INTRO
분산 아키텍처에서는 시스템의 물리적 위치 주소를 찾아야 한다. 이 개념은 분산 컴퓨팅 초창기때부터 존재했고 공식적으로 서비스 디스커버리라고 한다. 서비스 디스커버리는 애플리케이션에서 사용하는 모든 원격 서비스의 주소가 포함된 프로퍼티 파일을 관리하는 것 처럼 단순하거나 UDDI 저장소처럼 정형화되고 복잡한 것일 수 있다. 서비스 디스커버리는 다음 두 가지 핵심적인 이유로 마이크로서비스 및 클라우드 기반 애플리케이션에서 매우 중요하다.
- 애플리케이션 팀은 서비스 디스커버리를 사용해 해당 환경에서 실행하는 서비스 인스턴스의 개수를 신속하게 수평 확장하거나 축소할 수 있다.
- 애플리케이션 회복성을 향상하는데 도움이 된다. 마이크로서비스 인스턴스가 비정상이거나 가용하지 않다면 대부분의 서비스 디스커버리 엔진은 내부의 가용 서비스 인스턴스 목록에서 해당 인스턴스를 제거한다.
그런데 이것이 DNS의 로드 밸런서 같은 검증된 방법을 사용하는 것과 어떤 차이점이 있을까?
1. 서비스 위치 찾기
애플리케이션에서 여러 서버로 분산되 자원을 호출할 때마다 해당 자원의 물리적 위치를 찾아야 한다. 클라우드가 아닌 환경에서 이 서비스의 위치 확인은 대개 DNS 와 네트워크 로드밸런서로 해결하였다.
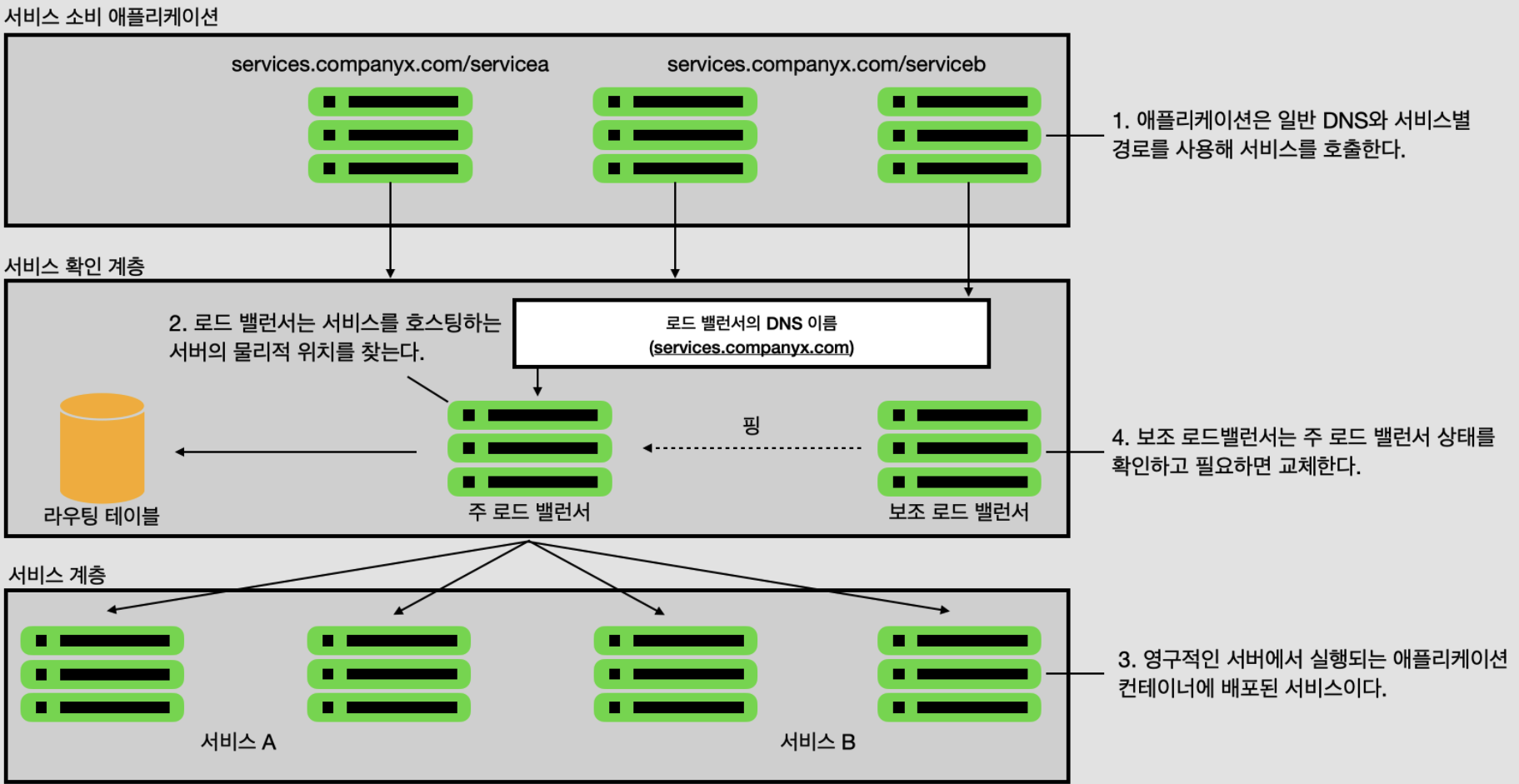
이처럼 애플리케이션은 다른 조직에 있는 서비스를 호출해야 한다. 애플리케이션이 호출하려덩 서비스를 대표하는 고유 경로와 함께 일반적인 DNS 이름을 사용해 서비스 호출을 시도한다.
서비스 소비자에게 요청을 받으면 로드 밸런서는 사용자가 액세스 하는 경로를 기반으로 라우팅 테이블에서 물리적 주소 항목을 찾는다. 이 라우팅 테이블 항목에는 해당 서비스를 호스팅하는 서버가 1개 이상 포함된 서버 목록이 있다. 로드 밸런서는 서버 목록에서 하나를 선택해 요청을 전달한다.
이러한 모델은 회사 데이터 센터 안에서 실행되는 앱과 정적 서버그룹에서 실행되는 소수 서비스에서는 잘 동작한다. 그러나, 클라우드 기반의 마이크로 서비스 앱에서는 그렇지 못하다. 그 이유는 다음과 같다.
