컴파일러 기초
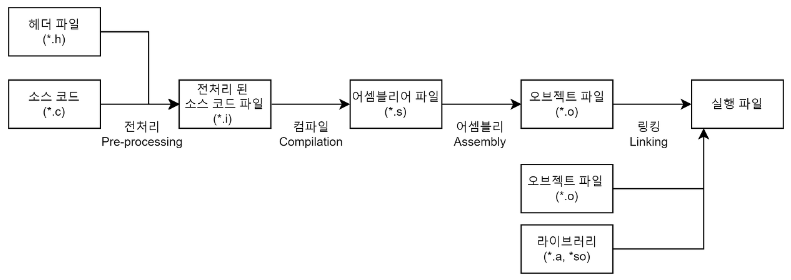
컴파일 과정은 4가지 단계(전처리 과정 - 컴파일 과정 - 어셈블리 과정 - 링킹 과정)로 나누어 진다.
이 4가지 단계를 묶어서 컴파일 과정, 빌드 과정이라고 부르기도 하고 컴파일 과정과 링킹 과정을 따로 나눠서 부르기도 한다.
보통 빌드 과정은 컴파일 과정보다 넓은 의미(빌드=컴파일+링킹)로 사용되는데 상황에 맞게 이해하면 될 거 같다.
그럼 각 단계별 과정에 대해 자세히 알아보자.
1. 전처리(Pre-processing) 과정
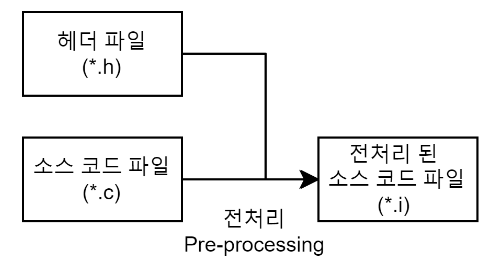
전처리(Pre-processing) 과정은 전처리기(Preprocessor)를 통해 소스 코드 파일(.c)을 전처리된 소스 코드 파일(.i)로 변환하는 과정이다.
이 과정에서 대표적으로 세 가지 작업을 수행한다.
- 주석 제거 : 소스 코드에서 주석을 전부 제거한다. 주석은 사람들이 알아볼 수 있게 남긴 내용이지 컴퓨터가 알 필요는 없기 때문이다.
- 헤더 파일 삽입 : #include 지시문을 만나면 해당하는 헤더 파일을 찾아 헤더 파일에 있는 모든 내용을 복사해서 소스 코드에 삽입한다. 즉, 헤더 파일은 컴파일에 사용되지 않고 소스 코드 파일 내에 전부 복사된다. 헤더 파일에 선언된 함수 원형은 후에 링킹 과정을 통해 실제로 함수가 정의되어 있는 오브젝트 파일(컴파일된 소스 코드 파일)과 결합한다.
- 매크로 치환 및 적용 : #define 지시문에 정의된 매크로를 저장하고 같은 문자열을 만나면 #define 된 내용으로 치환한다. 간단하게 말해 매크로 이름을 찾아서 정의한 값으로 전부 바꿔준다.
2. 컴파일(Compilation) 과정
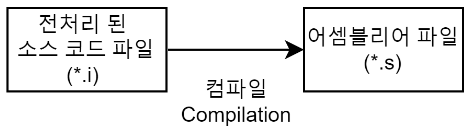
컴파일(Compilation) 과정은 컴파일러(Compiler)를 통해 전처리된 소스 코드 파일(.i)을 어셈블리어 파일(.s)로 변환하는 과정이다.
이 과정에서 우리가 일반적으로 컴파일하면 생각하는 언어의 문법 검사가 이루어진다. 또한 Static한 영역(Data, BSS 영역)들의 메모리 할당을 수행한다.
컴파일러 구조
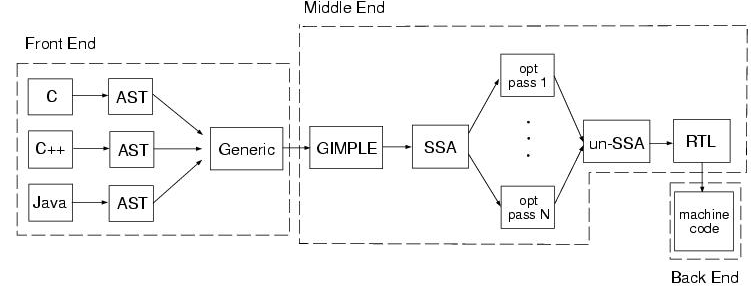
컴파일러는 세 단계(프론트엔드 - 미들엔드 - 백엔드)로 구성되어 있다.
-
프론트엔드(Front-end)
프론트엔드에서는 언어 종속적인 부분을 처리한다.소스 코드가 해당 언어로 올바르게 작성되었는지 확인(어휘/구문/의미 분석)하고 미들엔드에 넘겨주기 위한 GIMPLE 트리(소스 코드를 트리 형태로 표현한 자료 구조)를 생성한다.
이 과정에서 C, C++, Java와 같은 다양한 언어들이 각 언어에 맞게 처리된 후 공통된 중간 표현(IR : Intermediate representation)인 GIMPLE 트리로 변환되므로 언어 종속적인 부분을 처리할 수 있다.
-
미들엔드(Middle-end)
미들엔드에서는 아키텍쳐 비종속적인 최적화를 수행한다.아키텍쳐 비종속적인 최적화란 CPU 아키텍쳐가 무엇이든(arm, x86 등) 상관없이 할 수 있는 최적화를 말한다.
프론트엔드에서 넘겨받은 GIMPLE 트리를 이용해 아키텍쳐 비종속적인 최적화를 수행한 후 백엔드에서 사용하는 RTL(Register Transfer Language : 고급 언어와 어셈블리 언어의 중간 형태)를 생성한다.
-
백엔드(Back-end)
백엔드에서는 아키텍쳐 종속적인 최적화를 수행한다.아키텍쳐 종속적인 최적화란 아키텍쳐 특성에 따라 최적화를 수행하는 것을 말한다. 같은 기능을 수행하는 명령어여도 CPU 아키텍처별로 더욱 효율적인 명령어로 대체하여 성능을 높이는 작업을 예를 들 수 있다.
미들엔드에서 넘겨받은 RTL을 이용해 아키텍쳐 종속적인 최적화를 수행하고 최적화가 완료되면 어셈블리 코드를 생성한다.
아키텍쳐 종속적인 최적화를 수행하면 해당 아키텍쳐만 이해할 수 있는 언어가 되기 때문에 아키텍쳐가 맞지 않으면 어셈블리 코드를 해석할 수 없다.
- 어셈블리어 정의
기계어는 다른 말로 명령어(Machine Instruction)이라고 부르는데 명령어는 0101010과 같은 이진수로 이뤄진 숫자로 CPU 종류마다 고유한 내용을 가지고 있다.
어셈블리어는 이런 명령어를 사람이 이해할 수 있게 부호화한 것으로 CPU 명령어(기계어)와 1대1로 매칭된다.
많은 컴파일러가 앞서 설명한 세 단계의 구조를 따르고 있지만, 컴파일러마다 차이가 존재한다.
GNU에서 만든 C 컴파일러인 gcc는 프론트엔드/미들엔드/백엔드 단계가 깔끔하게 분리되어 있지 않고 의존성이 존재한다. 그에 비해 오픈 소스 C 컴파일러인 Clang(프론트엔드) + LLVM(미들엔드, 백엔드)는 단계가 잘 분리되어 있다.
