현존하는 브라우저끼리는 조금씩 특징이 다르지만 공통점이 하나 있다. 그것은 바로 동작방식이다. 브라우저는 사용자가 선택한 자원(Resource)를 서버에 요청(Request)하고, 서버의 응답(Response)을 브라우저에 띄우는(Rendering)방식으로 동작한다. 여기서 자원은 대게 HTML문서이나, 가끔 PDF, 멀티미디어 등 다른 형태일 수 있으며, 자원의 주소는 URL(Uniform Resouce Identifier)로 되어있다.
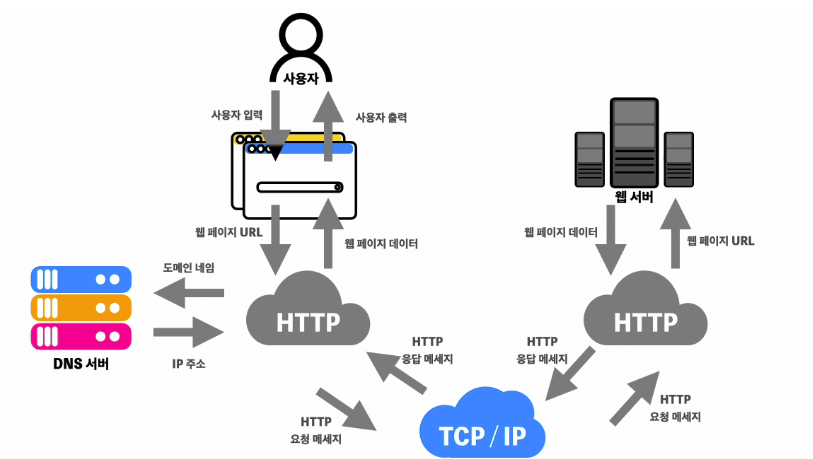
밑에는 웹 브라우저가 웹 사이트에 접속하여 웹 페이지를 가져오는 과정을 도식화한 그림이다.
-
사용자가 웹 브라우저를 통해 찾고 싶은 웹 페이지의 URL주소를 입력한다. 그러면 먼저 URL 정보가 DNS서버로 가게 된다.
-
DNS 서버는 사용자가 입력한 URL 주소 중 도메인 네임을 검색한다. 그리고 해당하는 IP 주소를 찾아 사용자가 입력한 URL 정보와 함께 전달한다.
-
이렇게 웹 페이지 URL정보와 전달받은 IP주소는 HTTP 프로토콜을 사용해 HTTP 요청 메세지를 생성한다. 생성된 HTTP 메세지는 TCP프로토콜을 사용해 인터넷을 거쳐 해당 IP 컴퓨터로 전송되고, 이 요청 메세지는 다시 HTTP 프로토콜을 통해 웹 페이지 URL 정보로 변환된다.
-
웹 서버는 이 변환이 된 정보에 해당하는 데이터를 검색하여 찾아낸 뒤 HTTP 프로토콜을 통해 HTTP응답 메세지를 생성하고, 이 메세지는 다시 TCP 프로토콜을 이용해 인터넷을 거쳐 사용자의 컴퓨터로 전송된다.
-
사용자의 컴퓨터에 도착한 HTTP 응답 메세지는 HTTP 프로토콜을 사용해 웹 페이지 데이터로 변환이 되고, 변환된 데이터는 웹 브라우저상에 출력되어 사용자가 볼 수 있게 된다.
브라우저의 구조
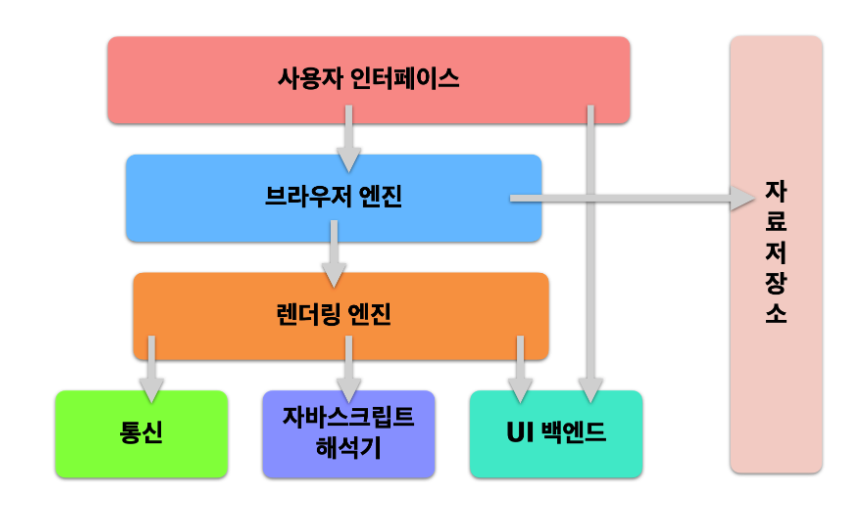
사용자 인터페이스(User Interface)
가장 유저와 밀접하게 맞닿아있는 부분이다. 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등에 관련된 GUI 부분을 통칭한다.