1) 단일 장애 지점
로드 밸런서가 고가용성을 지원한다고 해도 여전히 전체 인프라 구조의 단일 장애지점이다. 로드 밸런서가 둔화되면 앱도 다운된다.
2) 수평 확장의 제약성
로드 밸런서 클러스터에서 서비스를 모아 연결하므로 분산 인프라를 여러 서버에 수평적으로 확장할 수 있는 능력이 제한된다. 또한 로드 밸런서는 가변 모델이 아닌 고정 용량에 맞추어 한정된 라이선싱 모델을 보유한다.
3) 정적 관리
전통적 로드 밸런서는 대부분 서비스를 신속히 등록하고 취소하도록 설계되지 않았다.
4) 복잡성
로드 밸런서가 서비스에 대한 프록시 역할을 하므로 서비스 소비자에게 요청할 때 물리적인 서비스에 매핑된 정보가 있어야 한다. 이러한 변환 계층을 서비스 매핑 규칙을 수동으로 정의하고 매핑해야 하므로 복잡성을 가중시킨다.
2. 클라우드에서 서비스 디스커버리
클라우드 기반 마이크로서비스 환경에 대한 솔루션은 다음 기능을 갖춘 서비스 디스커버리 메커니즘을 사용하는 것이다.
-
고가용성
서비스 디스커버리는 서비스 검색 정보를 서비스 디스커버리 클러스터의 여러 노드가 공유하는 '핫(HOT)' 클러스터링 환경을 지원해야 한다. 한 노드가 사용할 수 없게 되면 다른 노드가 인계를 받을 수 있어야 한다. -
피어 투 피어
서비스 디스커버리 클러스터의 각 노드는 서비스 인스턴스의 상태를 공유한다. -
부하 분산
서비스 디스커버리는 요청을 동적으로 부하 분산해서 서비스 디스커버리가 관리하는 모든 서비스 인스턴스에 분배해야 한다. 로드 밸런서는 서비스 디스커버리로 대체된다. -
회복성
서비스 디스커버리 클라이언트는 서비스 정보를 로컬에 캐시한다. 로컬 캐싱은 서비스 디스커버리 기능을 점진적으로 저하시킬 수 있는데 서비스 디스커버리 서비스가 가용하지 않을 때 앱이 로컬 캐시에 저장된 정보를 기반으로 서비스를 계속 찾을 수 있고 동작해야 한다. -
장애 내성
서비스 디스커버리는 서비스 인스턴스의 비정상을 탐지하고 가용 서비스 목록에서 인스턴스를 제거해야 한다.
