
JPA
자바 ORM 기술에 대한 표준 명세로, JAVA에서 제공하는 API이다.
자바 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스다.
자바 클래스와 DB테이블을 매핑한다.
JPA를 구현한 Hibernate, EclipseLink, DataNucleus같은 ORM 프레임워크를 사용해야 한다.
JPA를 써야하는 이유
JPA는 러닝커브가 높은 기술중 하나이다.
그럼에도 불구하고 왜 이 기술을 전세계적으로 사용하게 되는 것일까.
그 이유를 크게 3가지로 생각해 보았다.
패러다임
현대의 웹 어플리케이션을 개발하는 데에는 관계형 데이터베이스가 빠지기 힘든 중요 요소로 자리 잡았다.
하지만 자바같은 객체지향 프로그래밍에게는 관계형 데이터 베이스가 페러다임 불일치
를 일으키는 요소이기도 하다.
이러한 패러다임 불일치를 극복하기 위한 노력의 결과물이 바로 ORM이고 이를 수행하는 프레임워크가 JPA 인 것이다.
구현체의 다형성 제공
spring Data JPA는 구현체들과의 맵핑을 제공한다.
JPA가 인터페이스로 구현된 이유는 이러한 구현체를 언제든지 변경하기 쉽도록 하기 위해서 다형성을 모토로 만들어졌기 때문이다.
Hibernate
ORM을 하기 위해 만들어진 프래임워크중 하나이다.
JPA에서 주로 사용하는 구현체 중 하나이다.
실제로 Hibernate를 쓰나 JPA를 쓰나 별차이는 없다.
(JPA가 인터페이스로 Hibearnate를 이용하니 그럴수 밖에 없다.)
저장소 변경의 용의성
구현체의 변경용의성 뿐만이 아니라 관계형 데이터베이 외의 다른 저장소로 쉽게 교체하는 것도 역시 가능하다.
가령 Oracle을 사용하는 상황에서 MySQL이나 MongoDB로의 전환이 필요하다고 한다면 의존성 교체만으로도 쉽게 탈바꿈하는 것이 가능하다.(물론 DB간 지원이 안되는 기능들은 별도로 리팩토링이 필요하긴 하다.)
H2 Database
우선 JPA를 사용하기 이전에 H2 DB를 사용하기 위한 몇가지 설정을 하였다.
일전에 bundle.gradle에서 H2 DB를 의존성 설정을 했었다.
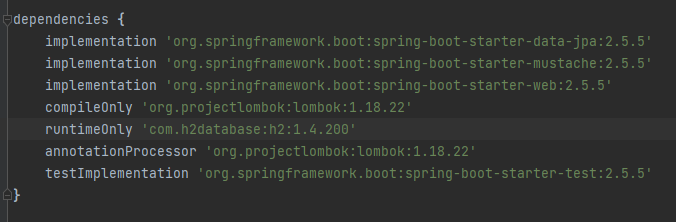
그리고 H2 DB를 console에서 실행 쿼리를 모니터링하고 별도로 웹브라우저를 통해서 DB management를 하기 위해서 application.properties를 설정했다.
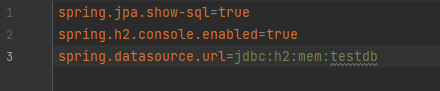
첫번째 줄에 있는 spring.jpa.show-sql는 console에서 실행되는 쿼리 로그 출력을 보여줄지말지 여부를 설정한다.
두번째 줄의 spring.h2.console.enabled는 웹브라우져로 접근하는 별도의 DB console 기능 사용 여부를 결정하게 해준다.
이 기능을 활성화하면 어플리케이션을 실행하면 메모리 DB가 작동하게 되고
이때 웹브라우저의 http://localhost:8080/h2-console/ 을 통해서 DB에 접근할 수 있다.
