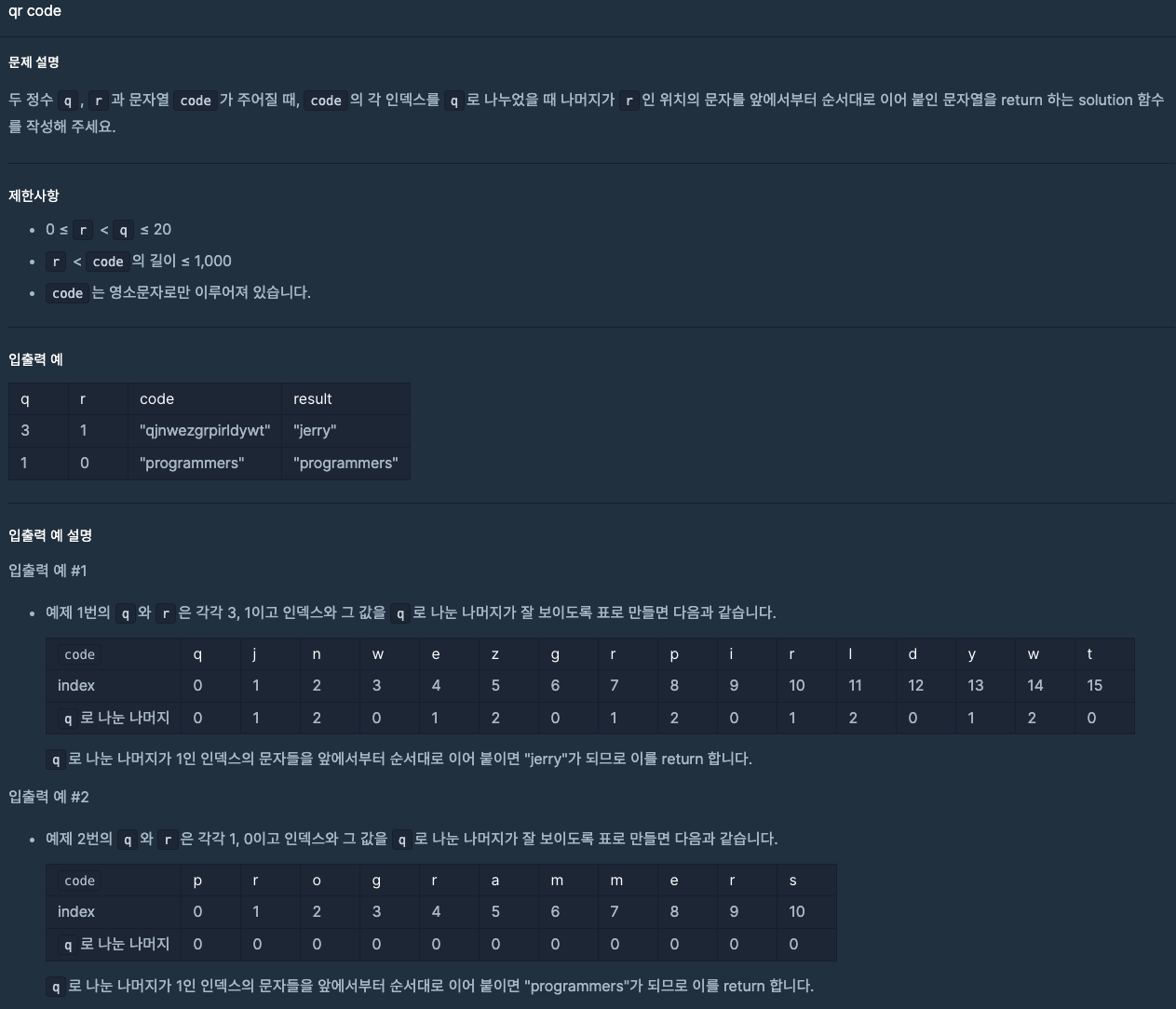
문제를 보고 처음 생각한 방법은 각 단어마다 각각 하나씩 비교하여 계산을 해야겠다는 생각을 했다.
- 입력받은 code(String)을 한 단어씩 분류하여 배열에 저장한다.
// 입력받은 code를 각각의 character로 분류한다.
let codeMaps: [String] = code.map {
String($0)
}- index를 이용하여 계산을 하기 때문에 입력받은 code(String)의 index와 q를 나눈 나머지와 r을 비교한다.