브라우저 엔진(Browser Engine)
사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어한다. 브라우저 엔진의 주된 역할은 HTML 문서와 기타 자원의 웹페이지를 사용자의 장치에 시각 표현으로 변환시키며, 문서 객체 모델(DOM) 자료 구조를 구현한다.
레이아웃 엔진(Layout Engine)라고도 부르며, 렌더링 엔진(Rendering Engine)과 밀접한 연관이 있어 보통은 브라우저 엔진과 렌더링 엔진을 묶어 브라우저 엔진으로 부르나 여기서는 구분해서 표현한다.
이러한 브라우저 엔진은 웹 브라우저 마다 전용 엔진을 사용하고 있다.
렌더링 엔진(Renduering Engine)
요청한 콘텐츠를 화면에 출력하는 역할을 한다. HTML, CSS 등을 파싱해 최종적으로 화면에 그려주며, 렌더링 엔진은 HTML 및 XML문서와 이미지를 표현할 수 있다. (물론 플러그인이나 브라우저 확장 기능을 이용해 PDF와 같은 다른 유형도 표시할 수 있다.)
위에서 기술한 브라우저 엔진과 밀접하게 결합되어 있으므로 보통은 하나의 엔진으로 보는 시각이 많다. 렌더링 엔진 또한 웹 브라우저 마다 전용 엔진을 사용하고 있으나 엔진의 동작 원리는 공통된 부분이 많다.
통신(Networking)
HTTP요청과 같은 네트어크 호출에 사용된다. 보통 플랫폼의 독립적인 인터페이스이고 각 플랫폼의 하부에서 실행된다.
자바스크립트 해석기(JavaScript Interpreter)
현대의 웹 페이지는 이제 JavaScript와 떼려고 해도 뗄 수 없게 되었다. 그 이유는 대부분의 웹 인터렉션(Interaction)에 JavaScript가 사용되기 때문이다.
JavaScript는 코드를 위에서 아래로 한 줄씩 읽어내려가는 방식으로 파싱하는 언어(Interpreted Language)다. 따라서 JavaScript코드를 해석하고 실행하는 자바스크립트 해석기가 필요에 의해 등장하게 되었다.
자바스크립트 엔진이라고도 부르는 자바스크립트 해석기는 여러 목적으로 사용되지만 대체적으로 웹 브라우저에서 이용이 되며, 브라우저 마다 전용 엔진이 탑재되어 있다.
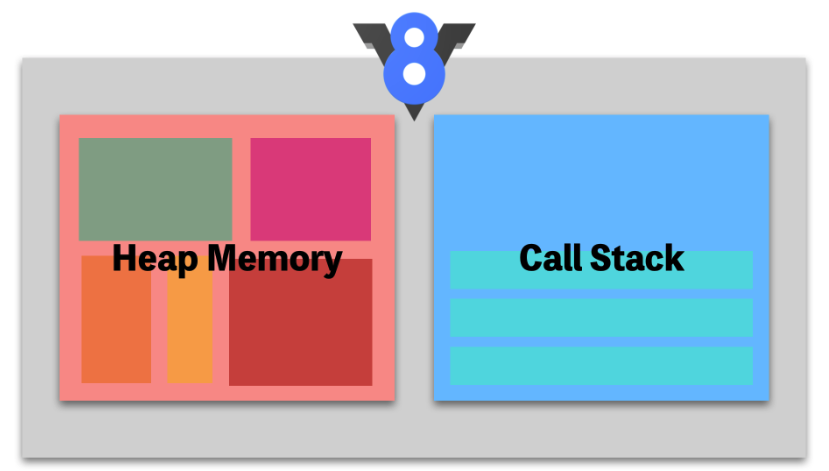
가장 유명한 구글 크롬의 javascipt엔진인 v8은 위처럼 heap memory와 call stack메모리로 구성되어 있다.
Heap Memory
Heap Memory 내부에는 다양한 공간이 있다. 힙은 동적 메모리 할당에 사용되는 자료구조다. 이 자료구조를 이용하여 V8은 객체 또는 동적 데이터를 저장한다. 이 메모리는 V8엔진 내부에서 가장 큰 공간을 차지하고 있으며 가비지 컬렉션 또한 발생하는 곳이다.
