(썸네일출처:https://dev-kani.tistory.com/1)들어가며... (editing...)
컴퓨터의 자료 구조에는 key와 value를 가진 key-value 데이터가 존재한다.
여기서 key는 어떤 값의 기준(?)이 되고 이 기준에 해당하는 값은 key의 value가 된다.
🚧 주의사항
하나의 key에는 하나의 value만 있어야 한다
Direct Access Table
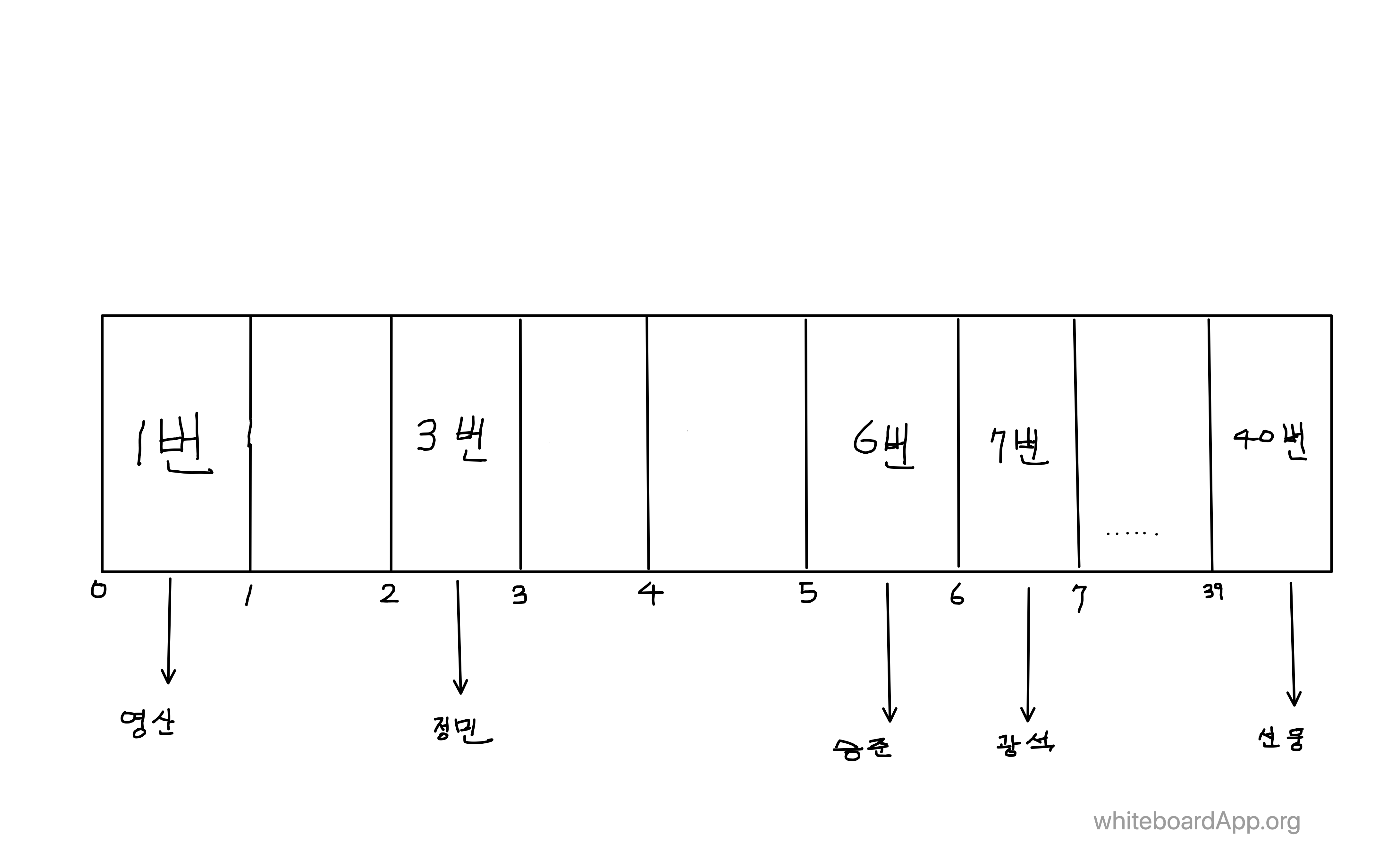
다음 그림은 40명이 한 학급을 형성하는 클래스의 출석부를 테이블 형태로 나타낸 것이다.
그림과 같이 배열 형태의 테이블에 각 인덱스에 key가 되는 번호와 그 번호에 해당하는 value값인 이름이 저장되어있다.
이와 같이 인덱스를 이용한 value 접근이 가능하도록 데이터를 저장하는 형태를 Direct Access Table이라고 한다.
그림에서 보여지는 바와 같이 출석 인원은 5명이지만 테이블을 구성하는 데이터 공간은 40개이다.
다시 말해, 실제로 데이터를 저장하는 공간은 5개이고 나머지 35개의 공간은 낭비가 된다는 것이다.
☛ 효율적으로 key와 value 쌍을 관리할 수 있지만
☛ 낭비하는 공간이 많다.
🧩 key-value 데이터를 효율적으로 관리하는 방법은 ???
이와 같은 근본적인 문제에 의해서(?) 해시테이블과 해시함수가 탄생하게 되었다고 생각한다.
☛ key-value 데이터를 어떻게 저장할까
☛ 저장한 데이터의 value를 어떻게 찾을까
🎯 해시테이블과 해시함수
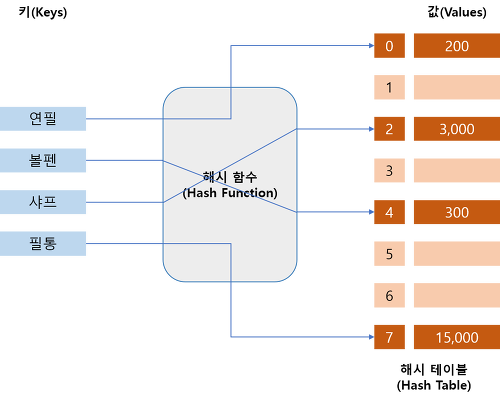
해시함수의 개념
특정 값을 원하는 범위의 자연수로 바꾸어 주는 함수 ( 여기서 나오는 자연수로 해시테이블의 데이터에 접근 )
해시테이블의 개념
해시함수와 배열을 같이 사용하는 자료구조
키를 바로 인덱스로 사용하지 않고 해시함수에 넣어 리턴된 값을 인덱스로 사용
📌 고정된 크기의 배열을 만든다
📌 해시함수를 이용해 key를 원하는 범위의 자연수로 바꾼다.
📌 해시함수의 결과 값 인덱스에 key-value 쌍으로 저장한다.
📌 해시테이블에서 인덱스에는 bucket이 존재한다.
📌 bucket은 linked list 형태이다.