3. 어셈블리(Assembly) 과정
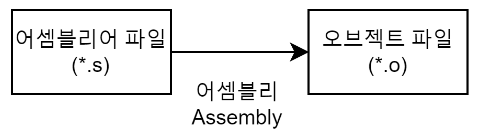
어셈블리(Assembly) 과정은 어셈블러(Assembler)를 통해 어셈블리어 파일(.s)을 오브젝트 파일(.o)로 변환하는 과정이다.
그럼 오브젝트 파일이란 무엇일까?
-
오브젝트 파일(Object File) 정의
어셈블리 코드는 이제 더 이상 사람이 알아볼 수 없는 기계어로 변환되는데 이를 오브젝트 코드라 부른다.오브젝트 코드로 구성된 파일을 오브젝트 파일(Object File)이라 부르며 이 오브젝트 파일은 특정한 파일 포맷을 가진다.
※ 오브젝트 파일 포맷의 종류는 Windows의 경우 PE(Portable Executable), Linux의 경우 ELF(Executable and Linking Format)로 나눠진다.
오브젝트 파일 포맷(Object File Format)
오브젝트 파일 포맷은 다음과 같은 구조를 하고 있다.
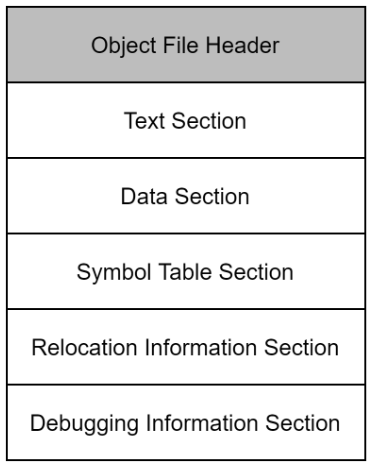
- 오브젝트 파일 헤더(Object File Header) : 오브젝트 파일의 기초 정보를 가지고 있는 헤더
- 텍스트 섹션(Text Section) : 기계어로 변환된 코드가 들어 있는 부분
- 데이터 섹션(Data Section) : 데이터(전역 변수, 정적 변수)가 들어 있는 부분
- 심볼 테이블 섹션(Symbol Table Section) : 소스 코드에서 참조되는 심볼들의 이름과 주소가 정의 되어 있는 부분.
- 재배치 정보 섹션(Relocation Information Section) : 링킹 전까지 심볼의 위치를 확정할 수 없으므로 심볼의 위치가 확정 나면 바꿔야 할 내용을 적어놓은 부분
- 디버깅 정보 섹션(Debugging Information Secion) : 디버깅에 필요한 정보가 있는 부분
여기서 중요한 부분은 심볼 테이블 섹션과 재배치 정보 섹션이다.
심볼(Symbol)은 함수나 변수를 식별할 때 사용하는 이름으로 심볼 테이블(Symbol Table) 안에는 오브젝트 파일에서 참조되고 있는 심볼 정보(이름과 데이터의 주소 등)를 가지고 있다.
이때 오브젝트 파일의 심볼 테이블에는 해당 오브젝트 파일의 심볼 정보만 가지고 있어야 하기 때문에 다른 파일에서 참조되고 있는 심볼 정보의 경우 심볼 테이블에 저장할 수 없다.
#include<stdio.h> 라이브러리를 이용해서 printf 함수를 사용하는 소스 코드 파일이 있다고 가정해보자.
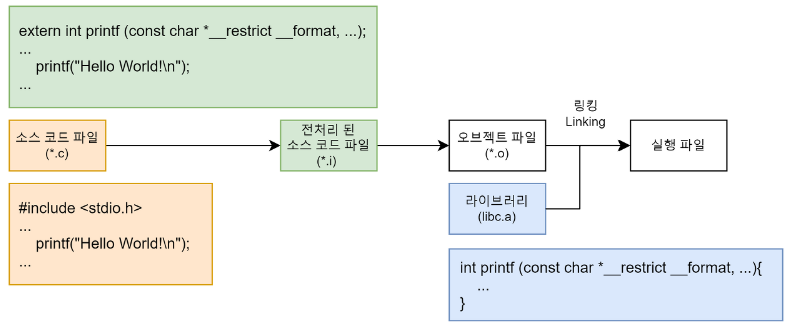
우린 이 소스 코드 파일을 컴파일하여 오브젝트 파일을 생성할 수 있다.
하지만 이 오브젝트 파일은 독립적으로 실행할 수 없다. 이 파일 안에는 printf 함수를 구현한 내용이 없기 때문이다.
전처리 과정을 통해 #include<stdio.h>로부터 printf 함수의 원형은 복사했지만 printf를 구현한 내용은 포함되어 있지 않다. 오브젝트 파일 구조에서 말한 것처럼 심볼 테이블에는 해당 오브젝트 파일의 심볼 정보만 가지고 있지 외부에서 참조하는 printf 함수에 대한 심볼 정보는 가지고 있지 않다.
즉, 이 오브젝트 파일을 실행하기 위해서는 printf 함수를 사용하는 오브젝트 파일과 printf 함수를 구현한 오브젝트 파일(libc.a 라이브러리)을 연결시키는 작업이 필요하다.
이러한 연결 과정을 링킹(Linking)이라 부른다. 그럼 링킹에 대해 자세히 알아보자.
4. 링킹(Linking) 과정
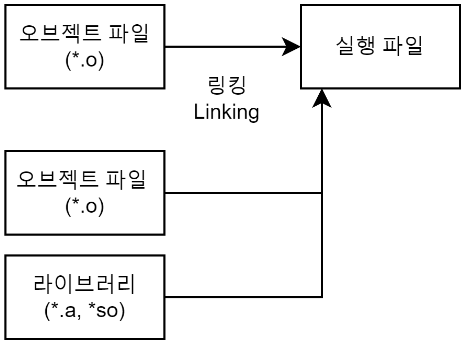
링킹(Linking) 과정은 링커(Linker)를 통해 오브젝트 파일(*.o)들을 묶어 실행 파일로 만드는 과정이다.
이 과정에서 오브젝트 파일들과 프로그램에서 사용하는 라이브러리 파일들을 링크하여 하나의 실행 파일을 만든다.
이때 라이브러리를 링크하는 방법에 따라 정적 링킹(Static Linking)과 동적 링킹(Dynamic Linking)으로 나눌 수 있다. 링킹 방식의 차이는 앞서 설명했던 라이브러리 포스트를 참고하자.
- 라이브러리(Library)에 대한 이해
- 서론 개발하다 보면 라이브러리를 사용할 일이 많다. 라이브러리를 사용해보면 정확한 개념은 몰라도 프로그램을 개발할 때 필요한 기능을 가져다 쓰는 도구라는 것은 어렴풋이 이해할 수 있다
- https://bradbury.tistory.com/224
링커의 역할
링커의 역할은 크게 심볼 해석과 재배치로 나눌 수 있다.