Call Stack
JavaScript는 기본적으로 싱글 스레드 기반의 언어다. 콜 스택이 하나라는 의미이며, 한 번에 한 작업만 사용할 수 있다. 콜 스택은 프로그램 상에서 우리가 어디에 있는지 기록하는 자료구조다. 만약 함수를 실행한다면, 해당 함수는 콜 스택의 가장 상단에 위치한다. 이는 스택이라는 자료구조가 후입선출이라는 구조를 가지고 있기 때문에 일어나는 일이다. 함수의 실행이 끝난다면 해당하는 함수는 콜 스택의 가장 상단에 위치하고 있기 때문에 바로 제거할 수 있게 된다. 콜 스택에 쌓이는 호출 스택의 각 단계를 스택 프레임이라고 부른다. 콜 스택이 동작하는 방식을 파악하면 스택의 추적 또한 가능해진다.
이러한 콜 스택은 자료구조 자체가 크기에 제한이 있다. 한정된 메모리 공간을 넘어버리게 되면 어떠한 에러를 발생시키는데, 그것을 바로 스택 오버플로(Stack Overflow)라고 부른다.
function oops() {
return oops();
}
oop();위와 같은 코드를 실행하면 아래처럼 스택 오버플로가 발생할 것이다.
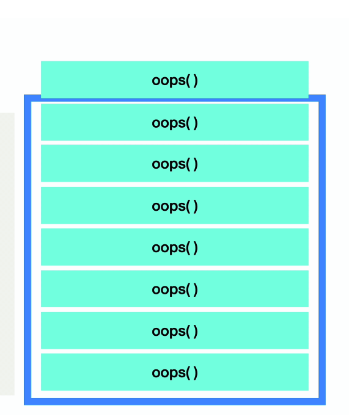
콜 스택을 스택 프레임이 넘어버리게 되면 웹 브라우저는 멈춰버리게 된다. 이는 유저경험(UX)에도 좋지 못하므로, 개발하면서 해당 에러가 발생하지 않도록 주의를 기울여야 할 것이다.
스택 추적 (Stack trace)
function foo() {
throw new Error('오류 발생!');
}
function bar() {
foo();
}
function baz() {
bar();
}
bax();
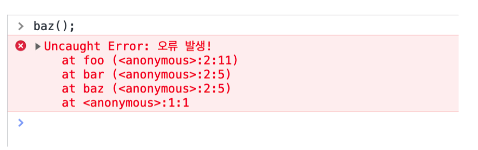
baz()는 함수 bar()를 호출하고 bar()는 함수 foo()를 호출하는데, 마지막으로 에러 메세지를 출력한다. 브라우저의 콘솔 로그를 살펴보면 에러의 발생과 발생한 이유를 훌륭하게 추적해낼 수 있다. 이것이 바로 스택 추적이라고 부르는 것이다.
UI 백엔드
렌더링 엔진이 분석한 Render Tree를 브라우저에 그리는 역할을 담당한다. Select, Input창과 같은 기본적인 위젯을 그려준다. 플랫폼에 명시하지 않은 일반적인 인터페이스로, OS 사용자 인터페이스 체계를 사용한다.
OS 사용자 인터페이스 (user interface)란 기존에 배운 UI/UX와 조금 다르다.
자료 저장소
말 그대로 자료를 저장하는 계층이다. 쿠키를 저장하는 것과 같이 모든 자원의 자원을 하드 디스크에 저장할 필요가 있기 때문에 존재하고 있다. HTML5 명세에는 브라우저가 지원하는 웹 저장소(Web Storage) 스펙에 정의되어 있다. 영구적인 저장소인 로컬스토리지(localStorage)와 임시적인 저장소인 세션스토리지(sessionStorage)를 따로 두어 데이터의 지속성을 구분할 수 있어 응용환경에 맞는 선택이 가능해진다.
웹 스토리지 (Web Storage)의 특징
HTML5 이전에는 응용 프로그램이 서버에 데이터를 요청할 때마다 매번 쿠키(Cookie)라는 곳에 그 정보를 저장해왔다. 그러나 쿠키자체의 보안상 취약과 더불어 저장소의 절대적인 허용 용량의 적음으로 다른 대안을 찾게 되었고, 이윽고 웹 스토리지가 나오게 되었다.