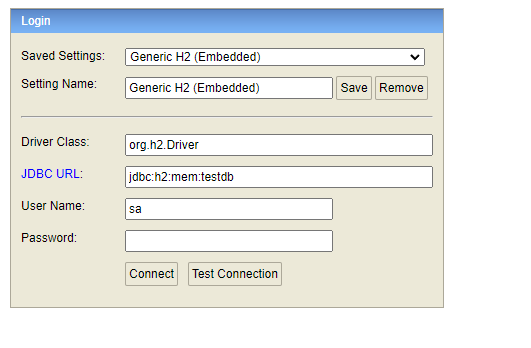
세번째 줄 spring.datasource.url은 DB 접속창에 있는 JDBC URL 주소를 설정하는 항목이다.
이 항목에서 url을 설정하지 않고 사용하면
주소가 자동생성되는데 이 자동생성된 주소를 매번 DB 접속창에 JDBC URL에 사용해야하는 번거로움이 생긴다.(심지어 띄울때마다 새로운 값으로 생성된다.)
- url을 정의하지 않고 H2를 띄웠을때 console에 출력된 url 정보
'jdbc:h2:mem:bf82a14a-15a6-4194-b560-ad75c283b802'

이렇게 불편하게 쓰라고 만들었을리가 없다!!
그래서 추가적으로 접속 url을 정의했다.
'jdbc:h2:mem:testdb'

이렇게 하면 물리적인 파일이 아닌 메모리에 DB를 생성하게 되고, 휘발성으로 사용할 수 있게 된다.(물론 물리적으로 만들어도 JPA 설정에 따라 메모리 형식으로 사용이 가능하다.)
Start JPA
JPA를 사용하기 위해서는 우선 @Entity를 사용할 도메인을 작성해야 한다.
이를 통해서 DB 테이블을 생성할 예정이다.
Entity 작성
우선 단순한 예제 도매인을 책을 따라 만들어 봤다.
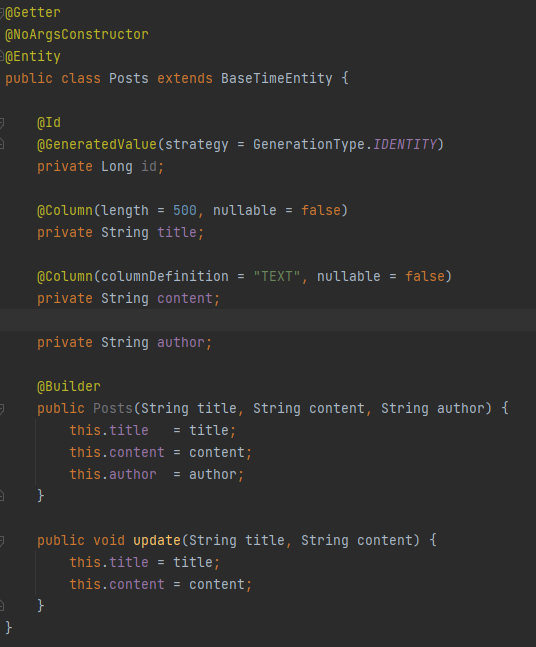
여기서 우선 확인해야 할 것은 어노테이션 설정이다.
@Entity를 선언하여 JPA가 관리할 대상으로 도메인을 작성했다.
이때 필요한 생성자 생성을 위해 lombok으로 @NoArgsConstructor를 선언하고,
getter를 사용하기 위해 @Getter를 선언했다.
테이블에 사용할 PK 값을 위한 컬럼을 @Id로 선언하고
0부터 1씩 증가하는 값을 사용하기 위해 @GeneratedValue을 선언했다.
이때 전략패턴을 사용할 수 있는데, 책에서는 MySql을 사용할 예정인지 IDENTITY를 선택한 것으로 보인다.(오라클인 경우 나는 sequence 전략을 사용했었다.)
그 외 단순 입력값 컬럼 몇가지를 추가적으로 작성하였다.