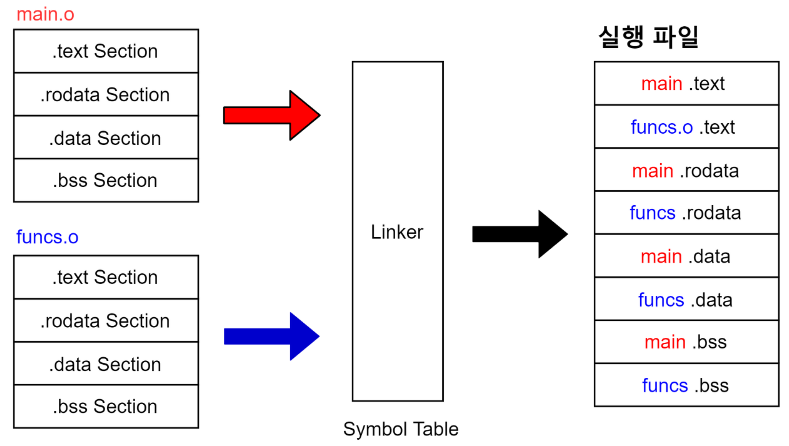
-
심볼 해석(Symbol Resolution)
심볼 해석은 각 오브젝트 파일에 있는 심볼 참조를 어떤 심볼 정의에 연관시킬지 결정하는 과정이다. 여러 개의 오브젝트 파일에 같은 이름의 함수 또는 변수가 정의되어 있을 때 어떤 파일의 어떤 함수를 사용할지 결정한다. -
재배치(Relocation)
재배치는 오브젝트 파일에 있는 데이터의 주소나 코드의 메모리 참조 주소를 알맞게 배치하는 과정이다.
링커가 컴파일러가 생성한 오브젝트 파일을 모아서 하나의 실행 파일을 만들 때, 각 오브젝트 파일에 있는 데이터의 주소나 코드의 메모리 참조 주소가 링커에 의해 합쳐진 실행 파일에서의 주소와 다르게 때문에 그것을 알맞게 수정해줘야 한다.
이를 위해 오브젝트 파일 안에 재배치 정보 섹션(Relocation Information Section)이 존재한다.
링킹 과정에서 같은 세션끼리 합쳐진 후 재배치가 일어난다.
위 그림을 통해 알 수 있듯이 오브젝트 파일 형식은 링킹 과정에서 링커가 여러 개의 오브젝트 파일들을 하나의 실행 파일로 묶을 때 필요한 정보를 효율적으로 파악할 수 있는 구조이다.
링킹을 하기 전 오브젝트 파일을 재배치 가능한 오브젝트 파일(Relocatable Object File)이라 부르고 링킹을 통해 만들어지는 오브젝트 파일을 실행 가능한 오브젝트 파일(Executable Object File)이라 부른다.
결론
이로써 컴파일을 통해 소스 코드 파일이 실행 파일이 되는 과정에 대해 알아보았다.
이 글을 통해 프로그래밍의 원리를 이해하는 데 조금은 도움이 되었으면 좋겠다.
※ 컴파일 과정 동안 연쇄적으로 사용하는 개발 도구들(전처리기-컴파일러-어셈블리-링커)을 묶어서 툴체인(Toolchain)이라고도 부른다.
컴파일러 종류
-
GCC (GNU Compiler Collection):
GNU Compiler Collection은 자유 및 오픈 소스 소프트웨어로, 다양한 언어를 지원하는 컴파일러 모음입니다. g++는 C++ 컴파일러를 나타냅니다. -
Clang:
Clang은 LLVM 프로젝트의 일부로 개발된 컴파일러이며, C++을 비롯한 다양한 언어를 지원합니다. Clang은 모듈성과 확장성이 뛰어나며, 정교한 코드 분석을 제공합니다. -
Visual C++ (Microsoft Visual Studio):
Microsoft에서 제공하는 Visual C++ 컴파일러는 Windows 환경에서 널리 사용됩니다. Visual Studio는 통합 개발 환경 (IDE)과 함께 제공되어 소프트웨어 개발을 편리하게 할 수 있습니다. -
Intel C++ Compiler:
Intel C++ Compiler는 Intel에서 개발한 컴파일러로, Intel 프로세서를 타겟으로 하는 애플리케이션을 최적화할 수 있는 기능을 제공합니다. -
Clion (JetBrains):
JetBrains의 Clion은 C++ 개발을 위한 통합 개발 환경으로, CMake 기반의 프로젝트를 지원하며, 컴파일러는 사용자가 설정할 수 있습니다.
-
컴파일러 제공 업체 역할 :
C++ 표준 라이브러리(STL)는 표준화된 API를 제공하며, 이를 구현하는 역할은 주로 컴파일러 제공 업체에게 있습니다. 표준 라이브러리는 C++ 언어의 표준 스펙에 따라 정의되어 있으며, 컴파일러 업체는 이러한 표준에 따라 라이브러리를 구현합니다.컴파일러 제공 업체는 특정 플랫폼에 맞는 최적화와 호환성을 고려하여 C++ 표준을 구현합니다. 표준 라이브러리의 구현은 특정 운영 체제 및 하드웨어 환경에 맞추어져야 하며, 이는 각각의 컴파일러 제공 업체가 수행합니다.
표준 라이브러리의 구현은 주로 헤더 파일과 라이브러리 파일의 형태로 제공되며, 이를 프로그래머가 사용할 수 있게 합니다. 대표적인 C++ 컴파일러 업체로는 GCC(GNU Compiler Collection), Clang, Visual C++(Microsoft), Intel C++ Compiler 등이 있습니다. 각 컴파일러는 자체적으로 표준 라이브러리를 제공하며, 이를 통해 개발자는 표준 라이브러리를 사용하여 C++ 언어로 프로그래밍할 수 있습니다.
표준 라이브러리의 품질과 성능은 컴파일러 제공 업체마다 차이가 있을 수 있으므로, 특정 프로젝트에서는 컴파일러의 선택도 중요한 요소 중 하나가 될 수 있습니다.
컴파일러 별 퍼포먼스 비교
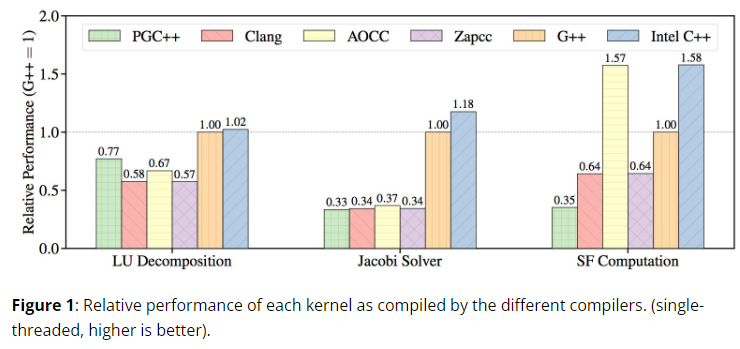
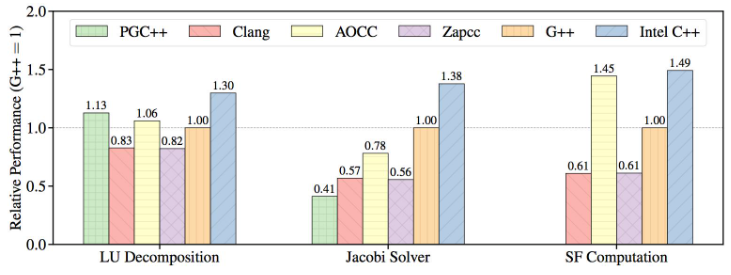
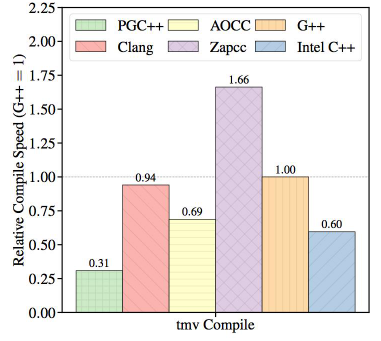
The tests are performed on an Intel Xeon Platinum processor featuring the Skylake architecture with AVX-512 vector instructions.
