
광운대학교 공영호교수님 GPU컴퓨팅 듣고 수업 내용 정리한 것입니다.
Nvidia GeForce 8 series 부터 GPU Computing architecture가 확립되었다.
SPA : Streaming Processor Array
TPC를 여러개 묶은것이다.
TPC : Thread Processor cluster or Texture Processor Cluster
픽셀 쉐이딩, 빛반사, 컬러, 질감 처리에 특화된 프로세서
2 SM + TEX로 이루어짐
SM : Streaming Multiprocessor
Thread block의 연산 단위이다. block이 SM에 맵핑된다고 보면 된다.
SP : Streaming Processor
CPU의 ALU라고 생각하숑
하나의 Thread 연산 단위이다.
SFU : Special Function Unit
가속기... sin, cos, square, root 등의 연산을 수행한다. 한 clock에!
한 SM에 32개의 SP들이 있다. 최근에는 128개까지도 있는 것도 있고 64개 짜리도 있다.
SM = 32 cores + 8 SFU + 2 TEX 를 갖는다.
Thread and Warp
Warp는 32개의 thread를 의미한다.
SM은 한번에 2048개까지 Thread를 품을 수 있다.
실제로 한 타임에 동시에 수행할 수 있는 thread는 32개다.
만약 sp가 64개면 한 타임에 두 개의 warp를 수행할 수 있을 것이다.
Block
하나의 block에 1024개의 thread를 가질 수 있다.
1x1024, 2x512, 4x128 등.. 3차원으로도 표현 가능하다. 다만 z값은 64로 제한되어 있다.
모든 스레드들은 동일한 커널 함수를 수행한다.
각 thread block은 32개의 thread를 가지는 Warp단위로 나뉘어진다.
1024개의 thread를 갖는 block 있다면, 이들을 일단 32개로 나눈다. (= warp 단위로 나눔) 그리고 그것들을 SM에 할당해서 warp scheduling을 통해 수행한다.
즉, 한 warp가 메모리 access를 한다? 이때 메모리 access는 300 cycle정도 걸린다. 그럼 메모리에서 데이터가 올 때까지 계속 기다리면 낭비다. 그래서 다른 warp로 전환하고 데이터가 도착하면 다시 warp로 전환한다.
Scenario 1
하나의 SM에 3개의 block을 할당.
각 block은 256개의 thread를 가진다.
몇 개의 warp가 있을까?
한 block에서 나오는 warp의 개수 : 256/32 =8개
3 개의 block 을 가짐 : 8 * 3 = 24
총 24개의 warp를 가진다.
어떤 한 time에서! 그냥 딱 시간을 멈춰버린거야. 그때는 24개 중 하나의 warp만 수행한다. (만약 sp가 64개면 2개의 warp를 수행할 수도 있다.)
SM Warp Scheduling
zero - overhead Warp scheduling!
New Architecture
1 clock cycle needed to dispatch the same instruction for all threads in a Warp in G80
warp안에 있는 thread들에게 명령어를 보내는데 한 클락 싸이클이 요구된다.
평균적으로 4개의 명령어를 수행할 때 마다 global memory access를 하게된다.
그래서 최소 25개의 Warp가 있어야 100 cycle memory latency를 감당하여 성능저하가 없다.
why?
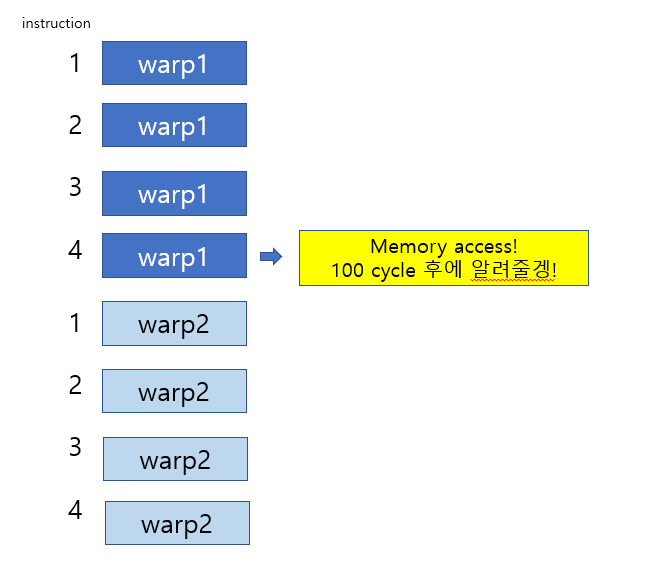
근데 이렇게 되면 25개가 아니라 26개의 Warp가 필요한 것 아닌가? 25개가 있다면, 나머지 24개가 4cycle돌면 총 96cycle... 그러면 4cycle 동안 놀게되는데요?
Old Architecture:
SM = 8 SPs
각 SP에 4개의 thread가 할당된다.
4 clock cycle needed to dispatch the same instruction for all threads in a Warp in G80
warp안에 있는 thread들에게 명령어를 보내는데 4 클락 싸이클이 요구된다.
평균적으로 4개의 명령어를 수행할 때 마다 global memory access를 하게된다.
그래서 최소 13개의 Warp가 있어야 200 cycle memory latency를 감당하여 성능저하가 없다.
why?
200/4 => 50/4 =? 12.5개의 warp 필요.

