동시성 문제의 발생
우리가 기능을 개발할때 단순히 하나의 트랜잭션 안에서 데이터를 조회, 수정하는 것은 매우 단순하게 해결 할 수 있었다. 스프링에서 제공해주는 @Transactional 을 통해서 Thread safe하게 처리할 수 있다.
하지만 라이브 서비스에서는 어떨까?
하나의 제품 A가 판매가 되고 있다고 가정해보자.
제품에는 여러가지 항목이 있을 수 있다. 제품명, 가격, 모델코드, 재고수량 등등이 있을 수 있다.
여기서 가장 중요한 부분은 바로 재고의 변화일 것이다.
제품의 재고가 풍성하다면 당장 어떠한 주문이 들어와도 문제가 없을 지도 모른다.
하지만 1개의 제품이 남은 상태에서 동시에 2명이상의 고객이 접근을 해서 주문을 했다고 생각해보자.
이럴경우 선착순으로 먼저 주문한 사람이 제품 주문에 성공하고 뒤늦게 주문한 사람은 재고 부족으로 인해 주문이 실패해야 한다.
다시 기존의 단순한 스프링 트랜잭션만으로 이러한 주문이 되는 서비스를 개발하면 동시에 들어오는 이러한 주문의 처리가 제대로 되지 않는 것을 바로 알 수 있다.
우리는 이러한 문제점을 해결하기 위해 동시성 처리라는 것을 고민하게 될 것이고 이번 챕터에서는 이를 해결하는 방법중 하나를 소개해보려고 한다.
DB를 이용한 동시성 제어
위의 예시에서 다룬 케이스를 다시 한번 상상해보자 데이터베이스에서 선착순으로 접근하는 사용자를 우선으로해서 데이터를 처리하게 함을 보장할 수 있다면 재고가 마이너스가 되고 주문이 성공하는 케이스를 막을 수 있다.
이러기 위해서 먼저 트렌잭션이 열린 사용자가 주문제품에 대한 데이터를 lock통해서 다른 트랜잭션의 간섭을 차단하는 방법이 바로 DB transaction lock 방식이다.
이 방식은 상당히 오래전부터 사용한 방법이고 이미 여러 예제가 공유되고 있다.
하지만 이러한 방식은 DB에서 lock을 하는 행위로 인해 데이터 처리가 순차처리가 되는 방식을 강요하게 된다. 이에 따라 분산 구조에 트래픽이 많은 요즘 같은 인프라에서는 성능이 상당히 떨어지게 되는 동시성 제어 방식이기도 하다.
나는 이러한 방식보다 조금 더 개선된 방식을 원했고 Redis를 이용한 동시성 처리방식을 선택하게 되었다.
Redis를 이용한 동시성 제어
redis가 어떻게 동시성을 제어할 수 있게 되었는가를 먼저 알아보았다.
일단 구조의 특징을 보면, redis는 명령을 실행 및 처리할때 single thread로 진행된다. 이를 통해서 원자성을 유지할 수 있다.
그리고 메모리에 저장되는 방식덕분에 고속으로 처리가 가능하다.
DB의 connection은 상당히 비싼 자원에 속하기 때문에 빈번하게 데이터 lock을 잡는것이 비효율적이 되는 이유가 되었는데, redis는 고속의 메모리 처리방식이고 여기서 처리된 결과를 한번에 DB에 처리를 시킨다면 이상적인 동시성 제어가 가능할 것이라고 생각한다.
간단한 예제를 통한 Redis 동시성 제어 구현
간단한 예제 도매인을 가지고 샘플 프로젝트를 만들어보기로 했다.
주유소 급유와 이에 따른 유류재고를 차감하는 재고 관리 시스템을 구현해보자.
기능을 간단하게 정리해 보았다.