웹 스토리지는 웹 브라우저가 직접 데이터를 저장할 수 있게 해준다. 또한 웹 스토리지는 사용자 측에서 좀 더 많은 양의 정보를 안전하게 저장할 수 있게 해준다. 이런 모든 정보는 절대 서버로 전송되지 않으므로 저장된 데이터가 클라이언트에만 존재하기 때문에 네트워크 트래픽 비용 또한 줄여준다는 특징도 가지고 있다.
이러한 웹 스토리지는 오리진마다 단 하나씩만 존재한다. 오리잔(origin)은 도메인(domain)과 프로토콜(protocol) 한 쌍으로 이루어진 식별자로, 하나의 오리진에 속하는 모든 웹 페이지는 같은 데이터를 저장하기 때문에 같은 데이터에 접근할 수 있게 된다.
이런 웹 스토리지는 사용하기 전에 사용자의 웹 브라우저 버전이 이를 지원하는지 먼저 확인을 해봐야 한다.
웹 스토리지 종류
웹 스토리지는 데이터의 지속성과 관련해 두 가지 용도의 저장소 객체를 제공한다.
로컬 스토리지(local Storage)
로컬스토리지 객체는 보관 기한이 없는 데이터를 저장한다. 따라서 브라우저 탭이 닫히거나, 컴퓨터를 재부팅해도 이 저장소에 저장된 데이터는 사라지지 않는다. Windows 전역 객체의 localStorage라는 컬렉션을 통해 저장과 조회가 가능하며, 도메인 마다 별도의 localStorage가 생성된다. 따라서 도메인만 같으면 전역으로 데이터의 공유가 가능해진다.
세션 스토리지(session Storage)
세션스토리지 객체는 하나의 세션만을 위한 데이터를 저장한다. 데이터를 지속적으로 보관하지 않고, 브라우징되고 있는 브라우저 컨텍스트 내에서만 데이터가 유지되기 때문에, 사용자가 브라우저 탭이나 창을 닫으면 이 객체에 저장된 데이터는 사라진다. 브라우징이란 브라우저 프로그램을 실행해서 인터넷에 들어가 필요한 정보를 찾는 행위를 말하며, 브라우저 컨텍스트란 브라우저가 문서를 표시하는 환경을 말한다. 각 브라우징 컨텍스트는 특정 출처 및 활성화 되고 있는 문서의 출처, 표시했던 모든 문서의 방문 기록을 가지고 있다.
저장과 조회는 windows전역 객체의 sessionStorage라는 컬랙션을 통해 이루어지며, 도메인 별로 별도로 생성되는데 브라우저가 다르면 서로 다른 영역이 된다는 특징이 있다. 즉, 브라우저 두 개를 실행해 같은 페이지를 열었을 때, 브라우저 컨택스트가 서로 다르므로 이 두 페이지의 sessionStorage는 각 별개의 영역으로 인지되어 서로 데이터의 공유가 불가능해진다.
웹 스토리지를 활용한 대표적인 기능
웹 스토리지를 활용한 대표적인 기능은 다양하게 존재한다. 먼저, 브라우저 컨텍스트 내에서 저장한 데이터를 가지고 활용할 수 있기 때문에 복구 및 백업에 관련된 기능에 주로 사용이 된다.
- 블로그 글을 작성하다가 사용자가 창을 벗어난 경우 관련 작성 내용을 복구하거나 백업해주는 기능
- 사용자가 입력 form을 통해 정보를 입력하다 페이지에서 벗어난 경우 복구 및 백업해주는 기능
- 현재 읽은 글의 히스토리 저장(카운팅, 혹은 읽은 글 표시 등으로 활용)
브라우저 렌더링
브라우저 렌더링에서 렌더링(rendering)이란 HTML, CSS, JavaScript등 개발자가 작성한 문서가 브라우저에서 출력되는 과정을 의미한다. 현존하는 브라우저마다 다르지만, 브라우저는 기본적으로 렌더링을 수행하는 렌더링 엔진을 가지고 있다.
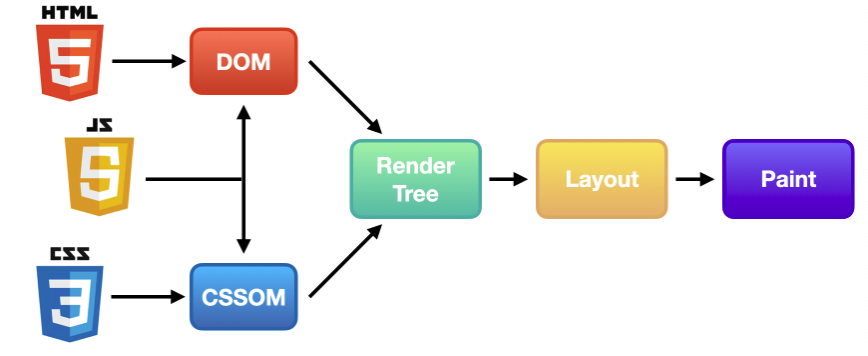
- 사용자가 브라우저를 통해 웹 사이트에 접속한다.
