📌Beautifulsoup install
- conda install -c anaconda beautifulsoup4
- pip install beautifulsoup4
📍html basic
test data html 코드를 작성해보자.
- title
<!doctype html>
<html>
<head>
<title>Very Simple HTML Code by young</title>
</head>
</html>
- body
<!doctype html>
<html>
<head>
<title>Very Simple HTML Code by young</title>
</head>
<body>
<div>
<p class="inner-text first-item" id="first">
Happy young.
<a href="https://velog.io/@zer0" id="zer0-link">zer0</a>
</p>
</div>
</body>
</html>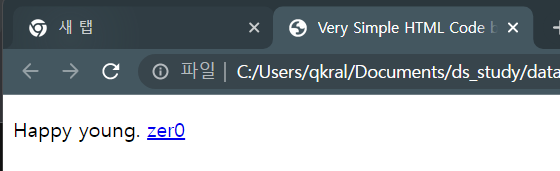
<!doctype html>
<html>
<head>
<title>Very Simple HTML Code by young</title>
</head>
<body>
<div>
<p class="inner-text first-item" id="first">
Happy young.
<a href="https://velog.io/@zer0" id="zer0-link">zer0</a>
</p>
<p class="innter-text second-item">
Happy Data Science.
<a href="https://www.python.org" target="_blink" id="py-link">Python</a>
</p>
</div>
</body>
</html>
target="_blink": 새창에서 이동a href: 링크
<!doctype html>
<html>
<head>
<title>Very Simple HTML Code by young</title>
</head>
<body>
<div>
<p class="inner-text first-item" id="first">
Happy young.
<a href="https://velog.io/@zer0" id="zer0-link">zer0</a>
</p>
<p class="innter-text second-item">
Happy Data Science.
<a href="https://www.python.org" target="_blink" id="py-link">Python</a>
</p>
</div>
<p class="outer-text first-item" id="second">
<b>
Data Science is funny.
</b>
</p>
<p class="outer-text">
<i>All I need is Love.</i>
</p>
</body>
</html>
📌Beautifulsoup
# import
from bs4 import BeautifulSoup📍웹 데이터 가져오기
page = open("../data/03. zerobase.html", "r").read()
print(page)
page = open("../data/03. zerobase.html", "r").read()
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify()) # prettify: 들여쓰기 표현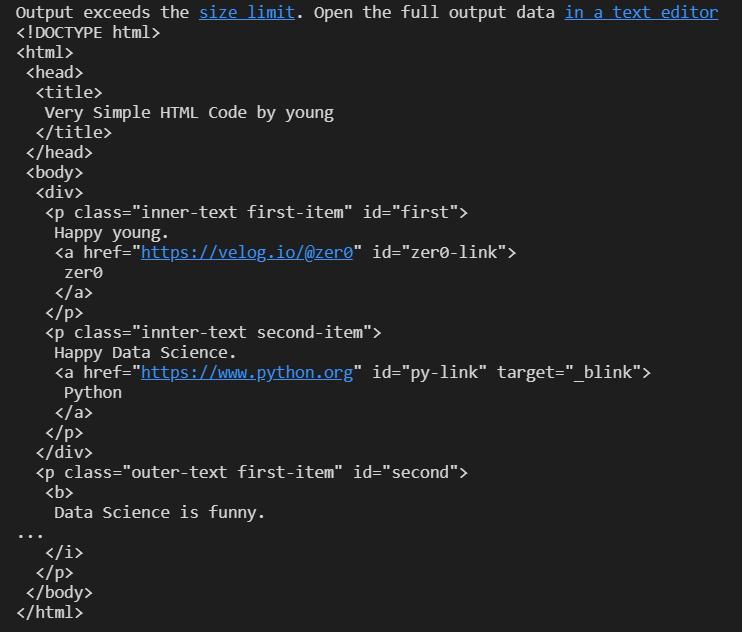
📍태그 가져오기
- head 태그 확인
soup.head
- body 태그 확인
soup.body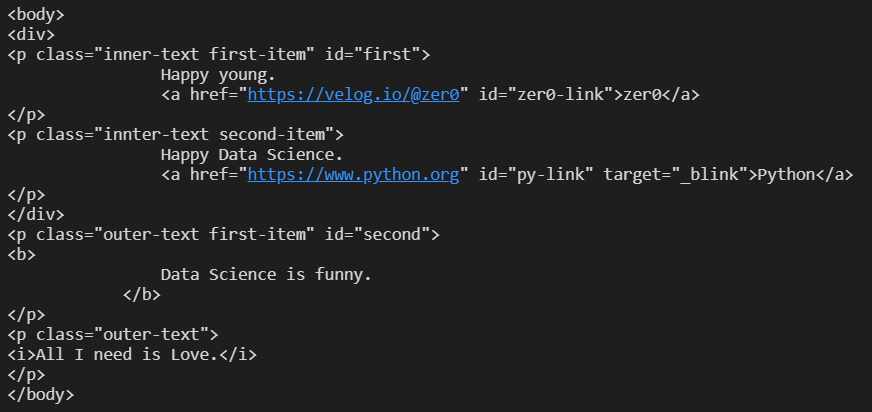
- p 태그 확인
3가지 방법
- 변수.태그
- 변수.find(태그) -> 아래 참조
- 변수.find_all(태그) -> 아래 참조
soup.p
## 📍find(), find_all()
- find()
- 여러개의 p 태그 중 가장 상단에 있는 p 태그 하나만 가져온다.