최적화
대표적인 최적화 방법
- 정수의 축약 (constant folding) : 정수 미리 계산
- 식의 단순화 (algebraic simplification) : 수학 식 간단하게 정리
- 연산 강도 감소 (strength reduction) : 곱셈보다 덧셈, 곱셈을 시프트 연산으로 전환
- 공통된 부분 식 삭제 (common subexpression elimination) : 중복 계산 식 생략
- 불필요한 명령 삭제 (dead code elimination) : 의미 없는 명령 삭제
- 함수 인라인 전개 (function inlining) : 함수 호출 시, 함수 코드를 그냥 전개해버리는 방법. 단, 같은 파일에 있어야 가능. 다른 파일이라면 링커에도 최적화 필요
최적화의 분류
-
방법에 의한 분류 프로그램 동작을 빠르게 하는 3가지 : 명령 수를 줄임, 더 빠른 명령 사용, 명렬 병렬 실행
-
대상 범위에 의한 분류 : 로컬 최적화, 글로벌 최적화

-
코드 최적화기는 프로그램을 블록, 흐름 그래프로 분류하고 정적 분석하여 최적화 할 위치 파악
-
핍홀 최적화 기법 (Peephole)
- 핍홀 : 연속적인 몇개의 명령어 집합
- 작은 코드 단위에서 최적화 수행
- 핍홀 최적화 기법
- 중복 명령어 제거
- 제어 흐름 최적화
- 대수학적 간소화
- 연산 세기 감축
-
지역 최적화
- 블록 안에서 최적화
- 공통 부분식 제거, 복사 전파, 죽은 코드 제거, 상수 폴딩, 대수학적 간소화
-
전역 최적화
- 프로그램 전체 흐름 분석을 통해 비효율적 코드를 효율적으로 변환
- 블록 간 흐름 그래프와 프로그램 전체 흐름 분석
- 상수 폴딩, 도달 불가능 코드 제거, 죽은 코드 제거, 명령어 스케줄링
최적화 실무 Tip
- gcc 에서는
-O0,-O2,-O3option 을 통해 Optimization level 설정 가능 - 일반적으로
-O0는 디버깅 목적,-O2,-O3는 release 목적 - 그런데
-O3라고 무조건-O2보다 빠르지 않음. 케바케 이므로 직접 build 해보고 benchmark test 해봐야 함.
gcc
- gcc (GNU C Compiler)
- 전처리기 cpp, 컴파일러 cc1, 어셈블러 as, 링커 ld
gcc 옵션
- -c 소스 파일을 컴파일만 하고 링크를 수행하지 않으며, 오브젝트 파일을 생성한다.
- 분리 컴파일 : a.c 파일을
-coption 으로 각각 컴파일해서 오브젝트 파일 만든 후에 한번에 링크 가능. 그리고 특정 파일만 수정했다면 그 파일만 다시 컴파일해서 다시 링크 가능 .c의 경우 전처리, 컴파일, 어셈블이 수행된다..i의 경우 컴파일, 어셈블이 수행된다..s의 경우 어셈블이 수행된다.
- 분리 컴파일 : a.c 파일을
- -o 바이너리 형식의 출력 파일 이름을 지정하는데, 지정하지 않으면 a.out라는 기본 이름이 적용된다.
- -I 헤더 파일을 검색하는 디렉토리 목록을 추가한다.
- -L 라이브러리 파일을 검색하는 디렉토리 목록을 추가한다.
- -l 라이브러리 파일을 컴파일 시 링크한다.
- -E 전처리를 실행하고 컴파일을 중단하게 한다. (전처일 과정 중 발생한 에러를 검증)
- -g 바이너리 파일에 표준 디버깅 정보를 포함시킨다.
- -ggdb 바이너리 파일에 GNU 디버거인 gdb만이 이해할 수 있는 많은 디버깅 정보를 포함시킨다.
- -O 컴파일 코드를 최적화시킨다.
- -ON 최적화 N 단계를 지정한다.
- -DFOO=RAR 명령라인에서 BAR의 값을 가지는 FOO라는 선행 처리기 매크로를 정의한다.
- -static 정적 라이브러리와 공유 라이브러리가 같이 있으면, 정적 라이브러리를 우선하여에 링크한다.
- -shared 정적 라이브러리와 공유 라이브러리가 같이 있으면, 공유 라이브러리를 우선하여 링크한다.
- -ansi 표준과 충돌하는 GNU 확장안을 취소하며, ANSI/ISO C 표준을 지원한다. 이 옵션은 ANSI 호환 코드를 보장하지 않는다.
- -traditional 과서 스타일의 함수 정의 형식과 같이 전통적인 K&R(Kernighan and Ritchie) C 언어 형식을 지원한다.
- -MM make 호환의 의존성 목록을 출력한다. (Makefile 작성 시 유용)
- -V 컴파일의 각 단계에서 사용되는 명령어를 보여준다.
- -Wall 모든 경고 활성화 (경고는 코드의 잠재적 오류를 나타내거나, 코딩 규칙에 어긋나는 부분을 감지하는데 사용)
- -pipe 빌드 시 파이프라인을 이용하여, 컴파일 중 생성한 중간 파일을 저장하지 않고 메모리 상에서 파이프를 통해 전달. Disk I/O 가 줄기 때문에 빌드 속도가 빨라짐.
- -DMKL_ILP64 프리프로세서 매크로 정의. Intel MKL 사용 할 때 주로 활용.일반적으로 MKL 은 32비트 정수를 사용하는데, 이 옵션을 통해 64비트를 사용하도록 함. -std=XXX: C++ standard version 지정
유용한 gcc option
-Wextra,-Wall: 필수-Wfloat-equal: testing floating-point numbers for equality is bad (???)출처 :
https://stackoverflow.com/questions/3375697/what-are-the-useful-gcc-flags-for-c
유용한 Intel compiler 옵션
-openmp,-parallel,- TODO
출처:
- https://doku.lrz.de/most-important-intel-compiler-options-and-directives-10746522.html
- https://www.bu.edu/tech/support/research/software-and-programming/programming/compilers/intel-compiler-flags/
환경 변수를 사용한 gcc 설정
COMPILER_PATH: gcc는 COMPILER_PATH에 등록된 전처리기(cc1 -E), 컴파일러(cc1), 어셈블러(as), 링커(collect2, ld)를 찾는다. 따라서 export COMPILER_PATH={directory}를 통해 원하는 전처리기, 컴파일러, 어셈블러, 링커를 선택케 할 수 있다.C_INCLUDE_PATH, CPLUS_INCLUDE_PATH, OBJC_INCLUDE_PATH: 소스 파일을 전처리 할 때 헤더파일을 찾을 디렉토리를 지정하는 환경변수이다.LIBRARY_PATH: 라이브러리를 찾을 디렉토리를 지정하는 환경 변수이다.- spec 파일을 이용해서도 gcc 설정 가능
최적화 옵션
-O 옵션은 -ON(숫자)을 써줌으로써 최적화 단계를 구분할 수 있는데, N 값은 gcc 버전마다 차이가 나며 값이 커질수록 더욱 최적화된 코드가 나온다. 일반적으로, -O1, -O2를 많이 사용하며, -O1, -O2, -O3에 의한 최적화 내용은 다음과 같다.
- -O0 옵션 : 최적화를 수행하지 않는다.