- 브라우저는 서버로부터 HTML, CSS, JavaScript와 같은 웹사이트에 필요한 리소스를 다운 받습니다.
- 렌더링 엔진은 전달받은 HTML 문서를 파싱(parsing)해 DOM(Document Object Model, 문서 객체 모델) 트리를 만든다.
- 이어서 다운 받은 외부 CSS 파일과 함께 포함된 스타일 요소를 파싱(parsing)해 CSSOM(CSS Object Model, CSS 객체 모델) 트리를 만든다.
- 만든 DOM 트리와 CSSOM 트리를 결합해 Render 트리를 구축한다.
- 레이아웃 과정을 통해 각 요소를 어디에 배치할 지 결정한다.
- 레이아웃 과정이 끝나면 UI 백엔드에서 Render 트리를 화면에 그리기 시작한다. 이 과정을 paint라고 한다.
파싱(Parsing)
파싱이란 프로그래밍 언어로 작성된 파일을 실행시키기 위해 구문 분석(syntax analysis)을 하는 단계다. 이런 파싱을 파서(parser)가 진행하며, 일종의 인터프리터나 컴파일러 구성 요소 가운데 하나다. 파서는 HTML 파일의 코드를 문법적 의미를 갖는 최소 단위인 토큰(token)으로 한 번 분해하고, 이 토큰들을 문법적 의미와 구조에 따라 노드(node)라는 요소로 바꾼다. 노드들은 상하관계에 따라 하나의 트리를 형성하는데 이를 파스 트리(parse tree), 혹은 문법 트리(syntax tree)라고 부른다.
문서 파싱(document parsing)은 브라우저가 코드를 이해하고 사용할 수 있는 구조로 변환하는 것을 의미한다. 렌더링 과정에서는 HTML 파일을 바탕으로 DOM 트리를 구축하고 및 CSS 파일로 CSSOM 트리를 만드는 것을 파싱한다고 표현한다.
브라우저는 HTML 문서를 받아들자마자 DOM 트리로 파싱한다. 파싱되며 HTML 토큰이 만들어지는데, 이 토큰에는 시작태그와 마침태그가 포함되고, 속성 이름과 값도 포함이 된다. 이런 토큰화된 입력값은 파서에 의해 노드가 되고, DOM 트리를 구성된다.
브라우저는 HTML 문서를 파싱하면서 CSS스타일을 만날 경우 텍스트를 CSS 스타일링 레이아웃과 페인팅에 사용하는 데이터 구조인 CSSOM 트리로 파싱하고, 태그를 만날 경우 렌더링을 차단하면서 HTML 파싱 또한 중단한다. 이어 script 파일을 다운 받아 파싱하고 실행시킨 뒤 다시 HTML 파일을 파싱하기 시작한다.
파싱은 문서에 작성된 언어 또는 형식의 규칙에 따르는데 파싱할 수 있는 모든 형식은 정해진 용어와 구문 규칙에 따라야 한다. 따라서 형식을 잘 갖춘 문서라면 파싱 과정은 직관적이고 빠르게 진행된다.
DOM Tree
DOM은 HTML문서의 요소들의 중첩 관계를 기반으로 노드들을 트리 구조로 구성한 것을 의미하며, Document Object Model의 줄임말이다. 브라우저는 JavaScript 언어만 알아듣기 때문에 HTML의 태그나 속성들을 이해하지 못합니다. 또한 응답으로 받아온 HTML 문서는 텍스트로만 이뤄져 있습니다. 그래서 이해할 수 있는 형태인 객체로 바꿔준 것이 바로 DOM 트리다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="code.css">
<title>text</title>
</head>
<body>
<h1>text</h1>
<p>text <span>text</span>과 <span>text</span> text.</p>
<section>text</section>
</body>
</html>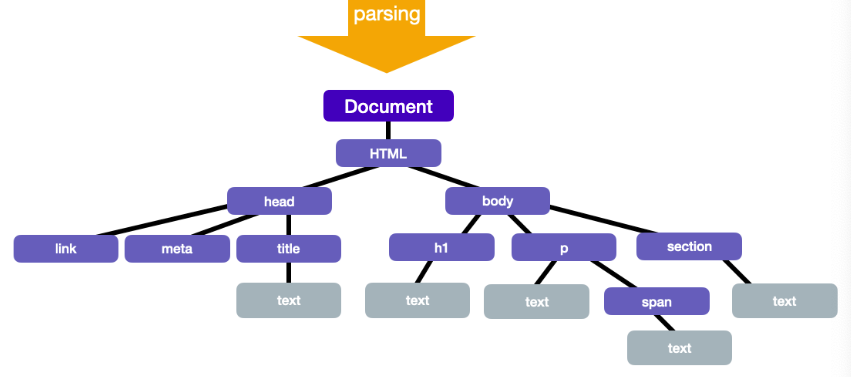
CSSOM Tree
html 파일을 DOM 트리로 파싱하던 브라우저는 link, style 태그를 만나게 되면 파싱을 잠시 멈추고 해당 리소스 파일을 서버로 요청한다. 이렇게 요청한 파일을 html 파일과 마찬가지로 파싱을 하는데, 파일을 파싱해 만든 트리를 CSSOM이라고 한다. CSS Object Model의 줄임말이며, 이 CSSOM 트리를 구축하고 나면 브라우저는 다시 html 파일의 파싱을 멈췄던 부분으로 돌아가서 마저 DOM 트리를 파싱한다.