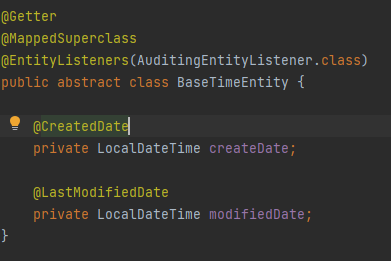
그리고 JPA에서는 등록,수정 시간같은 공통적인 부분을 하나의 클래스로 만들어서 이를 필요한 도메인별로 상속하여 사용할 수 있도록 되어 있다.
이때 선언되는 어노테이션들을 잘 봐야 한다.
별도의 테이블로 생성하려는 것이 아니기 때문에 @Entity를 선언하지 않는다.
대신 @MappedSuperclass를 선언하여 JPA의 상속관계를 정의하고 있다.
그리고 JPA에서 이벤트 발생시 이를 캐치하여 핸들링하는
@EntityListeners를 추가하고 AuditingEntityListener.class를 정의해서
JPA의 Auditing 사용을 명시했다.
마지막으로 이렇게 설정된 Auditing을 이용하기 위해
main에 추가적으로 @EnableJpaAuditing을 선언했다.

Repository 작성
일단 단순 입력/조회/수정 만을 사용할 예정이기 때문에
기본적인 인터페이스 repository를 생성 후 JpaRepository를 상속받아서 사용했다.
JpaRepository에 해당하는 도메인과 PK 컬럼타입을 generic하면 사용이 가능해 진다.

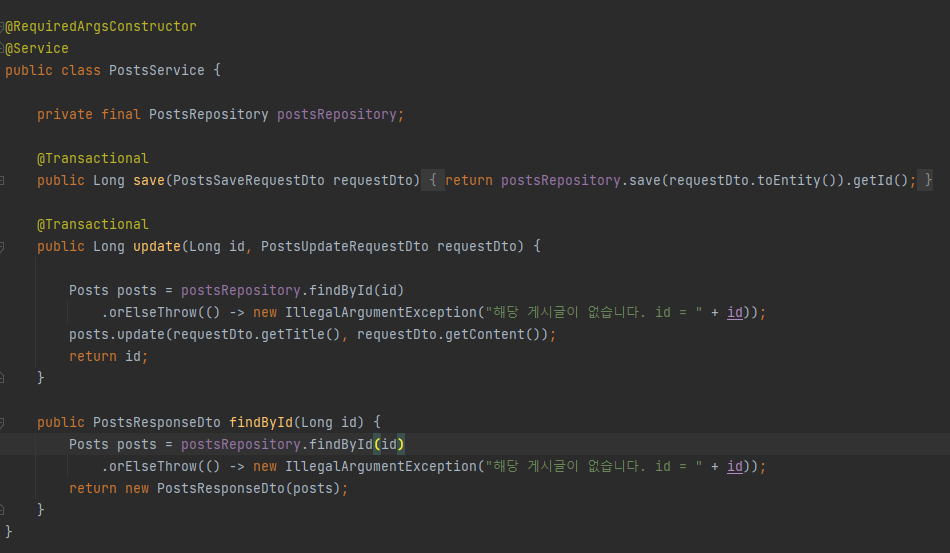
Service 작성
저장과 수정 조회를 담당할 각 메소드를 서비스 클래스에서 정의했다.
나는 보통 클래스 단위의 @Transactional을 설정했었는데,
이는 불필요한 조회 클래스에도 적용되는 안좋은 버릇이라 생각이 들어서
저장, 수정 메소드에만 적용하도록 스타일을 교정하고 있다.
repository를 호출하는 부분이 중요한데,
아까 작성한 interface에서는 구현체를 작성하지 않았다.
하지만 서비스에서는 해당하는 기능의 메소드를 JpaRepository의 것을 사용하여 구현한 것을 확인 할 수 있다.
저장할때는 save, pk값으로 조회할때는 findById를 사용했다.