- -O1 옵션 : -O0보다는 조금 낫다. 목적 파일 크기, 수행 시간 둘 다 최적화
- -O2 옵션 : 가장 많이 사용하는 옵션. 일반 응용 프로그램이나 커널을 컴파일 할 때 사용 (거의 대부분의 최적화를 수행한다.). 목적파일 크기가 너무 커지지 않는 선에서 최적화
- -O3 옵션 : 가장 높은 레벨의 최적화. 목적 파일 크기 신경 쓰지 않고 수행 시간만 빠르게 함. 모든 함수를 인라인 함수와 같이 취급한다. (Call 인스트럭션은 사용 X. but, 되도록이면 사용하지 않는 것이 좋다. → 너무나 많은 소스의 변경이 가해지기 때문에 왜곡이 발생할 위험이 있다.)
- -O5 옵션 : 사이즈 최적화를 실행한다. (공간이 협소한 곳에서 사용 - 임베디드 시스템)
- -Og : 디버깅 환경이 되도록 최적화. 빠른 컴파일, 좋은 디버깅 환경, 합리적 수준 최적화
최적화 컴파일
machine dependent옵션을 이용한 최적화
:-march={cpu_type} -mutne={cpu-type} -mcpu={cpu-type}:- -march 옵션은 cpu-type으로 지정하는 프로세서의 instructio set으로 코드를 생성한다. 이는 아래에서 설명할 -mtune을 내부적으로 포함하므로 -mtune을 굳이 주지 않아도 무방하다.
- -mtune 옵션은 인스트럭션을 스케쥴링하거나 정렬할 때 해당 CPU에 최적화되게 스케쥴링 및 정렬한다. 이 때에는 CPU 파이프라인 단계, 각 인스트럭션을 수행하는 데 걸리는 사이클, 버스, 캐시 크기 등을 고려한다.
- -mcpu 옵션은 -mtune옵션과 거의 동일하다.
cpu-type으로 generic을 사용할 수 있는데, 이때 -march에서는 사용할 수 없다. 이는 CPU 종류마다 인스트럭션 셋이 다르기 때문이다.
- 프로파일 결과를 이용한 최적화
: 컴파일한 프로그램을 한 번 더 수행해 프로그램의 동작 특성을 파악하여, 이 정보를 바탕으로 다시 컴파일하며 최적화하는 방법이다.
gcc -O2 -o main main.c -fprofile-generate를 통해 main 바이너리에 프로파일 정보를 출력하는 코드가 추가하여 컴파일한다.
$ ./main을 통해 프로그램을 수행한다.
gcc -O2 -o main main.c -fprofile-use를 통해 프로그램을 수행하며 수집한 정보를 바탕으로 좀 더 최적화하여 바이너리를 생성한다. - 레지스터 활용을 통한 최적화
- -fforce-mem: 메모리에 있는 값을 레지스터에 로드해 연산을 수행한다. (GCC 4.2 below)
- -fforce-addr: 메모리 주소 값을 레지스터에 로드 후 연산을 수행한다.
- gcc 컴파일 속도 최적화
- -pipe: 컴파일 과정에서 임시파일을 생성해 전달하지 않고 파이프로 전달해 컴파일 속도를 더 빠르게 한다.
Make, Makefile, CMake, Ninja
Make, Makefile
-
make
- SW 개발을 위한 유닉스 계열 OS 에서 주로 사용하는 빌드 도구
- 파일 간의 종속관계를 파악하여 Makefile( 기술파일 )에 적힌 대로 컴파일러에 명령하여 SHELL 명령이 순차적으로 실행될 수 있게 합니다.
- make 파일 쓰는 이유
- 각 파일에 대한 반복적 명령의 자동화로 인한 시간 절약
- 프로그램의 종속 구조를 빠르게 파악 할 수 있으며 관리가 용이
- 단순 반복 작업 및 재작성을 최소화
-
Makefile
-
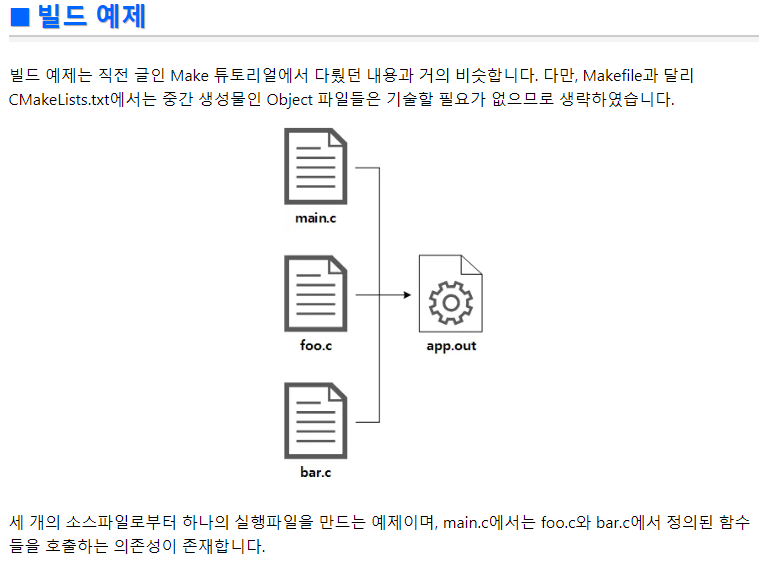
Makefile의 구성- 소스 파일 의존성, 어떤 프로그램을 컴파일하고 링크 할 지 써줘야 함.
- 목적파일(Target) : 명령어가 수행되어 나온 결과를 저장할 파일
- 의존성(Dependency) : 목적파일을 만들기 위해 필요한 재료
- 명령어(Command) : 실행 되어야 할 명령어들
- 매크로(macro) : 코드를 단순화 시키기 위한 방법
-
Makefile 의 기본 구조
-
Makefile 작성규칙
목표파일 : 목표파일을 만드는데 필요한 구성요소들
(tab)목표를 달성하기 위한 명령 1
(tab)목표를 달성하기 위한 명령 2// 매크로 정의 : Makefile에 정의한 string 으로 치환한다.
// 명령어의 시작은 반드시 탭으로 시작한다.
// Dependency가없는 target도 사용 가능하다.
-
Makefile 예제
여기서 더미타겟 은 파일을 생성하지 않는 개념적인 타겟으로
make clean라 명령하면 현재 디렉토리의 모든 object 파일들과 생성된 실행파일인 diary_exe를 rm 명령어로 제거해 줍니다.
이제make로 Makefile을 실행해 줍니다.
-
-
Incremental build
- 반복적인 빌드 과정에서 변경된 소스코드에 의존성 (Dependency) 이 있는 대상들만 추려서 다시 빌드하는 기능. (효율을 위해서 바뀐 .c 파일과 그 파일의 의존성이 있는 파일들만 빌드하는 기능!)
-
Make 개선하기 : 매크로 사용 : 중복되는 파일 이름을 특정 단어로 치환
-
Make 개선하기2 : 내부 매크로 사용 (내부 매크로 훨씬 다양하게 많음)
-
./configure- 소스 파일에 대한 환경 설정 및 준비사항 체크를 해 줌. (필요한 도구는 다 있는지, 라이브러리는 다 있는지 빌드 환경 만들어 줌) 서버 환경에 맞춰서 makefile 을 생성 해 줌. 내 서버가 어떤 기종이고, 컴파일에 필요한 시스템 파일은 어디에 위치해 있고, 어디에 설치 할 지 지정
- configure 옵션은 프로그램마다 조금씩 달라서, 설치 전에 먼저 README, INSTALL 같은 설치 문서를 읽어보는게 좋음
- ex:
./configure --prefix /usr/local/bin로 설치 디렉토리 변경 make distclean치면 configure 설정 모두 제거 해 줌. 다시configure부터 시작하면 됨.- ./configure -> make -> make install (make 를 통해 만들어진 설치파일(setup) 을 설치하는 과정. build 된 프로그램을 실행 할 수 있게 파일들을 알맞은 위치에 복사)
- make clean : make 를 잘못했으면 make clean 으로 원복하고, 다시 make
CMake
-
중간 단계를 일일이 지정해줘야 하는 복잡한
Makefile을 좀 더 편리하게 만들어 줌. 이를 위해서CMakeLists.txt작성해야 함. (Makefile 이 자체적으로 의존성을 파악하고 어느정도 자동화를 해주긴 하지만, Makefile 에 의존성 정보를 정확히 기재해줘야 함) CMake 를 쓰면 의존성 정보를 일일이 기술해 주지 않아도 됨. -
프로젝트 처음 시작 시 Build Step 을 잘 구성해 놓으면, 이후에는 소스 파일 (*.c) 를 처음 추가할 때만 CMakeLists.txt 파일을 열어서 등록해 주면 됨. 이후에는 소스코드를 어떻게 수정하더라도 빌드에서 제외하지 않는 한 스크립트를 수정하지 않아도 됨.