body {
font-size: 16px;
}
h1 {
color: blue;
}
p {
font-weight: bold;
}
p span {
color: rad;
}
section {
display: none;
}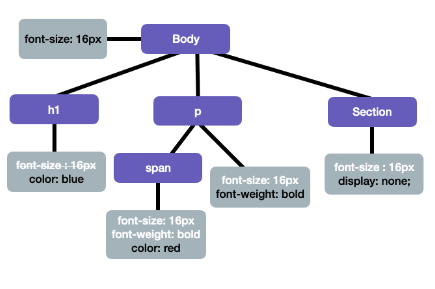
하나 알아둬야 할 부분은 CSS는 부모의 속성을 자식이 상속 받는다는 점이다. 예를 들어 body가 부모 요소이고 font-size가 16px인 속성을 가지고 있는데, 그 밑에 있는 p는 자식 요소이기 때문에 부모 요소인 body가 갖고 있던 속성을 상속 받으면서 동시에 자신이 가지고 있는 속성인 font-weight 속성까지 가지므로 2개의 속성을 갖게 된다는 점이다.
렌더 트리 (Render Tree)
DOM 트리와 CSSOM 트리는 트리 구조로 되어 있기 때문에 비슷하게 생겼지만, 애초에 리소스부터 틀린 서로 다른 속성을 가진 독립적인 트리다. 그렇기 때문에 브라우저 위에 웹사이트를 표시하기 위해서는 이 둘을 합치는 작업이 반드시 필요하다.
렌더 트리는 이름처럼 렌더링을 목적으로 만들어지는 트리다. 렌더링은 사용자에게 브라우저가 보여주고자 하는 화면을 그리는 과정이므로, 보이지 않을 요소들은 이 트리에 포함시키지 않는다.
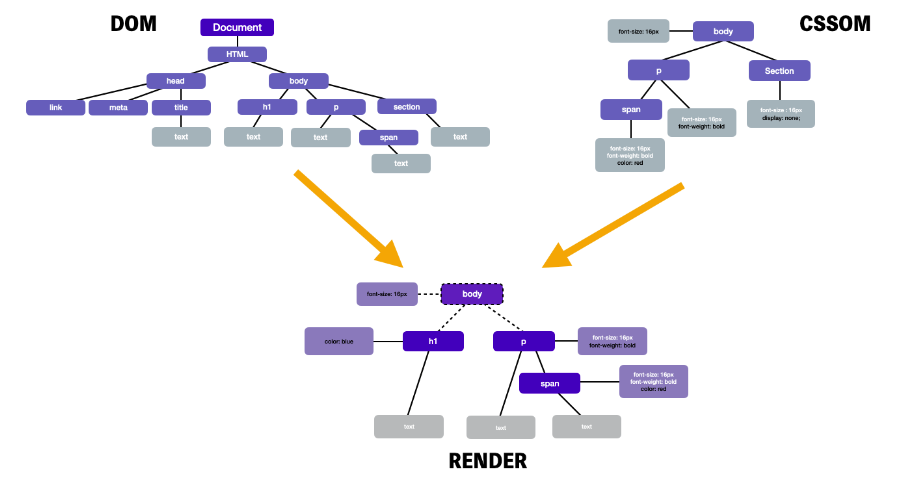
예를 들어 DOM 트리의 meta나 CSSOM 트리의 display:none과 같이 사용자에게 보여주지 않아도 되거나, 보여주지 말아야 할 태그나 요소는 렌더 트리에서 제외가 된다.
