오역 제보나 피드백은 언제나 환영입니다.
1. 개요
목적
이 글은 개발을 시작한지 얼마 되지 않으신 분들과 개발자와 협업하지면서 캐시에 대한 간단한 이해가 필요하신 분들이 읽으면 좋은 글이라고 생각되어 원문을 번역하여 문서로 작성하였습니다.
대상자
- 신입 개발자분들: 해당 문서를 모두 읽어보시는것을 권해드립니다.
- 개발자와 협업하시면서 캐싱에 대한 간단한 이해가 필요하신 분: 대부분의 경우 캐싱 예제까지만 읽어보셔도 괜찮으실거 같습니다.
출처
해당 문서는 위의 원문을 번역한 글입니다.
2. 번역
아래와 같이 캐시는 모든 곳에 있습니다.
- CPU 의 L1, L2, L3 캐시
- 운영체제의 페이지 / 디스크 캐시
- DB 를 위한 MemCached, Redis 와 같은 캐시
- API 캐시
- 7계층 (애플리케이션 계층) HTTP 캐시 (CDN)
- DNS 캐싱
- 브라우저 안에 들어있는 캐시
- 복잡하고 시간 집약적인 작업을 위해 존재하는 마이크로서비스 내부에 캐싱
- 등등
더 말할 수도 있겠지만 요점은 다음과 같습니다: 캐시는 어디에나 있다
그렇다면 이러한 캐싱이 왜 필요할까요?
캐시란 무엇인가?
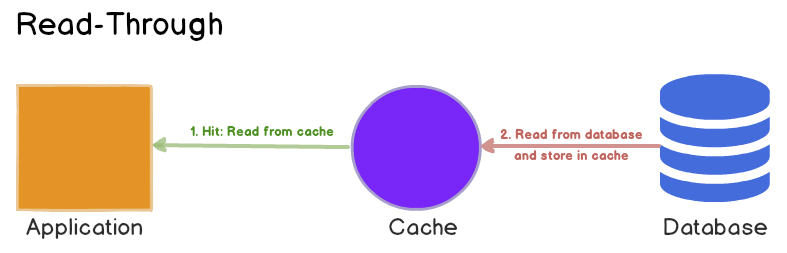
캐시는 일시적인 시간동안 데이터의 일부를 미리 저장하는 계층입니다. 캐시는 원래 데이터가 저장되어 있는 저장소보다 빠르기 때문에 필요한 데이터에 접근할 때 상대적으로 더 빨리 원하는 데이터에 접근할 수 있습니다. 또한, 매 요청마다 복잡하거나 무거운 연산 작업이 필요한 경우 이를 회피할 수 있어 효율적입니다.
애플리케이션에서 데이터가 필요할 때, 우선적으로 해당 데이터가 캐시에 저장되어 있는지 확인합니다. 만약 있다면 데이터는 캐시에서 바로 가져올 수 있습니다. 없다면 DB 에서 직접 가져오거나 필요한 경우 서비스에서 직접 데이터를 만들어서 반환해야 합니다. 일단 데이터를 한 번 가져오면, 같은 데이터 요구에 대비하여 일정 시간 캐시에 저장되게 됩니다.
왜 캐싱이 필요한가?
일반적으로 데이터를 캐싱하는데는 두 가지 이유가 있습니다.
-
데이터의 생성 비용이 비싸지만 매번 새로운 정보일 필요는 없는 경우. 예를 들어 특정 날짜에 대한 리포트 데이터 연산 같이 일단 한 번 계산한 후 일정 기간 보관하면서 사용자에게는 캐시 버전(해당 데이터가 얼마나 최신인지를 나타냅니다) 과 함께 보관된 데이터를 제공합니다.
-
반박의 여지가 없이 대부분의 이유는 데이터 획득 속도를 높이기 위해 캐시를 사용합니다. 캐시는 원래의 저장소를 이용하는 것보다 빠르고 따라서 사용자에게 그만큼 빨리 결과를 보여줄 수 있습니다.
캐싱 예제
한가지 예를 생각해보겠습니다.
웹 페이지가 있고 여기에는 ‘연관된 컨텐츠’ 라는 이름으로 여러 링크를 가진 사이드바가 있습니다. 이 ‘연관된 컨텐츠’ 는 방대한 양의 데이터를 메인 DB 에서 가져와 머신 러닝 알고리즘을 이용해 추출하기 때문에 한 번 연산하는데 몇 초 정도의 시간이 걸립니다.
- 이 작업은 복잡하고 자원 집약적인 작업입니다: 사용자가 많은 웹사이트의 경우 매번 사용자가 요청할 때마다 같은 작업을 반복하면 많은 컴퓨터 자원을 소모하게 됩니다.
- 부작용: 백엔드 서버와 DB 에 많은 부담이 가중되고 클라우드 서비스의 경우 많은 비용이 청구될 수 있습니다.
- ‘연관된 컨텐츠’ 를 생성하는 일은 시간이 걸리지만 사용자의 요청에 반드시 필요한 기능이기 때문에 응답이 늦어집니다
- 부작용: 응답 시간 지연은 사용자 경험에 부정적인 경험을 증가시키고 페이지의 성능 지표 (Core Web Value) 에 악영향을 미칩니다.
캐시는 이 두 가지 이슈를 다루기 위해 사용합니다. ‘연관된 컨텐츠’ 에 대한 연산을 한 번만 수행하고 이를 캐시에 저장하면 지정된 시간동안 추가적인 연산 없이 캐싱된 정보를 복사해서 반환합니다. 다음에 데이터 요청이 올 경우, 비용집약적이고 시간이 오래 걸리는 작업을 다시 하기보다는, 캐시에 저장된 정보를 활용하면 유저에게 더 빠른 응답을 할 수 있습니다.