그리고 JPA를 처음하는 분들이 가장 당황하는 부분중 하나인 update 코드 부분을 살펴보자.
일반적으로 Mybatis를 사용했었을때는 update 쿼리가 작성된 dao의 메소드를 파라메터를 태워서 호출했을 것이다.
하지만 JPA는 영속성 컨텍스트에 조회된 데이터객체에 대한 값의 변동을 감지한다.
값이 변동됬을 때 이에 해당하는 update 쿼리를 JPA가 알아서 작성해서 실행한다.
그래서 update 메소드는 수정할 데이터를 Pk값으로 조회해서 가져온 뒤,
변경되는 값을 Set해주는 도메인의 메소드를 호출하고 있는 것이다.
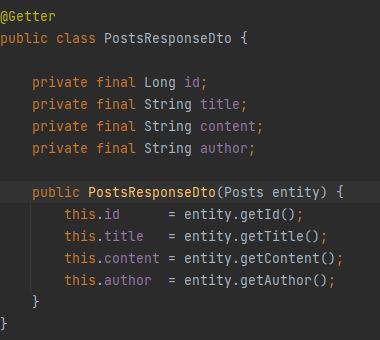
Dto 작성
조회기능에 사용하기 위핸 Dto를 간략히 작성했다.
여기서 잠깐!
화면에 그냥 Entitiy를 반환하면 되지, 굳이 왜 Dto를 생성하는가라는 의문을 가져야 한다.
MVC 패턴에 관계형데이터베이스 기준의 절차지향적인 개발을 오래 해온 분들은 이 점을 이상하거나 불필요하다고 생각할 수 있다.
하지만 Dto를 사용해야하는 이유는 매우 간단하다.
view에 대한 반환값이 Entity에 종속화 되기 때문이다.
예를 들어보자.
화면에서 사용되는 파라메터의 명칭이나, 사용되는 파라메터 필드가
반드시 DB에 사용되는 컬럼이 아닌 경우가 많다.
그런데 JPA는 Entity도메인의 필드를 DB의 컬럼으로 생성한다.
만약 화면에서만 사용하는 필드값이 있는 경우, Entity를 써서 반환해야 한다면 어떤 문제가 생기겠는가.
화면에서만 써야하는 불필요한 필드가 Entity에 정의되야 하는 것이다.
그럼 불필요한 컬럼이 DB 테이블에 생성되고 말 것이다.
만에 하다 매우 단순한 구조의 화면이고 화면의 컬럼이 DB컬럼으로도 구현되야 할 수도 있을 것이다.
하지만 이 때 만들어진 컬럼이 영구적일 것이라고는 볼 수 없다.
화면은 수시로 변경이 될 여지가 많다.
변경/수정 되는 기능으로 인해 필드의 컬럼명은 언제든지 바뀌거나 늘어나거나 줄어들 수 있다.
만약 삭제가 되야하는 필드가 생긴다면 어떻게 되겠는가.
화면에서 사라지는 단순 구분값이 없어졌을 뿐인데 DB상에서는 삭제되야하는 컬럼이 생기는 것이다. 이미 view영역이 DB영역에 사이드 이팩트를 일으키는 것이다.
이는 나중에 API를 만들때도 동일하다.
API의 스팩은 변경될 수가 있다. 그런데 이를 Entity로 줘야한다고 생각해보자.
test.api에서 항목 a,b,c를 사용해야하는데 Entity에서는 a,b,c,d,e,f의 필드가 있을 수 있다. 이때 Dto를 쓰지 않는다면 해당 API스팩은 강제로 Entity에 종속적인 구조가 될 수 밖에 없다.
JPA에서의 Entity는 외부와의 연결에 사용되면 절대로 안된다.