레이 아웃
브라우저 렌더링에서 “레이아웃” 과정은 우리가 웹 개발에서 평소 말하는 웹 페이지 레이아웃 짜기, 디자이너들의 레이아웃과는 다른 개념이다. 여기서 말하는 레이아웃은 렌더트리를 기반으로 HTML 요소의 레이아웃(위치, 크기 등)을 계산하여 브라우저 화면 어디에 배치할 지 결정하는 과정이다.
위의 그림에서도 볼 수 있듯이 DOM, CSSOM에 있던 속성들이 합쳐서 렌더 트리를 구성하는 것을 볼 수 있다. 그러나 아직까지 렌더 트리는 텍스트로 구성된 객체로만 보인다. 페인팅이라는 작업을 거쳐야지 브라우저 위의 화면으로 그려지게 된다.
렌더 트리에는 CSSOM 트리에 있던 속성들이 합쳐져 있다. 따라서 렌더 트리에는 요소들의 크기, 혹은 위치에 관련된 정보들이 들어 있습니다. 하지만 아직까지 이 정보들은 그저 각 요소에 관련된 정보일 뿐, 전체 화면에서 정확히 어디에 위치하는가에 대해서는 알지 못한다. 이런 계산을 브라우저의 렌더링 엔진이 합니다. 브라우저는 각 요소들이 전체 화면에서 어디에, 어떤 크기로, 어떻게 배치가 되어야 하는지 파악하기 위해 렌더트리를 위에서 아래로 읽어 내려간다. 그리고 모든 값은 절대적인 단위인 px 값으로 변환된다.
페인팅
위치에 대한 계산을 마치면 이제 화면에 보여주기 위해 브라우저는 화면 위에 레이아웃에서 결정된 대로 그림을 그리기 시작한다. 브라우저 화면은 픽셀이라고 하는 작은 점들로 구성되어 있다. 각 정보를 가진 픽셀들이 모여 하나의 화면을 구성하는 것이다. 페인팅은 이런 픽셀에 대한 정보들을 바탕으로 픽셀을 채워나가는 과정이며, 이 과정까지 해내야 텍스트에 불과했던 HTML 파일의 내용들이 이미지화된 모습으로 브라우저 화면에 띄워지는 것이다.
리플로우와 리페인트
만약에 사용자가 브라우저 화면을 늘리거나 줄이는 등 크기를 조절하거나, 다른 사이트로 이동을 하는 등 화면에 요소가 추가 되거나 삭제, 혹은 아예 다른 요소들을 불러와야 하는 상황이 생기면 당연히 화면에 있던 요소들의 크기가 바뀌게 된다.
사용자의 입장에서는 당연한 과정이지만, 이렇게 화면에 나타나는 모습을 바꾸기 위해서는 모든 요소의 위치와 크기를 다시 계산하고, 다시 그려 보여주어야 한다. 이런 식으로 어떤 웹 인터랙션으로 인해 앞서 보았던 렌더링 과정의 레이아웃을 반복해 수행하는 것을 리플로우, 페인트 과정을 반복해 수행하는 것을 리페인트라고 한다.
리플로우와 리페인트의 최적화
사용자의 눈에 일련의 과정이 부드럽게 처리 되려면 초당 60 프레임은 반드시 유지시켜야 한다. 이는 TOAST에서 WebRender를 소개하면서 나오는 개념이기도 하다.
1초라는 짧은 시간 안에 브라우저는 60장 가량의 레이아웃과 페인트 과정을 동시에 처리해야만 하는 것인데 여기서 중요하게 알아야 하는 점은 DOM은 변경이 되면 렌더 트리를 다시 구축하기 때문에, 변경이 될 때마다 리플로우와 리페인트를 다시 해야 한다는 것이다. 리플로우 하는 과정은 렌더링을 다시 하는 것이기 때문에 배치를 위한 연산을 해야 해 실제로 CPU를 많이 차지하고, 리페인트는 페인트를 다시 하는 것이라 픽셀을 다시 화면에 찍어 그려야 하기 때문에 GPU를 많이 차지한다. 그렇기 때문에 프레임 드랍(Frame Drop) 현상과 직접적인 연관이 있다.
프레임 드랍은 초당 60프레임으로 유지시키던 프레임의 수가 브라우저의 과부하로 인해 줄어드는 현상을 뜻한다. 줄어들어 드랍, 즉 없어진 프레임은 렌더링 엔진이 인식할 수 없다. 렌더링 엔진은 드랍된 프레임을 브라우저 화면에 그리지 못한다. 이렇게 되면 유저는 해당 현상을 "화면이 멈춘다, 버벅인다" 라고 느끼게 된다. 프레임 드랍 현상이 생기면 유저 경험(UX)에 좋지 않기 때문에, 최적화를 고려해야만 한다.