캐시 무효화
위에서 비용을 절약하고 무거운 작업을 완화하고 지연시간을 줄이는 등의 캐시의 장점을 살펴봤습니다. 그러나 여기에는 개발자가 반드시 알고 있어야만 하는 트레이드 오프가 존재합니다.
컴퓨터 과학에서 가장 어려운 일은 이름짓기와 캐시 무효화이다 - Phil Karlton
캐시 무효화는 캐시에 저장된 데이터를 유요하지 않은 데이터로 마킹하는 작업입니다. 다음 요청이 왔을 때, 유효하지 않은 데이터는 반드시 캐시-미스 로 다루고 원본 저장소에서 값을 재생성 하도록 해야 합니다.
캐시된 데이터는 실제 원본 데이터가 아닙니다. 원본 데이터는 데이터베이스에 있거나 서비스가 생성해야 합니다. 문제는 DB 의 데이터가 변경되는 경우 발생하는데 이 경우 캐시된 데이터는 더 이상 유효하지 않습니다. 만약 캐시된 데이터가 유효하지 않다면, 모순되거나 부정확한 정보를 제공할 수 있습니다.
캐시정보 무효화는 어려운 작업입니다. 왜냐하면, 캐시를 다룰 때는 인풋에 대한 의존관계를 생각하면서 이를 다루어야 하기 때문입니다. 한 가지 요청만 바뀌어도, 캐시에서 유효하지 않은 결과를 받을 수 있습니다.
(예를 들어 A, B, C 값이 필요한 요청을 받았을 때 A, B 만 있고 C 는 없다면, 결국 C 데이터를 얻기 위해 추가적인 리소스 투입이 필요하기 때문입니다)
프로그램은 정확한 문제를 추적하기 어렵고 캐시 무효화 로직을 수정하기 어렵게 동작합니다. 만약 기능의 인풋과 아웃풋값이 잘 정의되어 있다면 문제를 해결하는것이 어렵지 않을 수도 있습니다. 사실 문제가 발생하고 그에따라 프로그램이 전혀 동작하지 않는다면 이를 찾기도 쉽고 해결하는것이 어렵지 않습니다. 그러나 캐시 무효화 문제의 경우에는 ‘대부분의 경우 동작’하는데 이런 경우가 버그를 발견하기 어렵게 만듭니다.
위의 ‘연관된 컨텐츠’ 페이지로 돌아가서 만약 하나의 링크가 사용자 불만으로인해 운영자가 이를 DB 에서 지웠다고 생각해봅시다. 이 경우 캐시된 링크가 무효화되지 않더라도 대부분의 사용자는 문제 없이 페이지를 이용할 수 있습니다. 그러나 몇몇 사용자가 해당 링크를 선택하게 되면 HTTP 404 예외를 마주하게 됩니다. 왜냐하면 해당 링크는 더이상 유효하지 않기 때문입니다. 이 경우 디버깅이 까다로운데 왜냐하면 링크를 보여주는 페이지 자체는 아무런 문제가 없기 때문입니다.
inter-connected 캐시를 기반으로 동작하는 분산시스템에서의 경우 많은 의존성 관계, 경합 조건 갱신이 필요한 모든 캐시의 무효화로 인해 이러한 문제는 더욱 해결하기 어렵습니다.
뿐만 아니라 이러한 문제는 각자의 코어가 캐시를 가지는 현대의 CPU 에서도 발생할 수 있고, JAVA 에서는 JVM 이 로컬 캐시에 업데이한 정보를 실제 메모리에는 반영하지 않는 문제로 인해 각기 다른 코어에서 쓰레드 간에 저장된 정보가 다를 수 있습니다.
(멀티 쓰레드 애플리케이션을 만들기 어려문 주된 이유중 하나입니다)
요약하면, 캐싱은 매우 유용한 기술입니다. 하지만 주의를 기울이지 않는다면 잘못될 가능성이 높습니다. 캐시를 사용할때는 언제, 그리고 어떻게 데이터를 무효화하고 적절한 무효화 절차를 만드는 것이 중요합니다.
캐시를 사용하지 말아야 하는 경우
캐시가 항상 정답인 경우는 없습니다. 몇몇 경우에는 캐시를 사용할 경우 성능에 악영향을 미칠 수 있습니다. 아래는 캐시가 필요한지 아닌지를 한 번 고민할 만한 질문입니다.
- 원래 데이터 소스가 무거운 경우 (DB 에서 여러 복잡한 조인 과정이 필요한 경우)
- 데이터가 매 요청마다 갱신될 필요가 없는경우
- 데이터를 가져오는 작업에 부작용이 없어야만 하는 경우 (은행 전산 시스템: 트랜잭션에 의한 부작용 가능)
- 데이터가 자주 접근되고 한 번 이상 필요한 경우 (자주, 많은 요청에 필요한 data subset 인 경우)
- 캐시 적중률: 누락 비율 및 총 캐시 누락 비용. 예를 들어, 사용자 요청이 들어올 때 캐시를 넣었는데 데이터가 캐시에 있는지 확인하는 데 10ms가 소요되고 원래 시간인 60ms가 걸린다고 가정할 경우. 요청의 5%만 캐시되는 경우 캐시 누락을 초래하는 요청의 95%에 10ms를 추가합니다.