-
CMake 도 Make 와 마찬가지로 의존성 검사를 해서 Incremental Build 를 수행하지만, 가장 큰 차이점은 CMake 는 소스파일 내부까지 들여다보고 분석해서 의존성 정보를 스스로 파악.
-
Makefile 에서는 빌드 중간 생성물인 Object 파일의 이름과 의존성까지 모두 기술해야 하지만 CMakeLists.txt 에서는 최종 빌드 결과물 (실행 바이너리, 라이브러리) 과 이를 빌드하기 위한 소스 파일 만 명시해주면 끝
-
CMake 는 Makefile 의 다소 지저분한 루틴들을 추상화해서 보다 직관적으로 빌드 과정을 기술 해 줌.. 일종의 Meta-Makefile.. 최종 빌드는 Make 와 마찬가지로 make 명령으로 수행. CMake 로 프로젝트 관리하면 CLion, Eclipse 와 같은 범용 IDE 에서 프로젝트 설정 파일로 사용 가능.
-
CMake 예제
-
//CMakeLists.txt ADD_EXECUTABLE( app.out main.c foo.c bar.c )cmake CMakeLists.txt명령어 실행하면Makefile생성 됨.
make명령으로 빌드 -
cmake CMakeLists.txt명령은 자동 생성된 Makefile 을 삭제하지 않는 한 최초 한 번만 실행해 주면 됨. 생성된 Makefile 을 실행 할 때 CMakeLists.txt 파일의 변경 여부를 검사해서 필요한 경우 Makefile 을 자동으로 재생성 해 줌. 즉 cmake 명령은 최초 한 번만 사용.
-
-
CMake 내부 동작
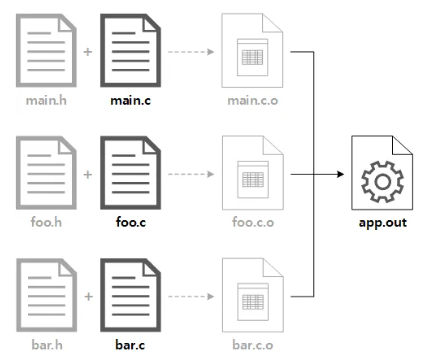
- 헤더 파일, 각 소스 파일을 컴파일한 Object 파일은 명시 할 필요 없이 CMake 가 내부적으로 알아서 처리 해 줌. 아래 그림에서 흐리게 표시한 부분이 CMake 내부적으로 처리됨.
- 참고로 cmake 를 실행하면 프로젝트 디렉토리에 다음 파일, 디렉토리가 자동 생성 됨. .gitignore 에 써버리면 편 함.
Makefile, CMakeCache.txt, cmake_install.cmake ./CMakeFiles/ - make 명령으로 CMake 로 생성한 Makefile 을 실행하면, 가장 먼저
CMakeLists.txt파일이 변경됬는지 여부를 검사하고, 변경 된 경우 Makefile 을 다시 생성하여 실행 - 다음으로 Makefile 에 정의된 각 Target 별로 빌드를 수행, 이 때 내부 Build step 에 따라 cmake 명령으로 각 Target 을 빌드하는 데 필요한 Sub-Makefile 을 생성. 이 때 생성되는 Sub-Makefile 들도 역시 CMakeFiles 디렉토리 내부에 저장됨. 자동 생성되는 Sub-Makefile 들도 의존성 검사를 통해 이전꺼를 재활용하거나 다시 생성.
- 헤더 파일, 각 소스 파일을 컴파일한 Object 파일은 명시 할 필요 없이 CMake 가 내부적으로 알아서 처리 해 줌. 아래 그림에서 흐리게 표시한 부분이 CMake 내부적으로 처리됨.
-
CMakeLists.txt 주요 명령과 변수 정리
- SET() 변수 정의
SET (<변수명> <값>)(값에 공백이 포함된 경우, 큰 따옴표 "..." 로 둘러주면 됨)
- List 변수 정의
- `SET (<목록_변수명> <항목> <항목> <항목> ...) 항목들은 공백 문자로 구분.
- 변수 참조
$변수명 , ${<변수명>}
- 예약 변수
CMAKE_MINIMUM_REQUIRED ( VERSION <버전> ): CMake 빌드 스크립트를 실행하기 위한 최소 버전 명시PROJECT ( <프로젝트명> ): 프로젝트 이름 설정CMAKE_PROJECT_NAME:PROJECT()명령으로 설정한 프로젝트 이름이 이 변수에 저장 됨.CMAKE_BUILD_TYPE: 빌드 형상 지정 (*빌드 형상: 빌드 목적(디버깅,배포) 에 따라 서로 다른 옵션을 지정해서 빌드하는 것으로, 대표적으로 Debug 와 Release 가 있음)- CMAKE 는 기본적으로 4가지 빌드 형상 지원. 사용자 정의 빌드 형상도 지원
- Debug
- Release
- RelWithDebInfo : 배포 목적 빌드지만, 디버깅 정보 포함
- MinSizeRel : 최소 크기로 최적화한 배포 목적 빌드
- 이 변수를 지정하면 Makefile 작성 할 때 빌드 형상에 따라 서로 다른 빌드 옵션을 삽입 해 줌.
- CMAKE 는 기본적으로 4가지 빌드 형상 지원. 사용자 정의 빌드 형상도 지원
MESSAGE( [<Type>] <메시지>):콘솔에 미시지나 변수를 출력. 디버깅 시 활용.- ...
