TOC
-
시간복잡도란?
-
O(1)
1. 시간복잡도란?
시간복잡도는 계산 복잡도 이론에서 시간 복잡도는 문제를 해결하는데 걸리는 시간과 입력의 함수 관계를 가리킨다. 출처 : 위키피디아
한줄로 입력에 따른 문제 해결에 걸리는 시간에 대한 함수 관계라고 보면 된다.
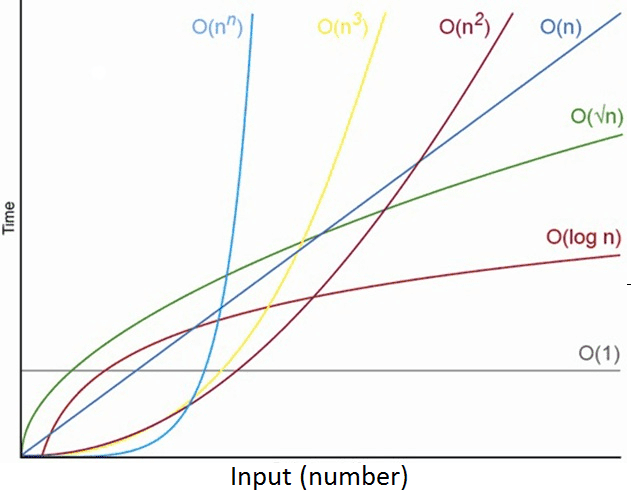
이에 따라 그래프가 그려질텐데 일단 가장 간단한 시간복잡도부터 확인하자
O(1)
그래프에서 O(1)의 그래프가 시간에 수직한 그래프가 그려짐을 알 수 있다.
배열의 크기가 몇이던지 상관 없이 배열 index의 0번째 값을 확인하는 것이므로
input에 상관하지 않고 시간도 일정한 시간복잡도를 가지게 된다.
// O(1)
const Oone=(ary)=>{
return ary[0]===0 ? true : false;
}O(n)
const On=(number)=>{
for(let i=0; i<number;i++){
if(i===number) return i;
}
}위 함수는 O(n)의 시간복잡도를 가진다.
이유는 input값인 number의 크기가 커지면 커질수록 0부터 number까지의 값을 찾아가는
i는 number의 크기에 따라 시간을 소모하게 된다 따라서 직선 그래프가 그려지게 된다.
O(n^2)
const OnSquare=(ary)=>{
for(let i=0;i<ary.length;i++){
for(let j=0;j<ary.length;j++){
console.log('i, j',i,j);
}
}
}
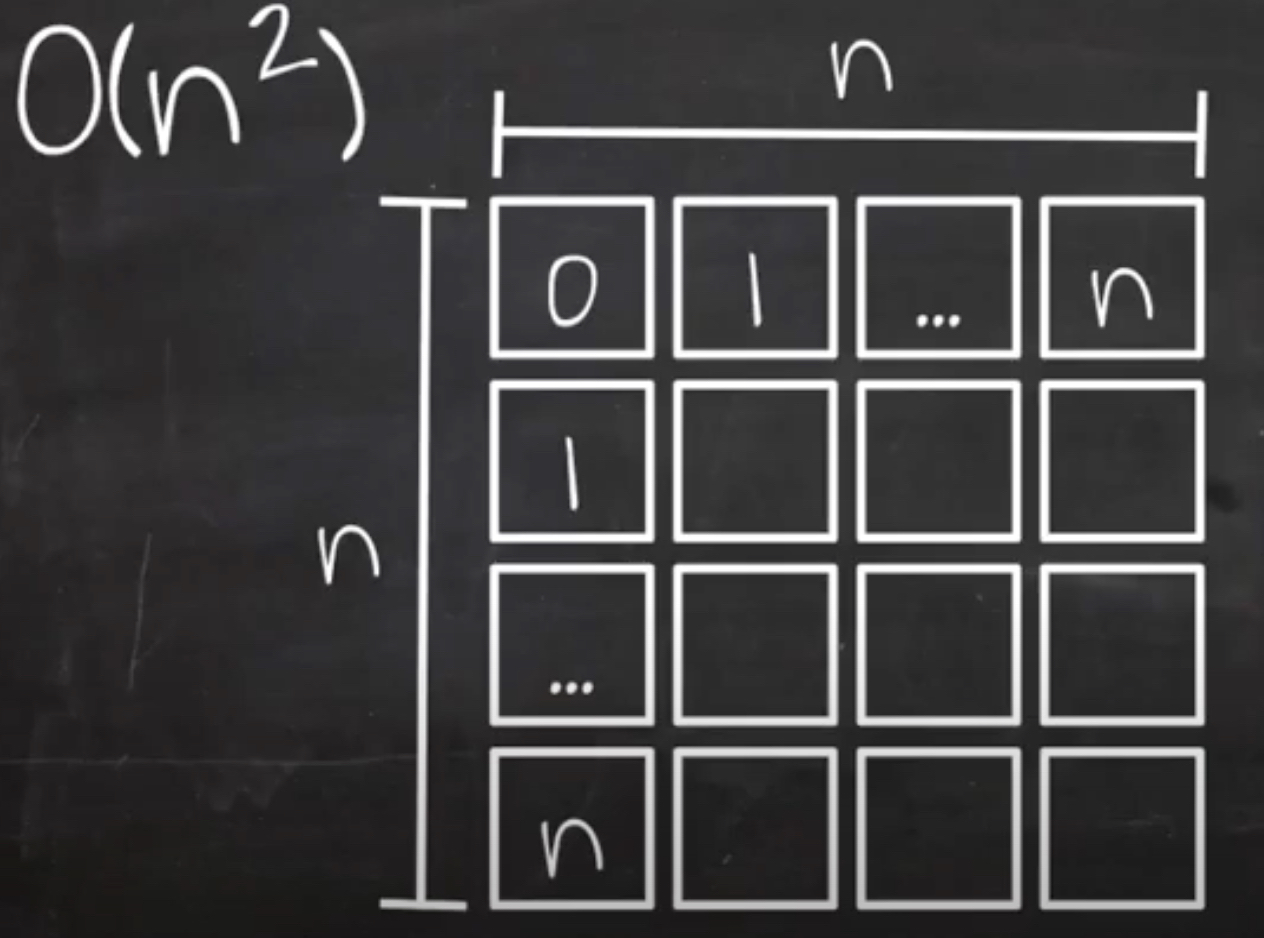
위 함수는 O(n^2)의 시간복잡도를 가지게 됩니다.
- n에 대해 n만큼 반복
이유는 이중 for문을 돌게 되는 것인데요 input값이 array이고 그 길이가 3인경우