soup.find("p")
- p 태그 중 class가 "innter-text second-item"
# 파이썬 예약어
# class, id, def, list ,str, int, tuple, ...
soup.find("p", class_= "innter-text second-item")
- p 태그 중 class가 "outer-text first-item"
soup.find("p", {"class": "outer-text first-item"})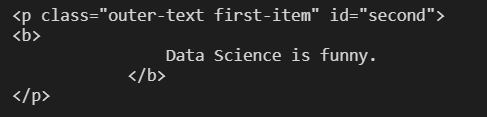
- text만 가져오기
soup.find("p", {"class": "outer-text first-item"}).text.strip() # strip: 공백 지우기
- 다중 조건
p 태그 안에 class 속성값이 "inner-text first-item" 이면서, id 속성값이 "first" 인 것
# 다중 조건
soup.find("p", {"class": "inner-text first-item", "id":"first"})- find_all()
- 여러 개의 태그를 반환
- 리스트 형태로 반환
soup.find_all("p")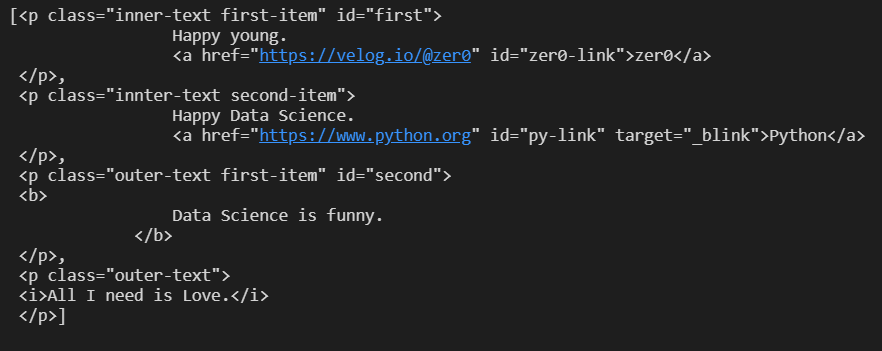
- 특정 태그 확인
soup.find_all(class_="outer-text")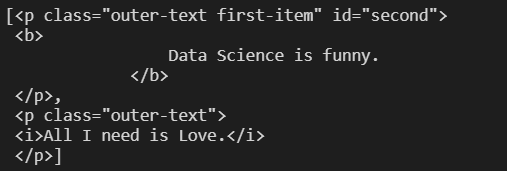
soup.find_all(id="zer0-link")[0].text # 리스트이기 때문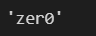
- 텍스트 가져오기
print(soup.find_all("p")[0].text) # 방법1
print(soup.find_all("p")[1].string) # 방법2 -> 안되는거 같은데
print(soup.find_all("p")[2].get_text()) # 방법3
- p 태그 리스트에서 텍스트 속성만 출력
# p 태그 리스트에서 텍스트 속성만 출력
for each_tag in soup.find_all("p"):
print("=" * 50)
print(each_tag.text)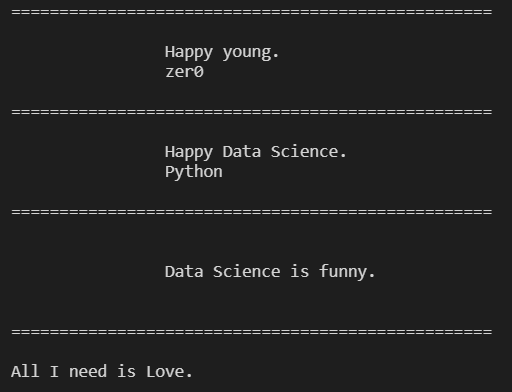
- a 태그에서 href 속성값에 있는 값 추출
links = soup.find_all("a")
print(links)
print(links[0].get("href"), links[1]["href"])
for each in links:
href = each.get("href") # each["href"]
text = each.get_text()
print(text + " => " + href)
📌크롬 개발자 도구 이용하기

📍크롬 개발자 도구 켜기
방법 1: 오른쪽 상단 점 세개 -> 도구 더보기 -> 개발자 도구
방법 2: 오른쪽 마우스 클릭 -> 검사
방법 3: Ctrl + Shift + i
"이 글은 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