// codeMaps의 index값을 이용하여 계산한다.
for index in 0..<codeMaps.count {
if (index % q) == r {
// 해당 조건을 만족하는 경우 result와 더하여 단어를 만든다.
result = "\(result)" + "\(codeMaps[index])"
}
}위의 코드에서 조건을 만족하는 경우 만족하는 string의 값을 계속 더하여 결과를 표시한다.
최종 코드
func solution(_ q:Int, _ r:Int, _ code:String) -> String {
var result: String = ""
// 입력받은 code를 각각의 character로 분류한다.
let codeMaps: [String] = code.map {
String($0)
}
// codeMaps의 index값을 이용하여 계산한다.
for index in 0..<codeMaps.count {
if (index % q) == r {
// 해당 조건을 만족하는 경우 result와 더하여 단어를 만든다.
result = "\(result)" + "\(codeMaps[index])"
}
}
return result
}여기까지가 나의 풀이였고, 다른 사람들의 풀이를 확인해보자.
func solutionV1(_ q: Int, _ r: Int, _ code: String) -> String {
return code.enumerated().filter { $0.offset % q == r }.map { String($0.element) }.joined()
}이를 보면 단 한줄로 해당 로직을 실행하였다.
코드에서 사용한 것을 하나하나 뜯어보자.
- enumerated()
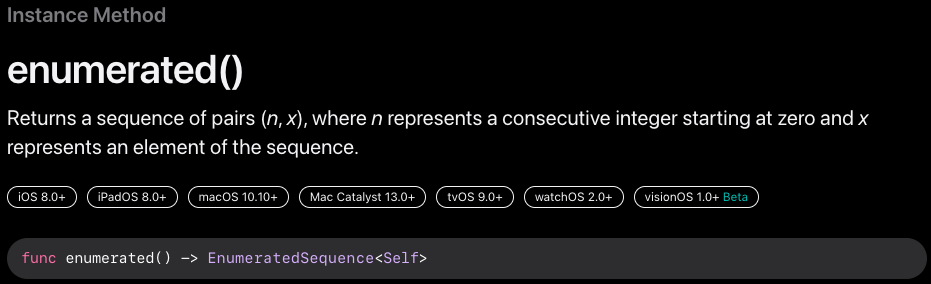
공식문서에서는 (n, x)쌍의 시퀀스를 반환한다고 한다.
n : 0부터 시작하는 연속적인 정수
x : 시퀀스의 요소
처음에 이는 단순하게 배열에 enumerated()함수를 사용하게 된다면, (index, value) 형식의 튜플 형식으로 구현된 리스트형식이 리턴된다고 생각을 하고 있었다.
애플의 공식문서를 확인해보면 문자열의 문자를 열거하여 문자를 출력하는 것을 알 수 있다.
for (n, c) in "Swift".enumerated() {
print("\(n): '\(c)'")
}
// Prints "0: 'S'"
// Prints "1: 'w'"
// Prints "2: 'i'"
// Prints "3: 'f'"
// Prints "4: 't'"- 고차함수 filter & ($0.offset, $0.element)
*고차 함수 : 다른 함수를 전달인자로 받거나 함수 실행의 결과를 함수로 반환하는 함수.
*$0은 (offset, element)를 반환. element는 Sequence의 원소, offset는 해당 element의 index.

공식문서를 우선적으로 참조해보자!
filter같은 경우 기존 컨테이너의 요소에 대해 조건을 만족하는 값들을 새로운 컨테이너로 반환하는 형식. (*Container : 다른 타입의 값을 담을 수 있으므로 context의 역할을 수행)
예를 들어 비교해보면
let cast: Set = ["Vivien", "Marlon", "Kim", "Karl"]
let shortNames = cast.filter { $0.count < 5 } // cast에서 "$0.count < 5"조건을 만족하는 값들을 'shortNames'에 새롭게 저장.
// shortNames = ["Kim", "Karl"]
shortNames.isSubset(of: cast) // isSubset: A.isSubset(of: B) A가 B의 subSet을 가지는 경우 true를 반환한다.
// true
shortNames.contains("Vivien")
// false알고리즘 하나의 문제로 많은 걸 얻어가야지~~
뿌듯!

my name is hyeon