어떻게 최적화를 시킬 수 있을까?
불필요한 레이아웃을 줄인다.
레이아웃 과정에서 불필요하게 계산해야 할 것이 많아지면 엔진도 결국 컴퓨팅 파워에 기대기 때문에 과부하가 불가피하게 생기게 된다. 따라서 불필요한 레이아웃 하나만 줄여도 렌더링 퍼포먼스를 최적화할 수 있다. CSSOM 트리의 CSS 속성 중에 레이아웃을 발생시키는 속성들이 존재하고 있다. 이 속성을 사용하게 되면 그때마다 변경이 되어 렌더 트리를 만들고, 레이아웃을 발생시키고, 페인트를 하는 과정이 연속적으로 발생한다. 따라서 이런 레이아웃을 발생시키는 속성을 피하면 해당 과정이 발생하는 횟수를 줄일 수 있다.
CSS에서 레이아웃, 페인트를 발생시키는 속성들
레이아웃과 페인트 과정은 별개의 과정처럼 보일 수 있으나 리플로우 시 리페인트는 필연적으로 일어나므로 가능하다면 리플로우가 발생하는 속성보다 리페인트만 발생하는 속성을 사용해주는 게 좋다.
페인트 과정은 유저에게 화면을 보여주기 위해 그리는 과정이라 필수적인 과정이기 때문이다. 따라서 프론트엔드 개발자가 되어 브라우저 렌더링의 최적화 과정을 수행하고자 한다면 레이아웃이 일어나는 상황을 최대한 피하는 것이 좋기 때문에 해당 속성을 알아두는 것이 굉장히 중요하다.
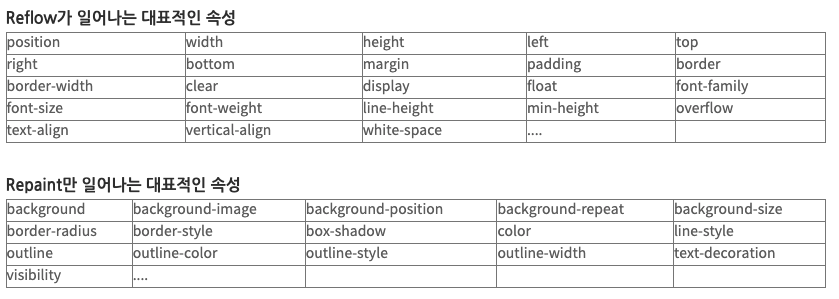
리플로우가 일어나는 대표적인 속성은 대게 위치 혹은 너비와 관련된 속성이 많다. letf속성 중 left-top, left-bottom속성을 사용하면 위치가 변경된다.(position 속성과 같이 쓴다.) 이 left속성은 레이아웃을 발생시키는 속성이다. 따라서 이 속성을 가지고 애니메이션을 만들 때는 프레임 유지를 보장하기 어려워진다.
그래서 이 속성을 피해 transform이라는 속성을 사용한다. transform에 있는 translate를 사용하면 좌표 값을 사용해 위치를 이동하지만, 레이아웃을 발생시키지 않기 때문에 페인트만 다시 발생시키는 쪽으로 렌더링 과정이 일어나기 때문에 유지하고자 하는 프레임 수를 기대할 수 있다.
리페인트가 일어나지 않게 해주는 opacity라는 속성도 있다. visibility/display보다 opacity를 사용하는 것이 성능 개선에 도움이 된다.
영향을 주는 노드를 줄인다.
JavaScript + CSS를 조합한 애니메이션이 많거나, 레이아웃 변화가 많은 요소의 경우 position을 absolute 또는 fixed를 사용해주면 영향을 받는 주변 노드들을 줄여줄 수 있다. fixed와 같이 영향을 받는 노드가 전혀 없는 경우 리플로우 과정이 필요 없기 때문에 리페인트 연산 비용만 들일 수 있다.
최근 모던 웹 브라우저는 성능이 매우 뛰어나므로 대부분의 경우 크게 성능 개선을 고려할 필요성을 느끼지 못한다. 하지만 프론트엔드 개발을 하다보면 다양하고 복잡한 요구 사항에 대응해야 하는 경우도 많아지고, 화면이 라이브 데이터에 따라 실시간으로, 빠르게 수많은 변경을 일으켜야 하는 경우도 생기게 된다.