CMAKE_VERBOSE_MAKEFILE:true,1로 지정하면 빌드 상세 과정을 모두 출력SET (CMAKE_VERBOSE_MAKEFILE true)
ADD_EXECUTABLE(<실행_파일명> <소스_파일> <소스_파일>): 빌드 최종 결과물로 생성 할 실행 파일 추가ADD_LIBRARY( <라이브러리_이름> [STATIC|SHARE|MODULE] <소스_파일> <소스_파일> ...): 빌드 최종 결과물로 생성 할 라이브러리 추가
ex :ADD_LIBRARY (app STATIC foo.c bar.c): libapp.a 라는 이름의 라이브러리를 생성INSTALL ():make install명령어 실행 할 때 무슨 동작 수행 할 지 지정.INSTALL ( TARGETS <Target_목록> RUNTIME DESTINATION <바이너리_설치_경로> LIBRARY DESTINATION <라이브러리_설치_경로> ARCHIVE DESTINATION <아카이브_설치_경로> )
SET (CMAKE_INSTALL_PREFIX /usr/bin):make install에서 실행 바이너리, 라이브러리 등의 최종 생성물 복사 할 설치 디렉토리 지정. 지정하지 않으면 default 는/usr/local- ㅁㄴㅇㄹ
- 그 외에도 컴파일 관련 옵션, 전치리기, 헤더, 라이브러리, 링커, Target 관련 옵션 많으나 생략..! 나중에 필요하면 찾아보기
- SET() 변수 정의
-
CMakeLists.txt 스크립트 기본 패턴
# 요구 CMake 최소 버전
CMAKE_MINIMUM_REQUIRED ( VERSION <버전> )
# 프로젝트 이름 및 버전
PROJECT ( "<프로젝트_이름>" )
SET ( PROJECT_VERSION_MAJOR <주_버전> )
SET ( PROJECT_VERSION_MINOR <부_버전> )
# 빌드 형상(Configuration) 및 주절주절 Makefile 생성 여부
SET ( CMAKE_BUILD_TYPE <Debug|Release> )
SET ( CMAKE_VERBOSE_MAKEFILE <true|false> )
# 빌드 대상 바이너리 파일명 및 소스파일 목록
SET ( OUTPUT_ELF
"${CMAKE_PROJECT_NAME}-${PROJECT_VERSION_MAJOR}.${PROJECT_VERSION_MINOR}.out"
)
SET ( SRC_FILES
<소스_파일>
<소스_파일>
...
)
# 공통 컴파일러
SET ( CMAKE_C_COMPILER "<컴파일러>" )
# 공통 헤더 파일 Include 디렉토리 (-I)
INCLUDE_DIRECTORIES ( <디렉토리> <디렉토리> ... )
# 공통 컴파일 옵션, 링크 옵션
ADD_COMPILE_OPTIONS ( <컴파일_옵션> <컴파일_옵션> ... )
SET ( CMAKE_EXE_LINKER_FLAGS "<링크_옵션> <링크_옵션> ..." )
# 공통 링크 라이브러리 (-l)
LINK_LIBRARIES( <라이브러리> <라이브러리> ... )
# 공통 링크 라이브러리 디렉토리 (-L)
LINK_DIRECTORIES ( <디렉토리> <디렉토리> ... )
# "Debug" 형상 한정 컴파일 옵션, 링크 옵션
SET ( CMAKE_C_FLAGS_DEBUG "<컴파일_옵션> <컴파일_옵션> ..." )
SET ( CMAKE_EXE_LINKER_FLAGS_DEBUG "<링크_옵션> <링크_옵션> ..." )
# "Release" 형상 한정 컴파일 옵션, 링크 옵션
SET ( CMAKE_C_FLAGS_RELEASE "<컴파일_옵션> <컴파일_옵션> ..." )
SET ( CMAKE_EXE_LINKER_FLAGS_RELEASE "<링크_옵션> <링크_옵션> ..." )
# 출력 디렉토리
SET ( CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BUILD_TYPE} )
SET ( CMAKE_LIBRARY_OUTPUT_DIRECTORY ${CMAKE_BUILD_TYPE}/lib )
SET ( CMAKE_ARCHIVE_OUTPUT_DIRECTORY ${CMAKE_BUILD_TYPE}/lib )
# 빌드 대상 바이너리 추가
ADD_EXECUTABLE( ${OUTPUT_ELF} ${SRC_FILES} )CMake 프로젝트 구조
project/
│
├── CMakeLists.txt # 최상위 CMakeLists 파일
├── src/ # 소스 코드 디렉토리
│ ├── CMakeLists.txt # 소스 코드 디렉토리의 CMakeLists 파일
│ ├── library1/ # 라이브러리 1 소스 코드
│ ├── library2/ # 라이브러리 2 소스 코드
│ └── executable/ # 실행 파일 소스 코드
├── include/ # 공통 헤더 파일 디렉토리
│ └── mylibrary/ # 라이브러리의 헤더 파일
├── build/ # 빌드 디렉토리 (컴파일된 파일들을 저장)
└── external/ # 외부 종속성 및 라이브러리 디렉토리
├── libraryA/ # 외부 라이브러리 A
└── libraryB/ # 외부 라이브러리 B- src: 프로젝트의 소스 코드를 포함하는 디렉토리입니다. 각 하위 디렉토리는 프로젝트의 라이브러리 및 실행 파일에 대한 소스 코드를 포함합니다.
- executable :
main()함수가 포함된 소스 드 - library : static library, dynamic library 를 만드는 소스 코드
- executable :
- include: 공통 헤더 파일을 포함하는 디렉토리입니다. 이 디렉토리에는 프로젝트에서 사용되는 모든 헤더 파일이 포함될 수 있습니다.
- build: 빌드된 파일들을 저장하는 디렉토리입니다. 이 디렉토리에는 컴파일된 오브젝트 파일, 실행 파일 등이 포함됩니다.
- external: 외부 종속성 및 라이브러리를 포함하는 디렉토리입니다. 이 디렉토리에는 프로젝트에서 사용되는 외부 라이브러리들이 위치할 수 있습니다.
각 디렉토리에는 해당하는 기능을 수행하는 CMakeLists.txt 파일이 포함되어 있어야 합니다. 이 파일들은 프로젝트의 구성을 정의하고 CMake가 프로젝트를 빌드하는 데 필요한 명령을 포함합니다.
CMake 정리 잘 된 블로그
An Introduction to Modern CMake
- TODO : 나중에 보기
- https://cliutils.gitlab.io/modern-cmake/
Ninja
- Make 는 Incremental build 의 안정성을 위해 속도가 느림. 39,000 개의 입력 파일을 컴파일 하는 대규모 프로젝트 같은 경우는 생산성이 매우 떨어짐. -> 속도에 중점을 둔 소형 빌드 시스템인 Ninja 를 대체로 사용.
- Ninja 는 상위 레벨 빌드 시스템 (ex: CMake) 에서 입력 파일을 생성 함.
- 멀티 플랫폼 지원 (리눅스,윈도우,Mac)
- 병렬로 컴파일을 진행
출처 :
- 컴파일러 기초 :
https://bradbury.tistory.com/226- 컴파일러의 이해 (책) :
https://www.yes24.com/Product/goods/24330311?scode=029- 컴파일러 최적화 (내공 있는 프로그래머로 길러주는 컴파이럴의 이해, 요약) :
http://www.kwangsiklee.com/2018/06/%ec%bb%b4%ed%8c%8c%ec%9d%bc%eb%9f%ac-%ea%b0%95%ec%9d%98-9-%ec%bd%94%eb%93%9c-%ec%b5%9c%ec%a0%81%ed%99%94/- Compiler optimizations can be misleading :
https://medium.com/@techhara/compiler-optimizations-can-be-tricky-ee323415e6a- 환경 변수를 사용한 gcc 설정
https://jayy-h.tistory.com/9?_sc_token=v2%253ADJVligtLxXBl1gmGvMuFlPV4b7N8J4WNAPfAN9aCpPmGEMyL8xFiezArvbuZxTpB_CXLDp94HZV78bmcoj8SzDL5aJND38DIy6If1pWWncmgFn-rd532LJgXiWTZKDKysIaUzMcIfEfQN-dRIVgYculidcrUPslIr20tmOnw3ts%253D- gcc 기본 옵션 정리 (가시성 굿)
https://velog.io/@yoopark/gcc-options- make 와 Makefile (정리 잘 되어 있음)
https://bowbowbow.tistory.com/12- configure, make, make install 설명 (정리 잘 되어 있음)
https://positivemh.tistory.com/462- Makefile (상세, 추천)
https://www.tuwlab.com/27193?_sc_token=v2%253AL6oCyG2C256RSPHgRKGXRvashwdyW0w3i5XVjvqITPTBlNym893CLc3rva5AitZv3MvqLPQ8z3260452ycM-l5enMk89lLFyVWAaraqSCm47aSVFrjYtRt0h_7nocAgn5bmfvLRp0lsauUJ42JQCQzY3-xAGOStaqhMN01UYPBU%253D- CMakefile (상세, 추천)
https://www.tuwlab.com/27234
추후 볼 것:
Intel compiler
- Intel oneAPI DPC++/C++ Compiler
- default option :
-fp-model=fastor-ffast-math,-O2,-fveclib=SVML
(Clang default 는-fp-model=precise,-O0) - Alphabetical option list : https://www.intel.com/content/www/us/en/docs/dpcpp-cpp-compiler/developer-guide-reference/2023-2/alphabetical-option-list.html
Optimization options
-fast- Maximizes speed across the entire program
-ipo,-Ofast,-static,-fp-model,fast=2, -xHost를 설정.- agreesive optimization 으로, 컴파일 후 다른 프로세서에서는 실행 안될 수도 있음 (
-xHost옵션 때문에) - default 는 OFF
O2- Inlining of intrinsic
- inlining
- loop unrolling
- 등등
-Ofast-O3보다 더 나아가서, aggresive option 을 설정함.- default 는 OFF
**--x<> - ex :
-xCORE-AVX512** - 특정 feature set 를 사용하여 컴파일하라고 지정 함.