1) 서비스 디스커버리 아키텍처
아래의 일반적인 새념은 모든 서비스 디스커버리 구현체에 해당된다.
- 서비스 등록: 서비스를 서비스 디스커버리에 어떻게 등록하는가?
- 클라이언트가 서비스 주소 검색: 서비스 클라이언트가 어떻게 서비스 정보를 검색하는가?
- 정보 공유: 서비스 정보를 노드간에 어떻게 공유하는가?
- 상태 모니터링: 서비스가 자신의 상태 정보를 서비스 디스커버리 에이전트에 어떻게 전달하는가?
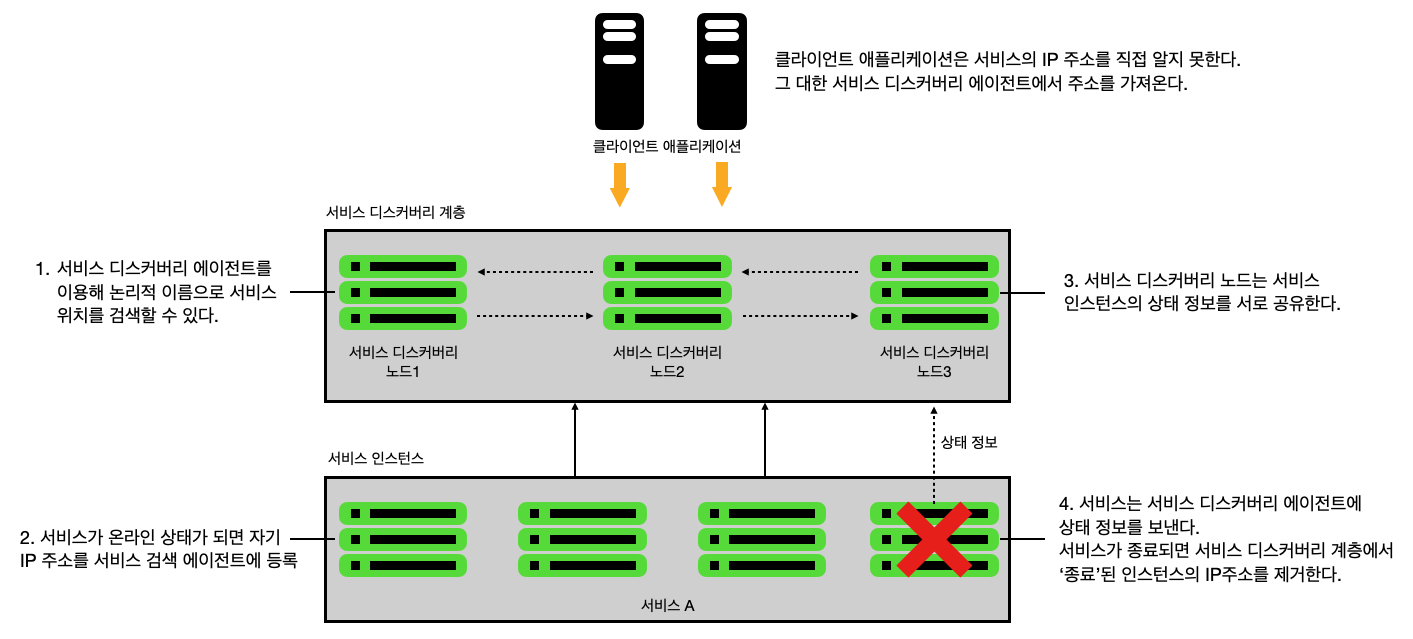
서비스 인스턴스가 시작하면 서비스 디스커버리 인스턴스가 접근할 수 있는 물리적 위치와 경로, 포트를 등록한다. 서비스가 시작하면 서비스의 각 인스턴스에는 고유한 IP 주소와 포트가 있지만 동일한 서비스 ID로 등록한다. 이때 서비스 ID 는 동일한 서비스 인스턴스 그룹을 고유하게 식별하는 키일 뿐이다.
서비스는 일반적으로 1개의 서비스를 디스커버리 인스턴스에만 등록한다. 서비스 디스커버리 구현체 대부분은 P2P 모델을 사용하여 서비스 인스턴스의 데이터를 클러스터에 있는 다른 노드에 전파한다.