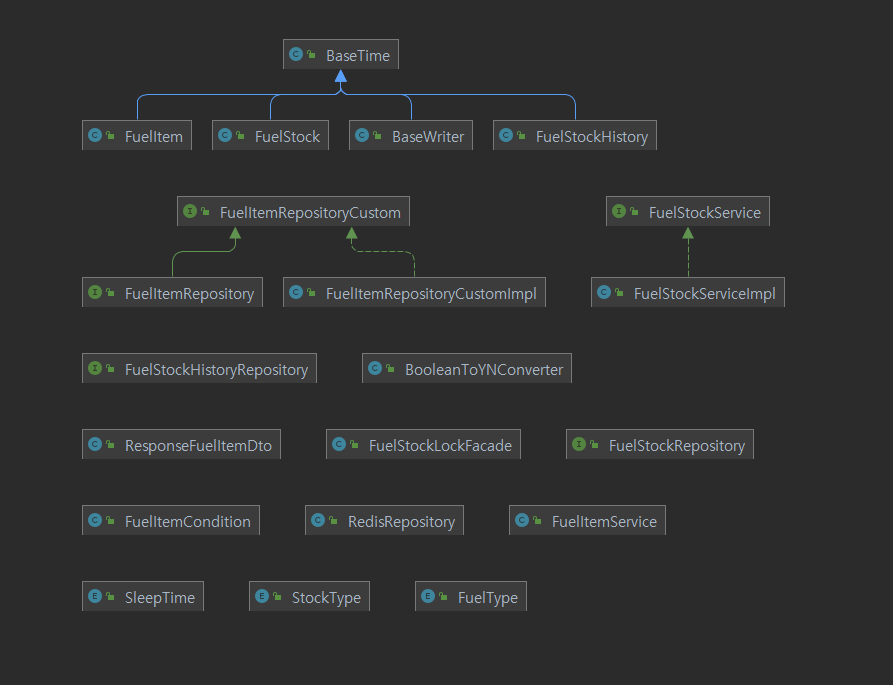
도메인 정립
- 주유제품(Fuelitem)과 재고(FuelStock)가 있다.
- 주유제품과 재고는 1:1 관계.
- 주유제품에 재고가 맵핑되는 관계.(재고쪽에서 외래키 관리.)
- 새로운 주유제품이 생성될때 기본적으로 재고가 충전되서 생성.
- 재고는 총 재고와 현재 잔여재고를 구분.
- 재고의 변동이 있을때 마다 변동 내역을 다루는 재고변동내역(FuelStockHistory)가 있다.
- 재고 변동 내역은 감소,증가,신규생성,삭제로 구분되어 생성.
프로세스를 요약하자면,
주유소에서 재고 차감 api가 호출되면 이를 처리하는 재고차감 서비스가 실행되는데 이때 동시성을 검증하여 재고 차감이 순차적으로 진행되게 하는 것이다.
재고차감 서비스는 단순히 재고 entity의 재고값을 update하는 것이므로 이 글에서는 다루지 않고 재고를 차감하는 시점에서 동시성을 어떻게 핸들링하는지만 다루려 한다.
Redis에 키를 생성하여 lock을 제어해보자.
lecttuce clinet와 spin lock 구성.
사용할 redis client는 Lettuce로 정했다.
Lettuce는 비동기 처리 방식의 redis client로 Jedis보다 성능이 월등한 것으로 유명하다.
Lettuce를 통한 sping lock 형식으로 동시성을 제어하는 코드를 작성했다.
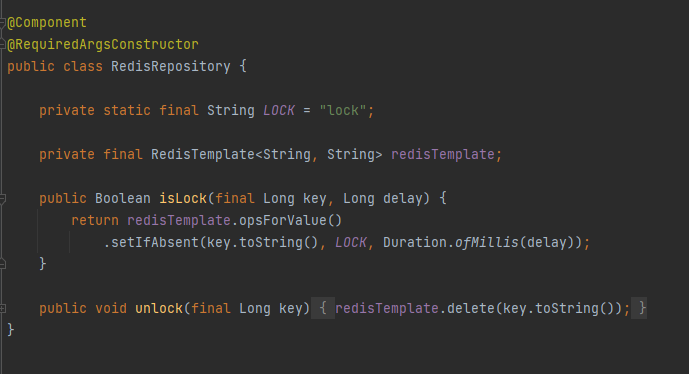
입력받는 lock의 지속시간값을 기준으로 lock이라는 key값을 생성한다.
그리고 spin lock 방식으로 값의 유무를 체크하도록 구성해 보았다.
facade 패턴을 적용하여 redis의 lock 체크 기능 구현.
lock에 대한 값을 DB에서 기본적으로 생서된 값을 꺼내서 설정하고 dev/prod 환경에서 배포가 되었을 경우, 설정된 redis delay 값을 DB에서 update을 통해 튜닝할 수 있도록 구성을 해보았다.