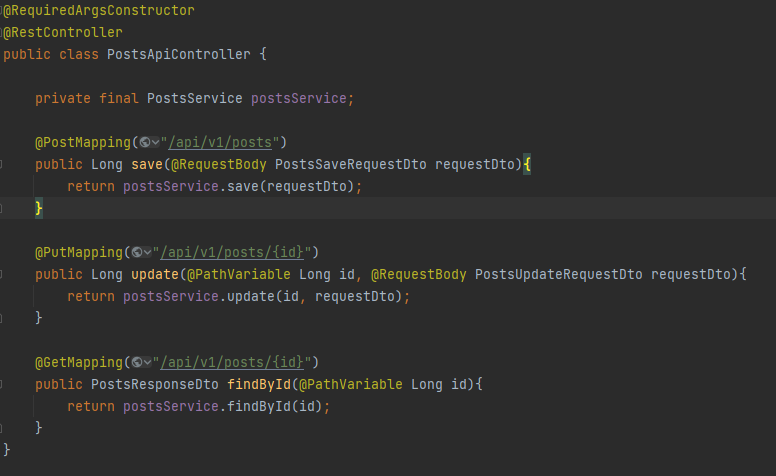
Controller 작성
@PathVariable을 사용하여 url를 작성한 단순한 컨트롤러를 구현했다.
TestCode 작성
이제 만들어진 API의 테스트코드를 작성하자.
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)을 선언해야 한다.
그리고 사용하는 로컬 Port값을 가져오기 위해 @LocalServerPort을 이용했다.
각 테스트가 종료될 때 마다 @AfterEach로 호출되는 메소드에서
테스트한 DB값의 소거를 하도록 했다.
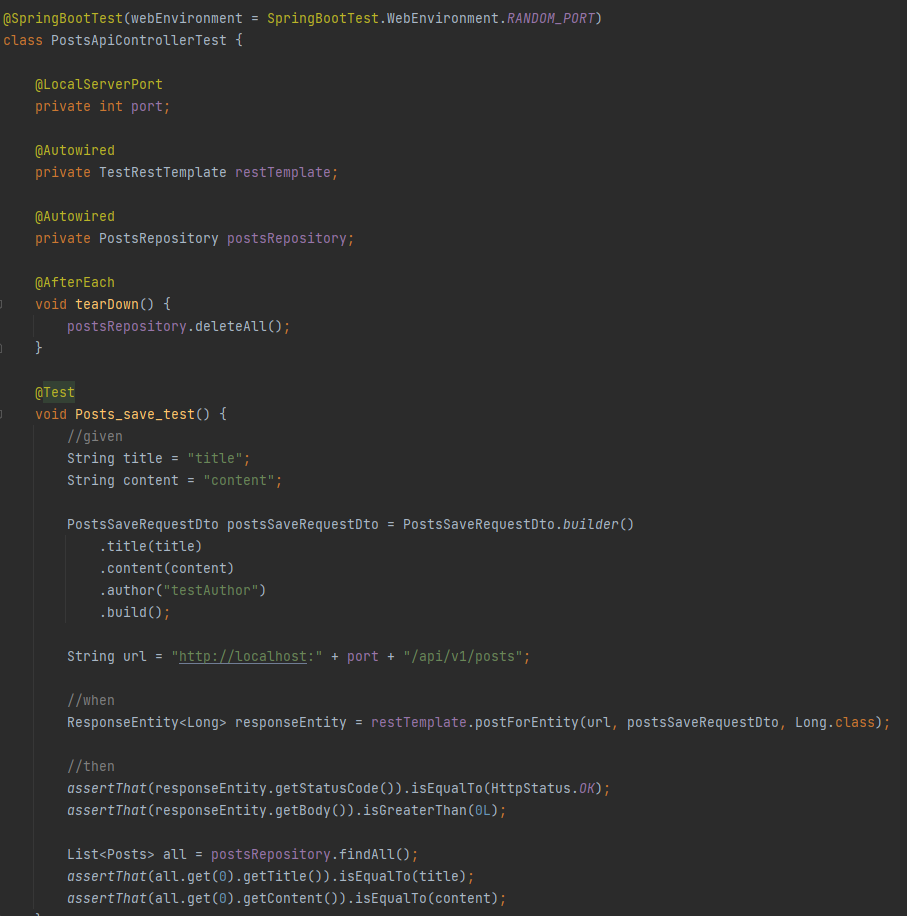
도메인에서 @Builder을 선안한 상태이므로 이를 이용해서 Dto를 생성하고
로컬 주소와 사용되는 포트를 이용해서 호출할 수 있는 url를 만들었다.
