이 포스팅의 정보는 공식적이지 않습니다.
지난 시간에는 라프텔 API를 사용해 라프텔의 DB 정보를 크롤링하는 코드를 만들었다. 각각의 분기마다 방영된 애니메이션은 지난 시간의 포스팅에 사용한 코드로 충분히 크롤링할 수 있다. 여기까지는 라프텔 본 홈페이지에서도 할 수 있는 것이므로, 이번에는 라프텔 본 홈페이지에서 지원하지 않는 기능을 간단하게 만들어보자.
이번 분기 가장 많이 방영된 애니메이션 장르
라프텔이 등록해놓은 태그를 이용해, 이번 분기에 갖아 많이 방영된 애니메이션의 장르(판타지 / 로맨스 / 액션 등)을 알아보자.
라프텔은 동일 애니메이션에 대해 동일 태그를 2번씩이나 등록하지 않았을 것이므로, 이번 분기 애니메이션 중 가장 많이 태그된 태그를 랭킹 순으로 출력하는 프로그램을 만들어보자.
2019년 3분기에서 가장 많이 태그된 애니메이션을 알아보자.
from urllib.parse import quote
import csv
import requests
import json
import random
import time
# divisions = ["2017년 3분기", "2017년 4분기"]
# divisions.extend([f'2018년 {x}분기' for x in range(1,5)])
# divisions.extend([f'2019년 {x}분기' for x in range(1,5)])
# divisions.extend([f'2020년 {x}분기' for x in range(1,3)])
next = ""
print ("==============================")
divisions = ["2019년 3분기"]
tags = {}
for y in divisions:
encoding = quote(y)
header = {'laftel' : 'TeJava'}
laftel_API = 'https://laftel.net/api/search/v1/discover/?years=' + str(encoding)
json_data = {"anime" : []}
while(True):
response = requests.get(url = laftel_API, headers = header)
json_read = response.json()
results = json_read["results"]
for x in results:
genres = x["genres"]
for z in genres:
if (z not in tags):
tags[z] = 1
else:
tags[z] += 1
next = json_read["next"]
if (next is not None):
laftel_API = next
else:
break
time.sleep(random.randint(1, 2))
print(y, "데이터 분류 완료!")
sorted_results = sorted(tags.items(), key = lambda item: -item[1])
for key, value in sorted_results:
print(f'tag = {key}, count = {value}')이 코드를 실행해보면, 2019년 3분기에 방영된 애니메이션 중에서 어떤 종류의 애니메이션이 가장 많이 방영되었는지 알 수 있다. 2017년 1분기부터 2020년 2분기까지의 모든 분기에 대해 수행해보고, 그 분기 탑 3의 태그를 출력해보면 다음과 같다.
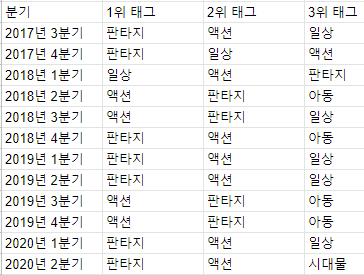
유의미한 결과가 되지는 않았다.

코딩한량.