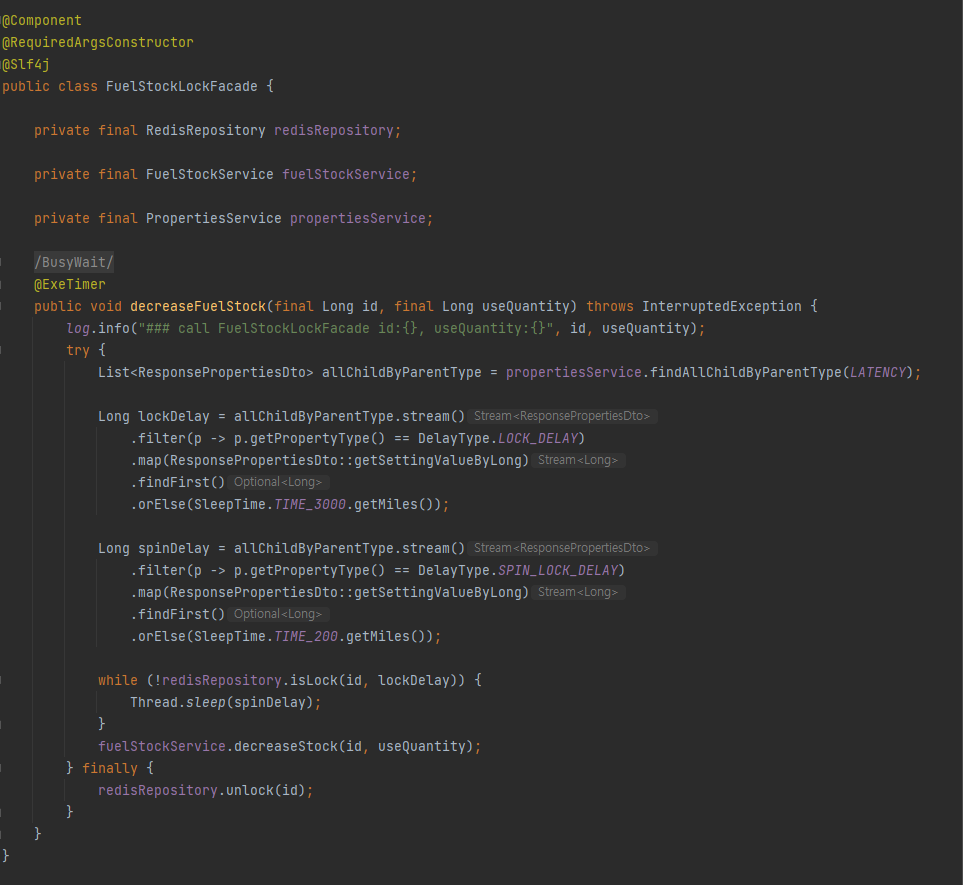
propertiesService.findAllChildByParentType(LATENCY);
를 통해서 DB에서 redis에 사용하는 lock delay 값들을 조회하여
sping lock 지속 시간과 sping lock의 delay에 사용되는 값으로 각각 할당하도록 구성을 했다.
spin lock에 thread sleep을 이용해 delay 주기.
spin lock의 딜레이를 설정하는 이유가 궁금할 수 있는데,
크게 두가지를 고려해서 작성하게 되었다.
1. 너무 과도한 spin lock의 오버헤드를 줄이고 싶었다.
2. 로컬에서 동시성을 테스트하는 테스트코드를 작성했을때, 무한 spin lock 경합이 발생하는 것을 방지하고 싶었다.
테스트코드를 통해 동시정을 검증할때 ExecutorService 와 CountDownLatch를 이용하여 작성을 하였는데, 동시에 100개의 input을 생성하면서 spin lock이 발생했고 안정적으로 lock이 제어되지 않았다.