첫번째 배열에서 배열의 길이만큼 다시 반복문을 돌게 됩니다. [0]번째 배열에서 [2]만큼 일을 하는거죠
그리고 이를 [2][2]만큼이 될 때까지 반복해야 함수의 처리가 끝나므로 정사각형의 형태인
O(n^2)의 시간복잡도를 가진다고 할 수 있습니다.
제곱이 되었으므로 이차함수 그래프를 그리게 된다.
O(nm)
const Onm=(aryN,aryM)=>{
for(let i=0;i<aryN.length;i++){
for(let j=0;j<aryM.length;j++){
console.log('i, j',i, j);
}
}
}
위 코드는 바로 직전에 본 O(n^2) 와 비슷하게 생겼습니다.
하지만 다른 점은
- n에대해 m만큼 반복
즉 n과 m이 다른 수이라는 겁니다. m의 값이 커지는 경우 n루프에서 m을 기다리는 시간이 늘어나겠죠?
반대로 m의 값이 작다면 n은 m의 루프가 끝나는 것을 지루해하지 않을것입니다.
이 notation은 m의 값에 따라 그래프 형태가 좀 많이 바뀌므로 그래프에 없는 것 같습니다.
n>m 인 경우 O(n^2)의 그래프의 기하급수적 상승 구간이 더 뒤로 늦춰지는 그래프일 것입니다.
n=m인 경우 O(n^2)의 그래프와 같습니다.
n<m인 경우 O(n^2)의 그래프보다 더 일찍 기하급수적 상승이 나타날 것입니다.
O(n^3)
const Ocube = (ary)=>{
for(let i=0;i<ary.length;i++){
for(let j=0;j<ary.length;j++){
for(let p=0;p<ary.length;p++){
console.log('i, j, p',i,j,p);
}
}
}
}위 코드는 O(n^3)의 시간복잡도를 나타냅니다.
ary의 길이만큼 직선 => 평면 => 입체의 형태로 일을 하는 것입니다.