각 서비스 인스턴스는 자기 상태를 디스커버리 서비스에 푸시하거나 디스커버리가 인스턴스 상태를 추출한다. 정상 상태가 아니면 인스턴스 풀에서 제거된다.
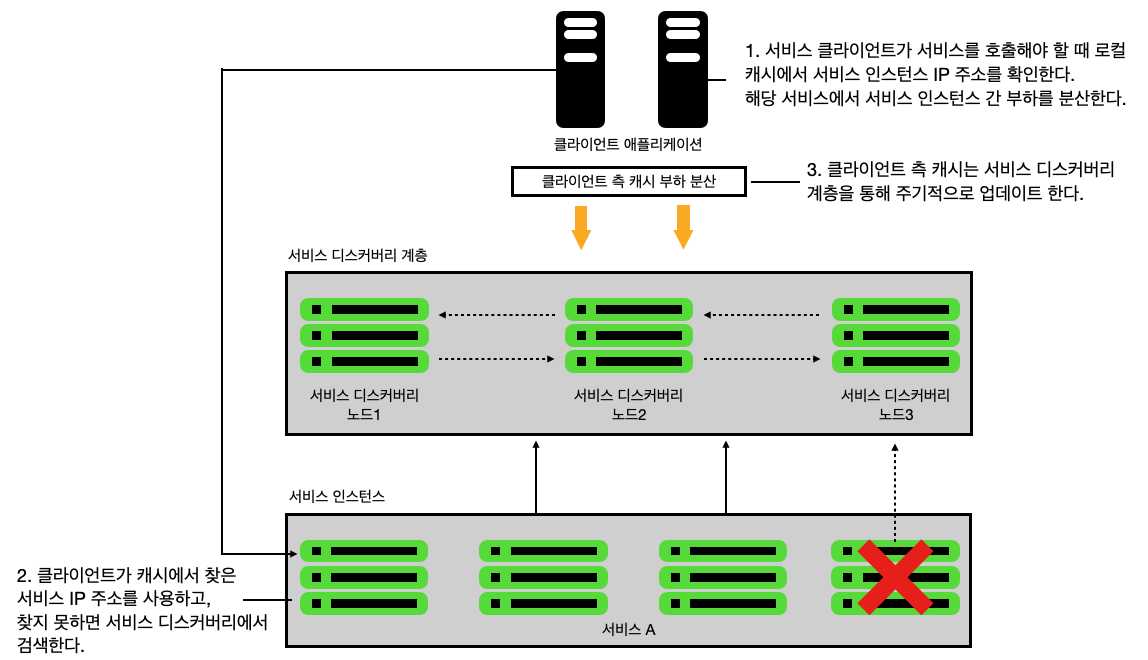
매 요청마다 클라이언트가 디스커버리 서비스를 호출하는 것은 비효율적이므로 일반적으로 클라이언트 측 부하 분산이라는 방법을 사용한다. 이는 캐시를 사용하는 방법이다.
2) 스프링과 넷플릭스 유레카를 사용한 서비스 디스커버리
여기서 스프링 클라우드와 넷플릭스의 유레카 서비스 디스커버리 엔진 을 사용해 서비스 디스커버리 패턴을 구현한다. 클라이언트 측 부하 분산을 위해 스프링 클라우드와 넷플릭스의 리본 라이브러리 를 사용한다.
- 이 예에서는 2개의 조직 서비스 인스턴스를 서비스 디스커버리 레지스트리에 등록한다.
- 이후 클라이언트 측 부하 분산 기능으로 서비스 인스턴스의 레지스트리를 조회하고 캐싱한다.
3. 스프링 유레카 서비스 구축
유레카 서비스는 컨피그 서버와 마찬가지로 하나의 독립 기능을 수행하는 서버이다. 이는 스프링이 지원하는 라이브러리이다.