- default 는 off
-ax-x같은건데 더 개선이 있을때만 적용...? (평가해보기)
-march=<>- 특정 processor 를 baseline 으로 사용하여 컴파일하라고 지정 함.
-x랑 뭐가 다른거지..?- default 는 off
--xHost - host processor 에서 highest instruction set 를 사용하여 instruction 을 생성하도록 지시함. (
-x<>,-march,-mtune옵션을 자동으로 실행한다고 보면 됨.) - 다른 아키텍처 프로세서에서는 실행 안될수도 있음
- default 는 off
-mauto-arch=<>- 퍼포먼스 이득이 있으면 x86 archi. 에 맞는 컴파일 실행 (?)
- 값은
ax옵션 값 아무거나 -x, -ax와는 동시 사용 불가
- `-qopt-report<>'
- 입력값 :
0: report 안 함.1: 최소로 report- '2` : 중간정도 report
- '3` : 최대로 report
- default 는 off
--qopt-report-file=<> - 입력값 :
-filename: 파일 이름 입력
-stderr
-stdout출처 :
https://www.intel.com/content/www/us/en/docs/dpcpp-cpp-compiler/developer-guide-reference/2023-2/optimization-options.html
https://hackernoon.com/ko/%EC%B5%9C%EC%86%8C%ED%95%9C%EC%9D%98-%EC%A1%B0%EC%A0%95%EC%9C%BC%EB%A1%9C-%EC%BD%94%EB%93%9C-%EC%84%B1%EB%8A%A5%EC%9D%84-%ED%96%A5%EC%83%81%EC%8B%9C%ED%82%A4%EB%8A%94-%EC%BB%B4%ED%8C%8C%EC%9D%BC%EB%9F%AC-%EC%B5%9C%EC%A0%81%ED%99%94 (추천)
- 입력값 :
Interprodecural optimization
flto- On 되면 whole program link time optimization (LTO) 를 가능하게 함.
- default 는
-fno-lto
--ipo - files 간 interprodecural optimization 가능하게 함.
- On 이 되면 여러 파일 간 하뭇 호출 시에도 inline function expansion 및 interprocedural optimization 이 가능하게 함.
- On 하면
-flto를 자동으로 설정. - default 는
-no-ipo
실제 평가 결과
- Ref. :
-O2, -static -xHost적용 : AVX2(?) 에서 AVX512 사용, 0.6% 속도 개선-ipo적용 : 2.5% 속도 개선-xHost, -Ofast적용 : 2.8% 속도 개선-xHost, -Ofast, -ipo적용 : 3.1% 속도 개선
*Intel Xeon Gold Processor, Single thread 5번씩 반복 실험 진행
Compiler diagnostic options
-Wall- Enables warning and error
-Werror- 모든 warning 을 error 로 변환
-Wshadow,-Wno-shadow- variable declaration 이 이전 declaration 을 hide 할 때 발생
- default 는
-Wno-shadow
OpenMP
-qopenmpoption 으로 OpenMP 사용
Vectorization
Automatic Vectorization
- 컴파일러가 자동으로 SIMD instruction 을 사용 (automatic vectorizer)
- vectorizer 가 sequential operation 을 parallel 로 바꿔줌.
- compiler 가 loop 를 적절하다고 판단해야 vectorization 수행하며, 특정 keyword 나 directives 로 수행 할 수도 있음.
Vectorization Programming Guidelines
- Use
- RHS 에는 Vector data only (array, invariant expression)
- Assignment statement 만 사용
- Avoid
- 함수 호출 (
mathlibrary 호출 제외) (inline 시키면 괜찮음) - Non-vectorizable operation (operation 이 여러 instruction 으로 실행되는 경우)
- Data dependent loop exit condition
- ex:
- 함수 호출 (
void no_vec(float a[], float b[], float c[]) {
int i = 0;
while (i < 100) {
if (a[i] < 50)
// The next statement is a second exit
// that allows an early exit from the loop.
break;
++i;
}
}void no_cnt(float a[], float b[], float c[]) {
int i=0;
// Iterations dependent on a[i].
while (a[i]>0.0) {
a[i] = b[i] * c[i];
i++;
}
}- Guidelines for Writing Vectorizable Code
forloop 에서 exit condition (ex:upper limit) 이 iteration 마다 변하면 안됨.switch,goto,return,if, function call 지양pointer대신에array notation활용- 메모리 접근을 연속적으로
- Favor inner loops with unit stride. (ex : for(i=0;i<N;i+=2)
- Minimize indirect addressing. (indexing 을 2번, ex : x[index[i]])
- nested loop 에서 Array index 를 메모리 연속적으로 부여하기
Array of Structure대신에Structure of Array활용- data dependency 없애기
- vectorization 가능한 intrinsic math functions
acos, acosh, asin, asinh, atan, atan2, atanh, cbrt, ceil, cos, cosh, erf, erfc, erfinv, exp, exp2, fabs, floor, fmax, fmin, log, log2, log10, pow, round, sin, sinh, sqrt, tan, tanh, trunc
Explicit Vector Programming
- vector code 생성에는 다양한 방법이 있음. 아래로 갈수록 명시적.
- Automatic Vectorization
- Auto-vectorization Hints (
#pragma ivdep) - SIMD Vectorization (
#pragma simd) - SIMD Intrinsic (
F32vec4 add) - Vector Intrinsic (
mm_add_ps())
출처 :
https://www.intel.com/content/www/us/en/docs/dpcpp-cpp-compiler/developer-guide-reference/2023-2/vectorization-programming-guidelines.html
https://www.intel.com/content/www/us/en/docs/dpcpp-cpp-compiler/developer-guide-reference/2023-2/user-mandated-or-simd-vectorization.html
GCC compatibility
- Intel compiler 는 GNU compiler 와 호환성이 높음.
- Intel oneAPI C++ 컴파일러는 system 의 GNU tool 을 사용 (ex:
stdio.h와 같은 GNU hearder file, linker, librarries) 따라서 system 의 GCC, G++ version 과 호환이 되야함. 기본적으로PATH환경변수에를 통해 GCC,G++ 를 찾음. 다른 버전의 gcc 를 쓰고 싶으면-gcc-toolchain컴파일 옵션을 활용해서 경로 지정.
Optimization report
- ...