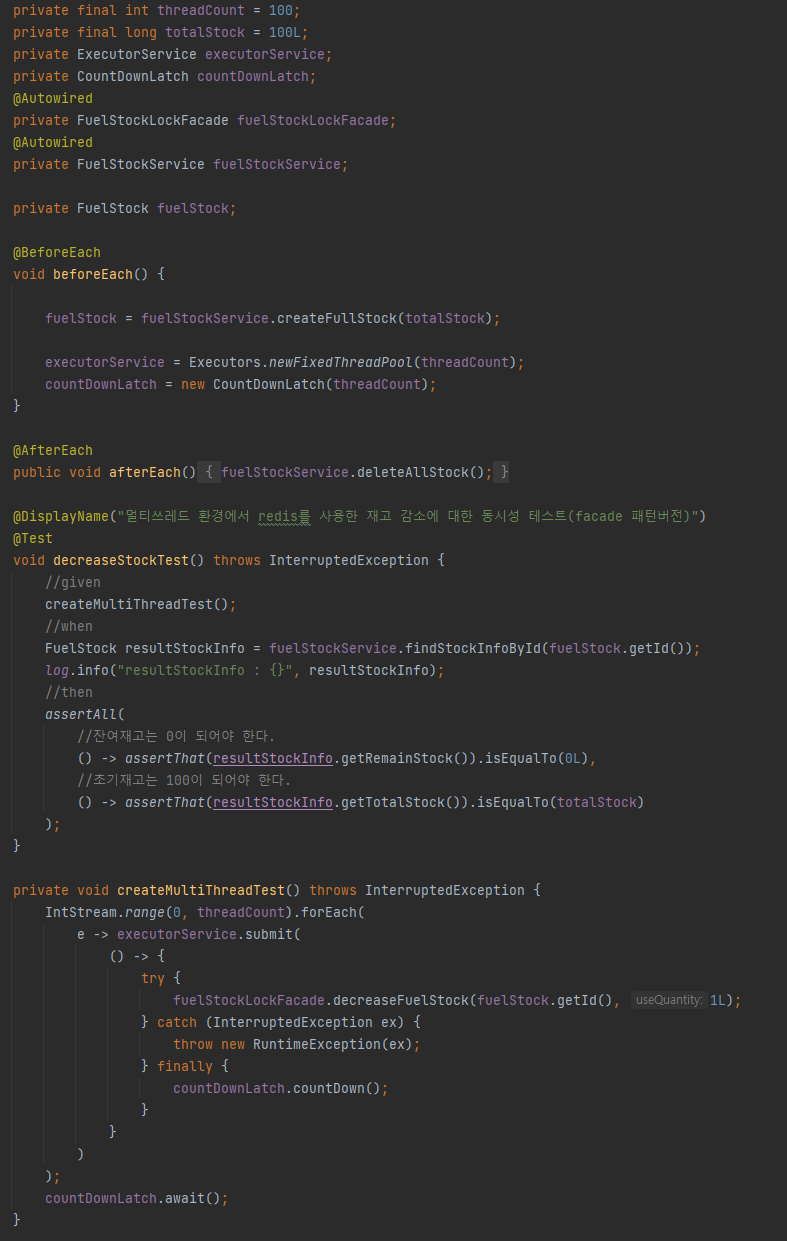
이러한 이슈를 해결하기 위해서 Thread에 적절한 sleep을 주어 spin에 대한 딜레이를 제공함으로써 이슈를 해결하게 되었다.
왜 설정값을 DB에서 가져오는 구조로 만들었는가?
sping delay값은 네트워크 트래픽, 서버의 스팩등이 영향을 주는 요소가 되기 때문에 local 환경에서의 고정된 설정값이 유효하지 않을 것이라 생각했고 DB에 redis에 사용되는 키값들을 등록시키고 이를 DB상에서 update를 통해서 재배포없이 서버 튜닝을 할 수 있는 구조로 가져가야 한다고 판단했다.
AOP로 Refactoring 하기
현재 코드의 구성은
facade 패턴의 재고 감소를 다루는 서비스 안에서 재고를 감소시키는 서비스와 redis에서의 동시성 검증 서비스가 접목되어 적용되어 있다.
곰곰히 생각을 해보니, 나는 재고감소를 시키는 기능의 서비스를 호출하여 재고를 감소시키는 것이 순수한 비지니스인데 여기서 동시성여부를 체크하는 로직을 넣은 별도의 서비스영역이 추가되는 지금의 코드가 비지니스의 본질을 흐리는 구성이라는 생각이 들었다.
이러한 부분을 어떻게 풀면 순수하게 재고감소 서비스의 코드가 동시성 체크 로직과 분리가 될 수 있을까를 고민하다 동시성 체크 로직을 AOP로 분리하는 것을 생각하게 되었다.
Custom AOP 구현하고 적용하기
우선 redisRepository를 호출하여 동시성을 체크하는 로직을 aop로 적용하기 위한 custom Aop를 생성했다.
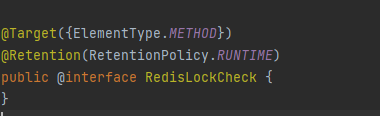
그리고 해당 annotation이 적용된 서비스 코드에서 Aop가 작동할 때의 코드 내용을 구현한 Aspect 클래스를 작성했다.