배열의 길이만큼 3번씩 일을 하게 되므로 O(n^3)의 형태를 가지게 됩니다.
 사진 출처
사진 출처
O(2^n)
const fibo=(n)=>{
if(n<=0) return 0;
else if(n<2) return n;
return fibo(n-1)+fibo(n-2);
}피보나치 수열의 재귀 함수 구현의 경우 시간복잡도는 O(2^n)의 시간복잡도를 가지게 된다.
이유는 재귀 함수를 두 번 호출하기 때문인데 도움이 되는 시각자료를 보면 이해가 훨씬 쉽다.
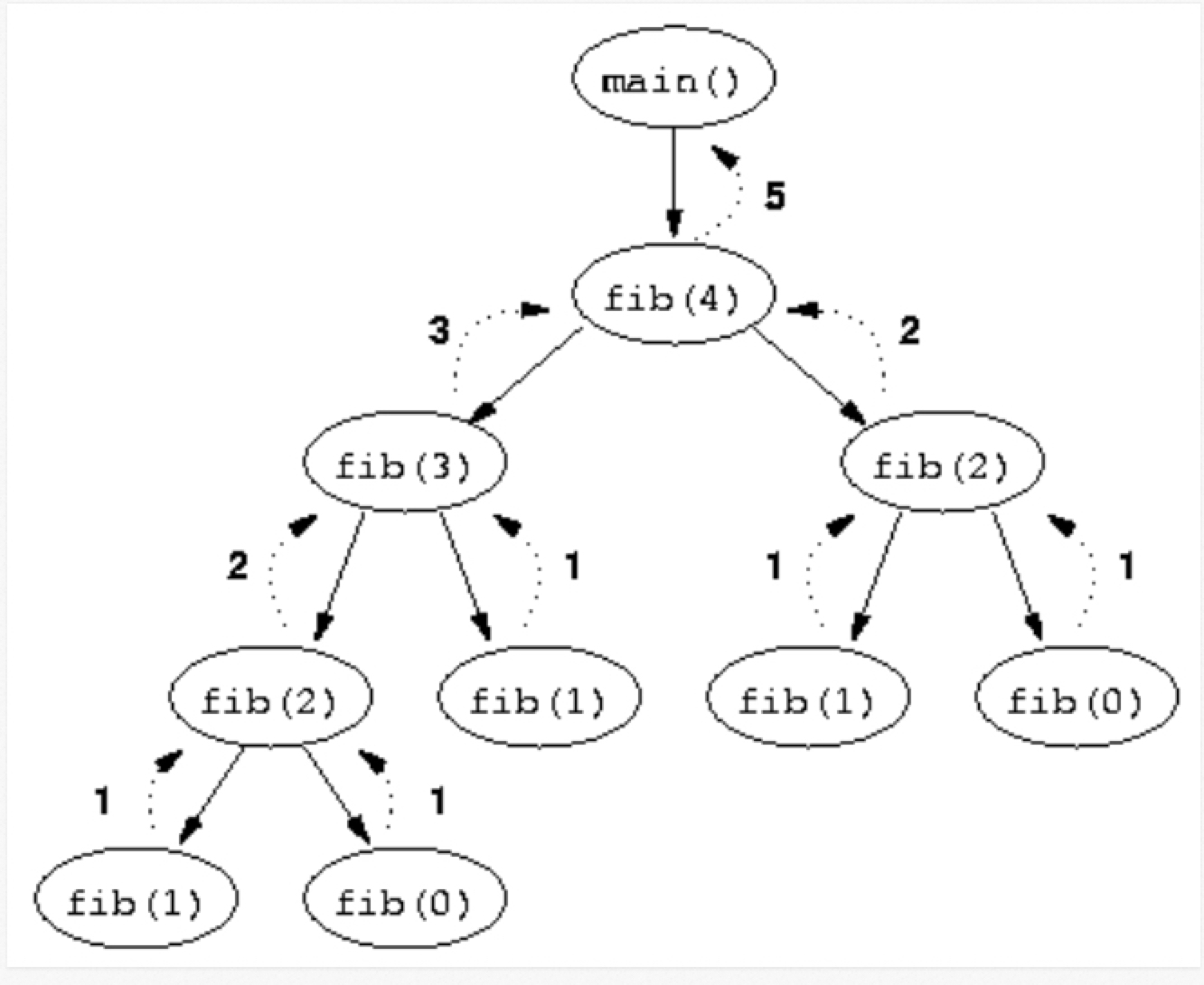
사진을 보게 되면 한번의 함수 호출로 두 개의 recursive가 발생하기 때문에 2^n만큼의 일이 발생하는 것이다.