1) Gradle 추가
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-server'2) applicatoin.yaml 파일 설정
register-with-eureka: 자신을 유레카 서비스에 등록하지 않도록 설정한다.fetch-registry: false 로 설정하면 유레카 서비스 시작시 레지스트리 정보를 로컬에 저장하지 않는다.wait-time-in-ms-when-sync-empty: 운영 환경에서는 주석처리된다. 로컬에서 유레카 서비스 테스트시 이 프로퍼티가 없으면 등록한 서비스를 즉시 알리지 않기 때문에 주석을 제거해야 한다. 기본적으로 유레카는 모든 서비스가 등록할 기회를 갖도록 5분 기다린 후 등록된 서비스 시작 정보를 공유한다. 로컬에서 테스트를 할 때 이 줄을 주석처리 안하면 유레카 서비스의 시작 시간과 등록 시간 서비스를 보여주는 시간을 단축할 수 있다.
server:
port: 8761
eureka:
client:
register-with-eureka: false #유레카 서비스에 (자신을) 등록하지 않는다
fetch-registry: false #레지스트리 정보를 로컬에 캐싱하지 않는다
server:
wait-time-in-ms-when-sync-empty: 5 #서버가 요청을 받기 전 대기할 초기 시간
serviceUrl:
defaultZone: http://localhost:87613) 애노테이션
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerAppliation {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}4. 스프링 유레카에 서비스 등록
서비스 서버에서 유레카에 서비스 등록을 위해서는 가장 먼저 스프링 유레카 의존성을 추가하는 것이다.
1) Gradle 추가
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'2) application.yaml
spring.application.name 과 spring.profiles.active 프로퍼티는 bootstrap.yaml 에 있지만 설명을 위해 추가했다. 이 둘은 장기적으로는 bootstrap.yaml 이 더 올바른 위치다.
spring:
application:
name: organizationservice #유레카에 등록할 서비스의 논리 이름
profiles:
active: default
cloud:
config:
enabled: true
eureka:
instance:
preferIpAddress: true #서비스 이름 대신 서비스 IP 주소 등록
client:
registerWithEureka: true #서비스 자신을 유레카에 등록
fetchRegistry: true #유레카 클라이언트가 레지스트리의 로컬 복사본을 가져도록 지정
serviceUrl:
#클라이언트가 위치를 확인하는데 사용할 유레카 서비스 목록을 쉼표로 구분해 보관
defaultZone: http://localhost:8761/eureka/유레카 서비스에 등록을 하는 서비스는 애플리케이션 ID와 인스턴스 ID 라는 두 가지 요소가 필요하다.
- 애플리케이션 ID는 서비스 인스턴스의 그룹을 의미. 즉 동일한 서비스의 클러스터명
- 서비스 인스턴스는 ID는 개별 서비스 인스턴스를 인식하는 임의의 숫자.
구성의 두 번째 부분이 유레카 서비스에 서버를 등록하는 위치와 방법을 제공한다.
preferIpAddress: 서비스 이름 대신 서비스 IP 주소 등록registerWithEureka: 서비스 자신을 유레카에 등록fetchRegistry: 유레카 클라이언트가 레지스트리의 로컬 복사본을 가져오도록 지정defaultZone: 클라이언트가 위치를 확인하는데 사용할 유레카 서비스 목록을 쉼표로 구분해 보관
1) 조직 서비스의 정보 확인
http://{eureka-service}:8761/eureka/apps/{APP_ID}
5. 서비스 디스커버리를 사용해 서비스 검색
유레카에 서비스를 등록했으면 각 서비스는 물리적 위치를 알지 못해도 호출할 수 있다. 라이선싱 서비스가 유레카를 이용해 서비스의 물리적 위치를 검색하기 때문이다. 여기서는 서비스 소비자가 리본과 상호작용할 수 있는 스프링 / 넷플릭스의 클라이언트 라이브러리 세 가지를 살펴본다.
- 스프링 디스커버리 클라이언트
- RestTemplate 이 활성화된 스프링 디스커버리 클라이언트
- 넷플릭스
Feign클라이언트
1) 스프링 DiscoveryClient 로 서비스 인스턴스 검색
스프링 DiscoveryClient 는 리본과 등록된 서비스에 가장 저수준의 접근성을 제공한다. DiscoveryClient를 사용하면 리본 클라이언트에 대한 해당 URL 에 등록된 모든 서비스에 대해 질의할 수 있다.
다음으로 DiscoveryClient 를 사용해 리본에서 조직서비스 URL 하나를 검색한 후 표준 RestTemplate 클래스로 서비스를 호출한다. 이를 위해서 DiscoveryClient를 사용하려면 @EnableDiscoveryClient 애노테이션을 먼저 추가해야 한다.
@EnableDiscoveryClient애노테이션은 스프링 클라우드에서 애플리케이션이 DiscoveryClient와 리본 라이브러리를 사용할 수 있게 한다.
