📌Pandas pivot table
- index, columns, values, aggfunc(연산식)
📌index 설정
index="컬럼명"
# Name 컬럼을 인덱스로 설정
# = pd.pivot_table(df, index="Name") # 어떤 데이터, index = 어떤 컬럼을 인덱스로?
df.pivot_table(index="Name")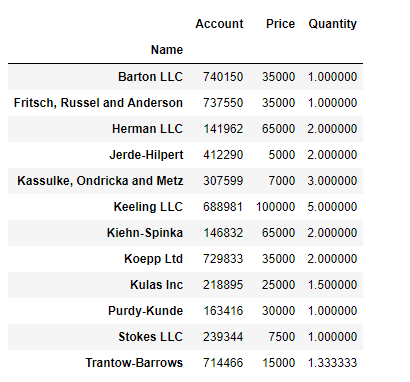
📍멀티 인덱스 설정
# 멀티 인덱스 설정
df.pivot_table(index=["Name", "Rep", "Manager"])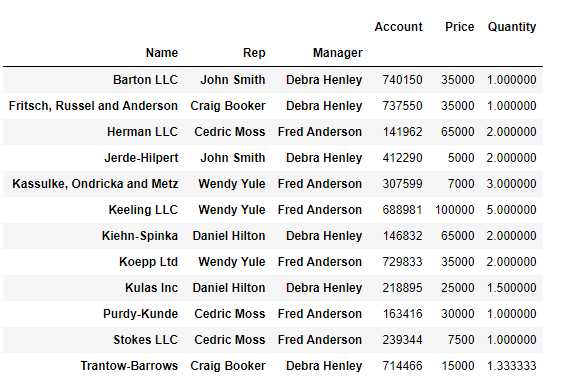
# 멀티 인덱스 설정
df.pivot_table(index=["Manager", "Rep"])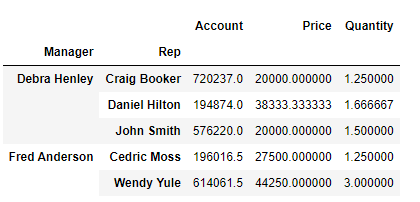
📌values 설정
values="컬럼명"
df.pivot_table(index=["Manager", "Rep"], values="Price")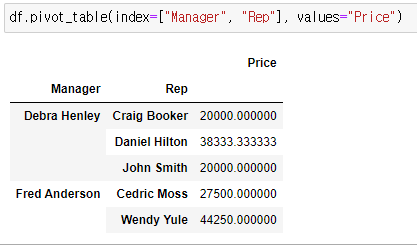
📌aggfunc 설정
aggfunc=연산식
📍Price 컬럼 sum 연산 적용
- 연산 1개
# Price 컬럼 sum 연산 적용
df.pivot_table(index=["Manager", "Rep"], values="Price", aggfunc=np.sum)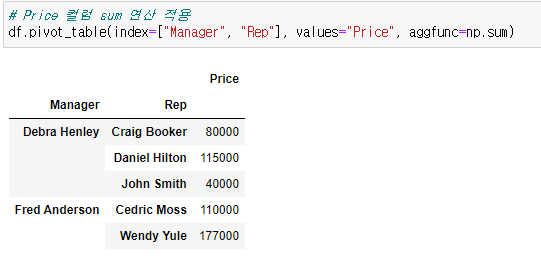
- 연산 2개 이상인 경우
리스트를 감싸서 작성하면 된다.