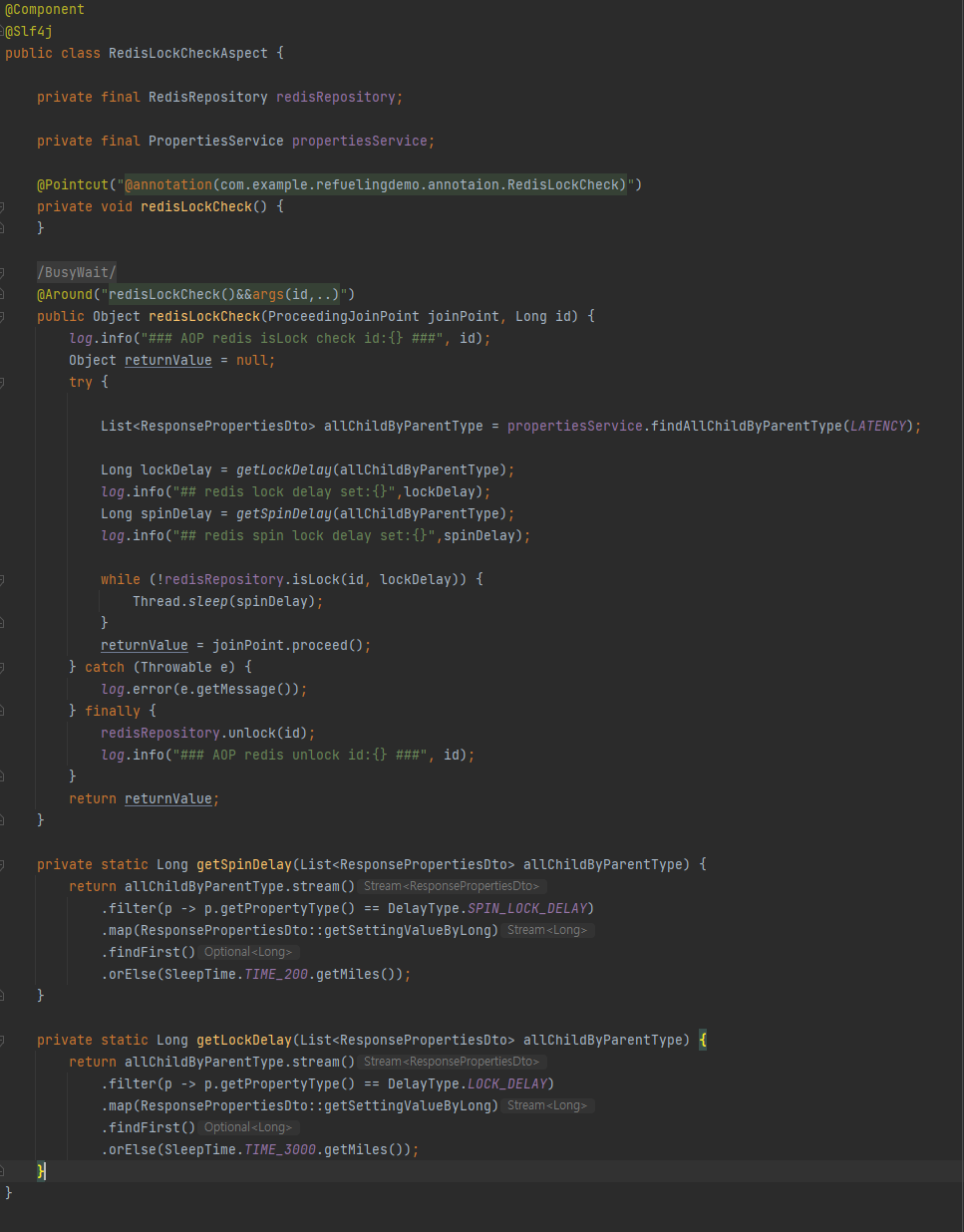
PointCut에서 맵핑에 적용되는 Custom Aop 객체를 정의하고
적용시 진행될 기능에 대한 정의를 작성했다.
여기서 나는 Around 방식으로 작성을 했는데, 재고감소 서비스가 호출되는 시점 이전에 동시성 검증 로직이 개입되고, 재고감소 서비스 호출 결과가 리턴되는 시점에서 생성되었던 lock을 해제하는 부분이 진행되어야 하는 일련의 과정을 하나로 묶는 것이 맞다고 생각해서 선택하게 되었다.
이전 코드와의 비교 검증
기존 코드와 aop로 적용된 테스트 코드를 비교해보면 양쪽 전부 이상없이 성공이 되었다.
다만 aop를 적용한 케이스의 처리속도가 처음에 compoent 으로 구현한 방식보다 테스트의 실행 시간이 더 빨랐다.
aop를 사용하여 proxy패턴을 이용하는 방식이 클래스를 생성해서 사용하는 방식보다 더 빠르게 처리가 가능한 것일까? 이 부분에 대한 궁금증을 해결하고자 구글링을 해보았으나 이렇다할 단서를 찾지는 못하였다.
