QnA
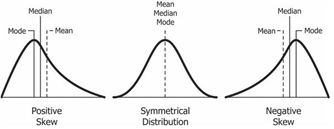
negative skew? OR positive skew?
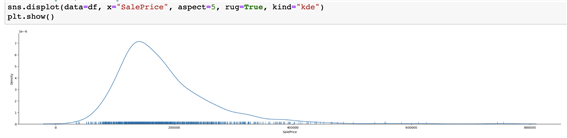
=> Positive Skewness
-
Positive Skewness는 오른쪽 꼬리가 왼쪽보다 더 길 때를 의미하고 평균(Mean)과 중위수(Median)가 최빈값(Mode)보다 크는 것을 의미합니다.
-
Negative Skewness 왼쪽 꼬리가 오른쪽보다 더 길 때를 의미하고 평균(Mean)과 중위수(Median)가 최빈값(Mode)보다 작는 것을 의미하게 됩니다.
결측치
# 결측치가 많다고 삭제하는게 무조건 나은 방법이 아닐 수도 있습니다.
# 이상치, 특잇값을 찾는다면 오히려 특정 값이 신호가 될 수도 있습니다.
# 범주형 값이라면 결측치가 많더라도 채우지 않고 인코딩해주면 나머지 없는 값은 0으로 채워지게 됩니다.
# 그 대신 희소한 행렬이 생성됩니다.
# 수치데이터인데 결측치라면 잘못채웠을 때 오해할수 있으니 주의가 필요합니다.
# 언제 어떤 방법을 사용해야할지 모르겠다면 노트북 필사를 여러 개 해보고 다양한 데이터셋을 다뤄보는것을 추천합니다.
# 지금까지 다뤄본 데이터셋이 많지 않기 때문에 좀 더 수련이 필요합니다.
# 경험치를 많이 쌓는게 필요합니다.왜도와 첨도
# 왜도와 첨도의 정확한 수치까지 알아야할 필요가 있나요?
# => 정확한 수치까지 모르더라도 시각화를 해보면 알 수 있습니다.
# 그런데 변수가 100개 그 이 상이라면? 물론 하나씩 다 비교해 볼 수 있습니다. 하지만 시간이 많이 필요합니다.
# Anscombe's Quartet 데이터를 생각해 보면? 요약된 기술 통계는 데이터를 자세히 설명하지 못하는 부분도 있습니다.
# 그래서 왜도와 첨도는 변수가 수백개 될 때 전체적으로 왜도와 첨도가 높은 값을 추출해서 전처리 할 수 있습니다.
# 어제 실습했던 예를 보면 왜도나 첨도가 높은 값을 추출해서 변환하는 전처리를 진행할 수도 있습니다.
# pandas, numpy 등으로 기술통계를 구해보면 왜도, 첨도(기본 값 피셔의 정의 일 때) 0에 가까울 때 정규분포에 가까운 모습니다. 702실습 진행 흐름
현재 0702 실습 진행 흐름입니다!
1. 다양한 변수의 타입을 확인해보고 hist를 활용해 카테고리형 변수와 연속형 변수를 구분해줍니다.
2. 분류해준 연속형 변수를 hist를 통해서 분포를 확인해봅니다.
3. 왜도와 첨도를 확인하여 분포가 치우쳐진 연속형 변수를 확인합니다.
(모델 학습 결과를 더 끌어올리기 위해서 입니다.)
4. 분포가 치우쳐진 변수를 확인 후 추출하여 로그 변환을 진행해줍니다make feature
# label_name 변수에 예측에 사용할 정답 값 지정하기
# Submissions are evaluated on Root-Mean-Squared-Error (RMSE)
# between the logarithm of the predicted value
# and the logarithm of the observed sales price.
# (Taking logs means that errors
# in predicting expensive houses and cheap houses will affect the result equally.)
# 1) 2억=>4억으로 예측하는 집값은, 2) 100억=>110억으로 예측했을 때 어디에 더 패널티를 줄 것인지
# MAE => 1) 2억차이, 2)10억, 오차의 절대값
# MSE => 1) 4억차이, 2)100억차이, 오차가 크면 클수록 값은 더 벌어집니다.
# RMSLE => 1) np.log(2) => 0.69, 2) np.log(10) => 2.30
# => 로그값은 작은 값에서 더 패널티를 주고 값이 커짐에 따라 완만하게 증가합니다.
# => 로그값이 작은 값에서 더 패널티를 주는 것은 로그 그래프를 떠올려 보세요.하나의 값이 많을 경우 ?
다른 데이터에서도 같은 값이 들어있는 변수가 있을 때도 있습니다. 이런 값은 사용, 제거 둘 다 해보고 점수차이가 없다면 제외하는게 낫습니다. 만약 희소하게 등장하는 값이 중요한 역할을 한다면 예를들어 이상치 탐지라든지 특정 징후를 표현한다면 두는게 나을 수도 있습니다.
시각화했을 때도 다른 변수와 함께 보는게 좋습니다.
pairplot을 볼 때도 수치 변수끼리의 상관을 보여주듯이 일단 비교해 보고 사용여부를 결정하는게 낫습니다.ELT와 ELT의 차이
ETL : 데이터 웨어하우스에서 작동하며 데이터를 추출하고 (E) -> 변환하여 (T) -> 데이터를 적재하는 (L) 순서로 데이터를 처리하는 프로세스
ELT : 데이터 레이크에서 작동하며 데이터를 추출하고 (E) -> 적재한 다음 (L) -> 데이터를 변환하는 (T) 순서로 데이터를 처리하는 프로세스이다.
r2_score
r2_score를 통해서 모델이 얼마나 잘 예측했는지 확인해보고
feature_importances에서 어떤 변수의 중요도가 높은지 확인해보고 있는 과정입니다!
만약 이 과정에서 생각보다 r2_score나 RMSE가 낮을 경우 다시 Feature_Engineering을 통해서 성능을 끌어올릴 수 있습니다.
수치형과 범주형 총 정리
## 수치형
* 결측치 대체(Imputation)
* 수치형 변수를 대체할 때는 원래의 값이 너무 왜곡되지 않는지도 주의가 필요합니다.
* 중앙값(중간값), 평균값 등의 대표값으로 대체할 수도 있지만,
* 당뇨병 실습에서 했던 회귀로 예측해서 채우는 방법도 있습니다.
* 당뇨병 실습에서 했던 인슐린을 채울 때 당뇨병 여부에 따라 대표값을 구한 것 처럼
* 여기에서도 다른 변수를 참고해서 채워볼 수도 있습니다.
* 스케일링 - Standard, Min-Max, Robust
* 변환 - log
* 이상치(너무 크거나 작은 범위를 벗어나는 값) 제거 혹은 대체
* 오류값(잘못된 값) 제거 혹은 대체
* 이산화 - cut, qcut
## 범주형
* 결측치 대체(Imputation)
* 인코딩 - label, ordinal, one-hot-encoding
* 범주 중에 빈도가 적은 값은 대체하기X
- X는 feature, 독립변수, 2차원 array 형태, 학습할 피처, 예) 시험의 문제
y
- y는 label, 종속변수, target, 정답, 1차원 벡터, 예) 시험의 정답
handle_unknown='ignore’
- test 컬럼에 있으나 train 컬럼에 없는 경우에는 train 없는 컬럼에 대해서 원핫인코딩을 진행하지 않고 무시합니다.
출처 : 멋쟁이사자처럼 AI스쿨 박조은강사님

배운걸 다 흡수하는 제로민