선언된 각 파라메터의 값이 주입되어 나의 로컬 주소로 dto가 반환되는 것을 검증하는 코드를 작성했다.
그다음은 조회된 값의 수정기능을 테스트하기 위한 코드를 작성했다.
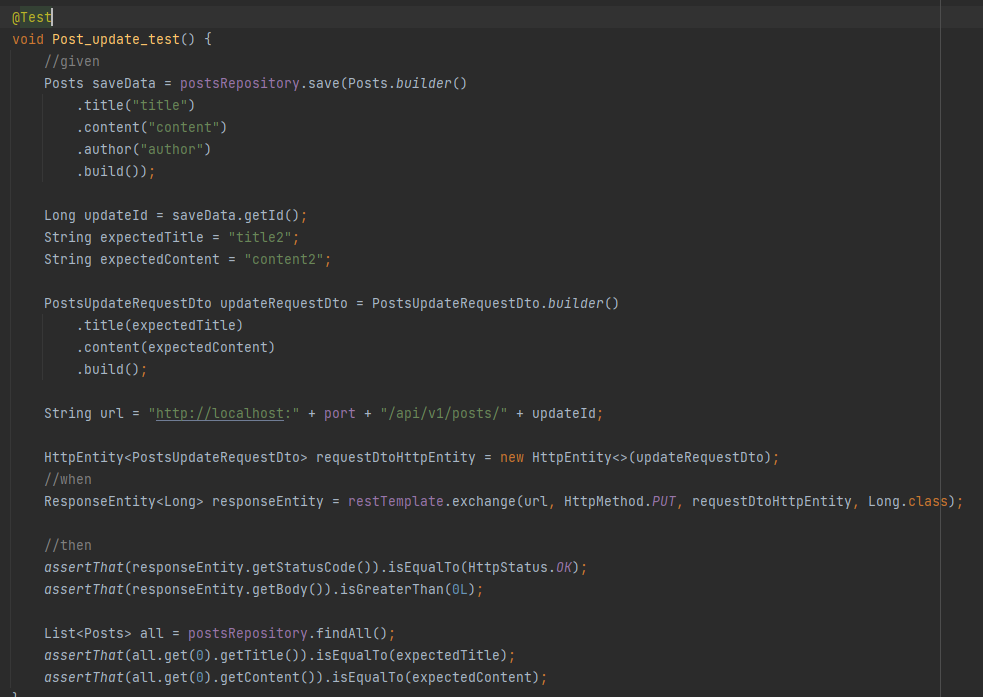
기본적으로 JPA의 영속성 컨텍스트에 조회대상의 객체가 필요하고
매 테스트마다 데이터가 초기화 되기 때문에 현재 당장 수정할 데이터가 없다.
그러므로 수정테스트 메소드 안에서 초기 데이터를 생성해주면서 영속성 컨텍스트에 데이터 객체가 생성되도록 한다음, 여기서 더티체크가 일어나도록 값의 수정을 수행하면 JPA가 update 쿼리를 실행할 것이다.
그리고 다시 조회를 함으로써 수정된 데이터가 맞는지를 검증하는 방식으로 진행했다.
결과는 성.공.

이제 작성된 모든 테스트코드를 실행해서 검증해보도록 하자.