@SpringBootApplication
@EnableDiscoveryClient //추가
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}DiscoveryClient로 조직 서비스를 호출하는 코드 구현
@Component
public class OrganizationDiscoveryClient {
@Autowired
private DiscoveryClient discoveryclient;
public Organization getOrganization(String organizationId) {
RestTemplate restTemplate = new RestTemplate();
List<ServiceInstance> instances = discoveryClient.getInstance("organizationservice");
if(instances.size() == 0) return null;
String serviceUrl = String.format("%s/v1/organizations/%s",
instances.get(0).getUri().toString(),
organizationId
);
ResponseEntity<Organization> restExchange = restTemplate.exchange(
serviceUrl, HttpMethod.GET, null, Organization.class, organizationId
);
return restExchange.getBody();
}
}한계
서비스가 리본에 질의해서 등록된 인스턴스 서비스를 알아야 할 때만 직접 DiscoveryClient를 사용해야 한다. 그러나 이 코드에는 다음 몇가지 문제점이 있다.
- 리본 클라이언트 측 부하 분산의 장점을 얻지 못한다.
- 너무 많은 일을 하고 있다.
2) 리본 지원 스프링 RestTemplate를 사용한 서비스 호출
여기서는 리본을 지원하는 RestTemplate를 사용하는 방법을 보여주는 예제를 살펴본다. 이 방법은 스프링을 사용해 리본과 상호작용을 할 수 있는 훨씬 더 일반적인 메커니즘이다.
@LoadBalanced 애노테이션 적용
리본 지원 RestTemplate 클래스를 사용하려면 @LoadBalanced 애노테이션으로 RestTemplate 빈 생성 메서드를 정의해야 한다.
@SpringBootApplication
public class Application {
@Bean
@LoadBalanced
public RestTemplate getRestTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}리본 지원 RestTemplate를 사용한 서비스 호출
@Component
public class OrganizationRestTemplateClient {
@Autowired
RestTemplate restTemplate;
public Organization getOrganization(String organization) {
ResponseEntity<Organization> restExchange = restTemplate.exchange(
"http://organizationserivce/v1/organization/{organization}",
HttpMethod.GET,
null,
Organization.class,
organizationId
);
return restExchange.getBody();
}
}위의 코드는 두 가지를 제외하면 이전 예제와 비슷하다.
1. 스프링 클라우드 DiscoveryClient 코드가 없다.
2. restTemplate.exchange() 호출에 사용되는 URL이 다른 형태이다.
URL에 포함된 서버 이름은 조직 서비스를 유레카에 등록할 때 사용된 조직 서비스 키의 애플리케이션 ID와 동일하다.
"http://organizationservice/v1/organization/{organizationId}"
http://{applicationId}/v1/organization/{organization}리본이 활성화된 RestTemplate는 잔달된 URL을 파싱하고 서버 이름을 키로 사용해 서비스 인스턴스를 리본에 질의한다. 실제 서비스 위치와 포트는 개발자에게 완젼히 추상화된다. 그리고 리본은 RestTemplate 클래스를 사용해 서비스 인스턴스에 대한 모든 요청을 라운드-로빈 방식으로 부하 분산한다.
3) 넷플릭스 Feign 클라이언트로 서비스 호출
스프링 리본이 활성화된 RestTemplate 클래스에 대한 다른 대안은 넷플릭스의 Feign 클라이언트 라이브러리다. 이를 사용하면 개발자가 자바 인터페이스를 먼저 정의한 후 리본이 호출할 유레카 기반의 서비스를 매핑하도록 그 인터페이스 안에 스프링 클라우드 애노테이션을 추가하여 REST 서비스를 호출하는 다른 접근법을 취한다.
스프링 클라우드 프레임워크는 대상 REST 서비스를 호출하는데 사용되는 프록시 클래스를 동적으로 생성한다. 인터페이스 정의외의 서비스를 호출하기 위해 다른 코드를 작성할 필요가 없다.
@EnableFeignClients 애노테이션 추가
@SpringBootApplication
@EnableFeignClients
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}조직 서비스 호출을 위한 Feign 인터페이스 정의
@FeignClient("organizationservice")
public interface OrganizationFeignClient {
@RequestMapping(
method=RestMethod.GET,
value="/v1/organizations/{organizationId}",
consumes="application/json")
Organization getOrganization(@PathVariable("organization") String organizationId);
}