# Price 컬럼 sum 연산 적용
df.pivot_table(index=["Manager", "Rep"], values="Price", aggfunc=[np.sum, len])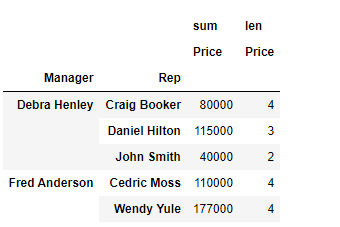
📌columns 설정
columns=컬럼명
📍product를 컬럼으로 지정
# product를 컬럼으로 지정
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum)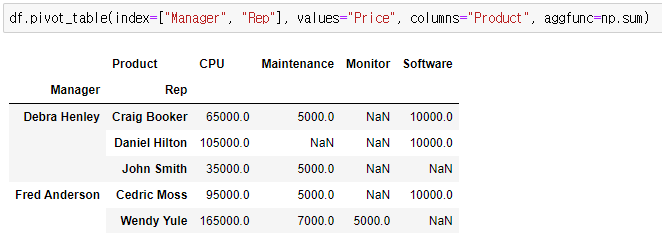
📍NaN 값 설정
fill_value=채울 값
- NaN 값 채우기 전
# product를 컬럼으로 지정
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum)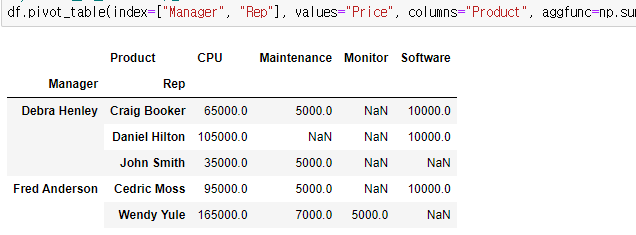
- NaN 값 0으로 채운 후
# NaN 값 설정 : fill_value
df.pivot_table(index=["Manager", "Rep"], values='Price', columns="Product", aggfunc=np.sum, fill_value=0)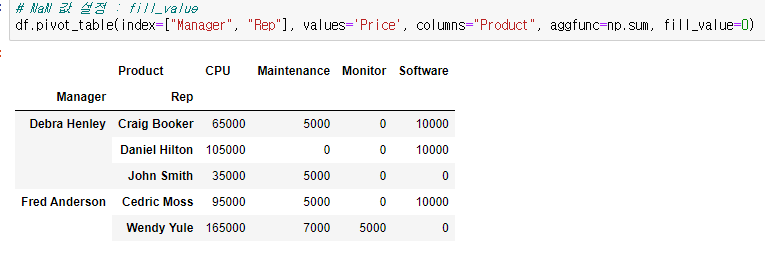
📌2개 이상 index, values 설정
# 2개 이상 index, values 설정
df.pivot_table(index=["Manager", "Rep", "Product"], values=["Price", "Quantity"], aggfunc=np.sum, fill_value=0)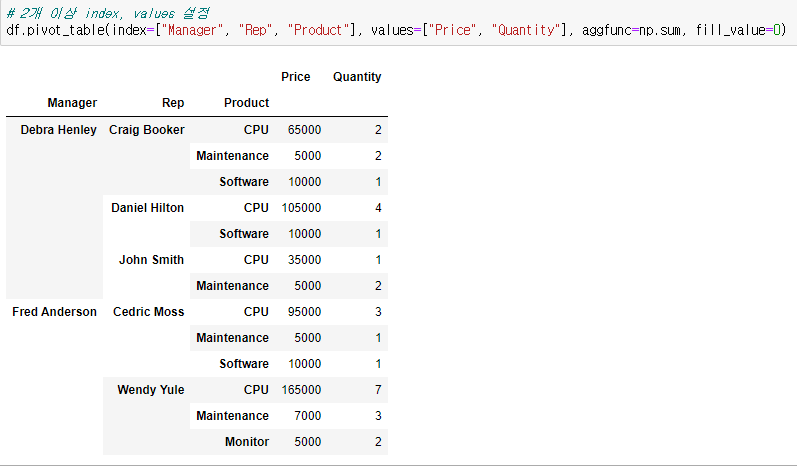
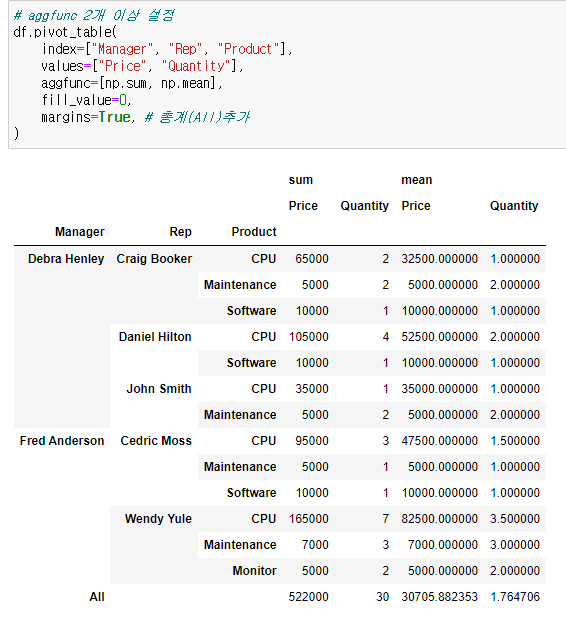
📌aggfunc 2개 이상 설정
# aggfunc 2개 이상 설정
df.pivot_table(
index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=[np.sum, np.mean],
fill_value=0,
margins=True, # 총계(All)추가
)
"이 글은 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