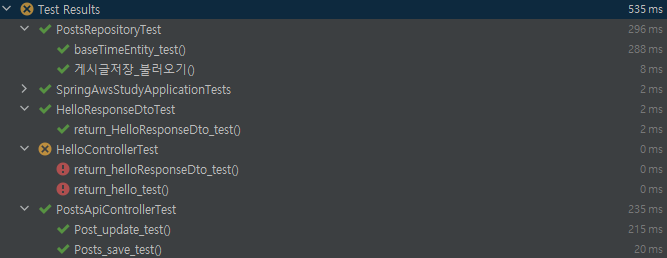
맨 처음 작성한 기본 샘플 코드가 에러가 발생했다.
첫 사이드 이팩트
분명히 JPA관련 코드를 작성하기 이전에는 멀쩡하게 잘 수행되고 있었다.
그런데 추가개발이 되면서 무엇인가가 테스트코드에 영향을 준 것이다.
원인을 확인해 보기 위해 콘솔창을 살펴보자.

Error creating bean with name 'jpaAuditingHandler': Cannot resolve reference to bean 'jpaMappingContext' while setting constructor argument; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'jpaMappingContext': Invocation of init method failed; nested exception is java.lang.IllegalArgumentException: JPA metamodel must not be empty!
라는 메세지가 출력되고 있다.
Audit관련 설정이 추가되면서 JPA에 관련된 에러가 생성되었는데
문제는 이 에러의 발생시점이 HelloControllerTest 에서 발생했다는 것이다.
HelloControllerTest에는 JPA를 쓰지않는 단순한 문자열 리턴 Rest controller 테스트이다.
그런데 어째서 JPA관련 에러가 발생하는 것일까?
원인은 main에 추가된 @EnableJpaAuditing 어노테이션이다.
JPA에 관련된 Audit설정이 main에 추가되면서 기존에 JPA를 사용하지 않는 테스트코드에 영향을 주게 된 것이다.
해결 방안
내가 알고 있는 가장 심플한 방법은 설정을 main에서 분리시키는 것이다.
@WebMvcTest가 선언된 HelloControllerTest에서는 이미 HelloControllerTest.class만 해당하도록 범위가 제한되있다.
그러므로 main에서 audit관련된 설정을 별도의 config로 생성하여
JPA가 호출되는 시점에 사용되도록 할 것이다.
JPA config 작성
@Configuration으로 선언한 설정 클래스에서
@EnableJpaAuditing 을 선언하도록 해주었다.

다시 전체 테스트
설정을 변경한 결과 이상없이 전체 테스트가 통과하는 것을 확인 할 수 있었다.
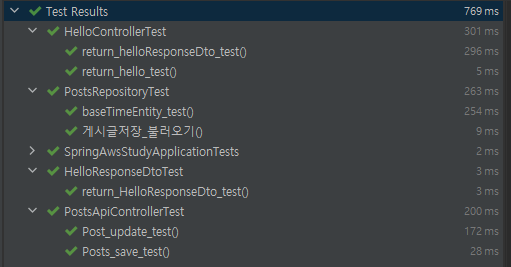
마무리
이번 시간은 H2를 이용한 데이터베이스를 생성하기위해 JPA를 사용해보았다.
JPA를 사용하기 위한 구현체인 Hibernate와의 관계도 살펴볼 수 있었다.
핵심적인 부분은 JPA의 영속성 컨텍스트 개념과 더티체크라고 생각된다.
이기서 한가지 더 나아가보면, 도메인 클래스의 @Setter의 생성이 매우 위험한 행동이 된다는 것을 알게 되었다.
이는 객체지향에서 캡슐화에도 위배되는 부분이기도 하다.
생성자들 통한 객체 생성이 중요하다는 부분도 같이 느낄 수 있었던 기회였다.
그리고 JPA에서 제공해주는 편의기능중 하나인 auditing을 맛볼 수 있었고
이로 인해 발생한 사이드이팩트와 이를 해결하는 경험이 매우 소중한 시간이였다.