메모이제이션 된 코드는 아래와 같다.
let f = [];
let fibo = (n) => {
if (f[n] !== undefined) {
return f[n];
} else {
if (n === 1 || n === 2) {
f[n] = 1;
} else {
f[n] = fibo(n - 1) + fibo(n - 2);
}
return f[n];
}
};
console.log(fibo(6));그래프는 2^n보다 더 극악한 성능을 나타낸다 이런 재귀를 왜 사용하는 것일까?
메모이제이션을 사용하지 않는다면 쓰지 않는게 좋을 것 같다.
속도가 빠른 O notation
O(log n)
const binarySearch = (key, arr) => {
let low = 0;
let high = arr.length - 1;
while (low <= high) {
const mid = Math.floor((low + high) / 2);
const guess = arr[mid];
if (guess === key) return mid;
if (guess > key) {
high = mid - 1;
} else {
low = mid + 1;
}
}
return null;
};
console.log(binarySearch(4, [2, 4, 6, 7, 8, 10, 22]));대표적인 케이스는 binary search 이분탐색 혹은 이진 탐색 혹은 이진 검색.. 등등의 이름을 가지고 있죠.
만약 이분탐색만 알고 이진탐색은 뭐지? 이러고 있으면 낭패를 볼 수 있습니다.
아무튼 위의 코드는 오름차순 정렬된 배열을 받아 low부터 (혹은 start) high (혹은 end)까지의 중간값인 mid 값으로 이 값이 찾고 있는 key 값과 일치하는지 보고 key 값이 mid의 배열의 값인 guess값보다 크면 low값을 mid+1로 높여주어 mid 이하의 값들은 탐색하지 않는 방법을 취합니다.
이를 계산해보면
처음 입력된 배열의 갯수가 n이라 합시다.
처음 서칭으로 찾을 배열의 갯수는 이 되고
못찾은 경우 그 다음 서칭으로 다시 이죠
이걸 찾을때까지 반복하므로 정리해보면
이므로 n을 밖으로 빼주고 중복되는 을 k 제곱 해주면
이런 식이 만들어진다.
이때
k = binarySearch가 실행된 실행 횟수입니다.
n = 배열의 갯수이죠
즉 배열의 갯수를 계속 씩 줄여 나가면서 찾는 것입니다.
여기서 배열의 길이가 1이 되면 key와 일치하는 값을 찾게 되는 것입니다.
= 종료
이는 값에 을 몇번 곱하는 것으로 1이 나오는지를 알아내는 과정인 것이죠
식을 다시 써보면
입니다. 여기에 를 곱해주면 좌변은 n만 남고 우변은 가 됩니다.
이제 이걸 로그로 표현해주면 밑이 2고 2를 n이 되게 하는 지수 k를 나타내는게 로그 표현이므로
여기서 2는 보통 생략합니다.
따라서 많이 보게 되는 이라는 값이 나오게 됩니다.
k = binarySearch의 시행 횟수이므로 이를 log로 표현해주면 됩니다.
사진 출처
그래프를 보시게 되면 O(log n)은 준수한 속도를 나타냅니다.
big - O 표기법은 위의 로그 계산에서 상수를 버려버립니다.
이유는 해당 알고리즘의 시간을 측정하기 위함이 아니라 알고리즘을 사용하면서 변수에 따른 시간 증가율을
확인하기 위한 표기법이기 때문이죠.
상수는 항상 상수만큼만의 증가율을 보여주기 때문에 이미 고정된 값이라는 것이죠. 따라서 big-O 표기법에서는 생략하게 됩니다.
이정도만 알고 있어도 크게 문제 없지 않을까요?
