하게 CPU 수치가 튀는 것 없이 완만히 안정적인 것 확인
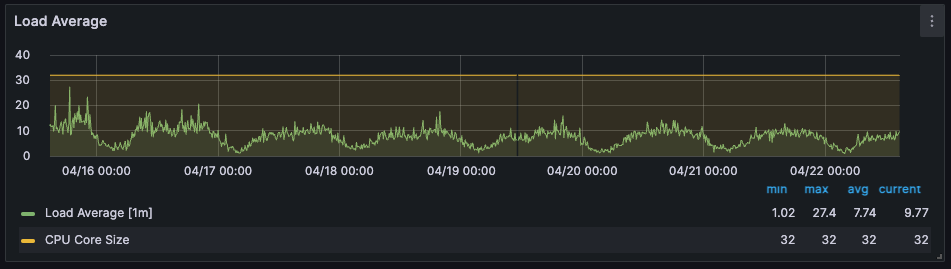
2) Load Average
이번과 큰 차이는 없지만 CPU 와 마찬가지로 전반적으로 튀는 것은 많이 개선된 것 확인
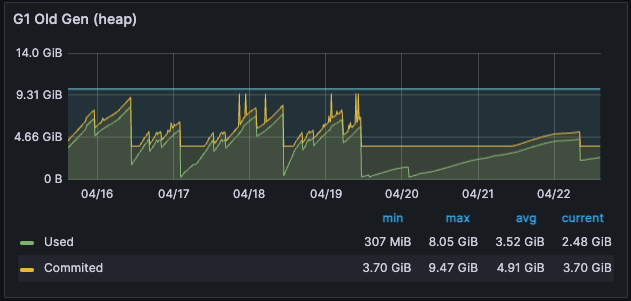
3) 메모리 사용 패턴
전체 Old Heap 메모리로 넘어가는 데이터가 많이 개선된 것 확인
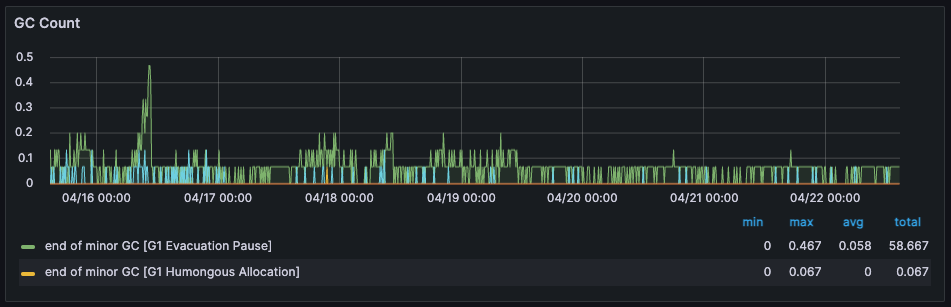
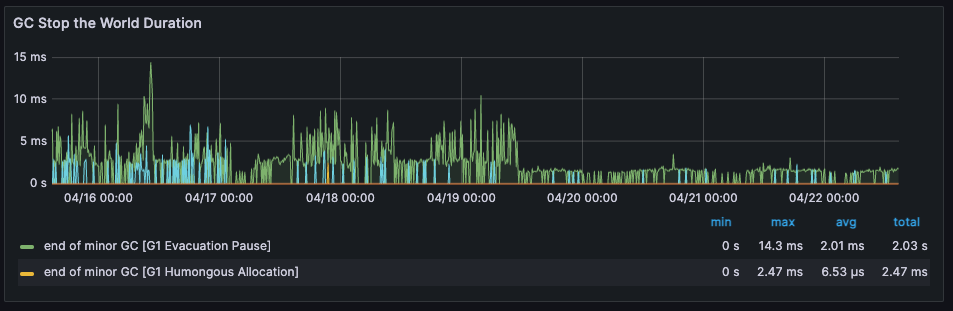
4) GC Count
네크워크 커넥션 연결과 관련된 비용과 보관 방식 개선으로 인해 GC 의 빈도와 그에 소용되는 시간이 줄어든것 확인
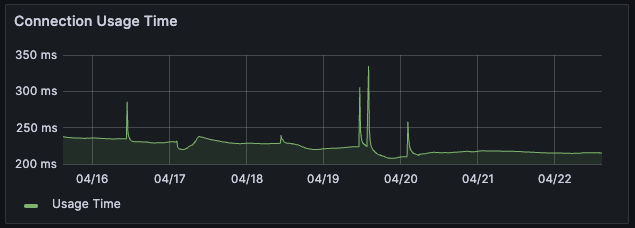
5) DB 커넥션 사용 시간
- 기존: 220~230ms
- 개선: 210~220ms

흥미로운 내용 + 깔끔한 정리 !!
잘 보고 갑니다 :) bb