
인공지능을 공부하다 보면 옵티마이저(optimizer)가 등장한다. 인공지능 모델은 학습할 때 예측과 정답의 차이를 줄여 나간다. 그 차이는 손실함수(loss function)에 의해 결정된다. 옵티마이저는 그 차이를 줄이기 위한 방법과 방향 그리고 속도를 결정하는 녀석이다. 그래서 나는 옵티마이저를 파라미터의 길잡이라고 생각한다.
Gradient방향
경사하강법(Gradient Descent)은 옵티마이저 알고리즘의 아버지이며 가장 중요한 이론이다.
경사하강법을 알기 전에 Gradient를 먼저 알아야 한다. (간단하다.)
다변수함수 f가 다음과 같이 있을 때
gradient는 다음과 같다.
보는 것과 같이, gradient는 f를 x와 y로 편미분을 차례대로 하여 벡터화한 것이다. 단순해 보이지만 gradient에는 엄청난 특징이 있다. 바로 Gradient방향은 함수가 가장 빨리 증가 하는 방향이라는 것이다.
예를 들어 점f(1, 1)이 f에서 가장 빨리 증가하는 방향은 위의 식에 대입해 보면 (2, 2)이다.(여기서 (2, 2)는 벡터로 방향을 가진다.)
gradient방향이 함수가 가장 빨리 증가한다는 사실은 이미 증명된 사실이다.
이 사실을 통해 한 가지 더 알 수 있는 것은 -gradient방향은 가장 빨리 감소하는 방향이라는 것이다.
경사하강법
손실함수와 파라미터가 주어졌을 때를 생각해보자.
손실함수를 MSE(Mean Square Error) 파라미터를 W(weight)라고 하자.
MSE가 위의 예시에서 f의 역할을 하고, W가 x, y의 역할을 한다. MSE에 W가 없는 것 처럼 보이지만 H(W)를 포함하는 합성함수로 생각하면 이해가 될 것이다.
더 좋은 예측을 위해 손실함수가 가장 빨리 감소하는 방향으로 파라미터를 옮기는 것이 경사하강법(Gradient Descent)이다.
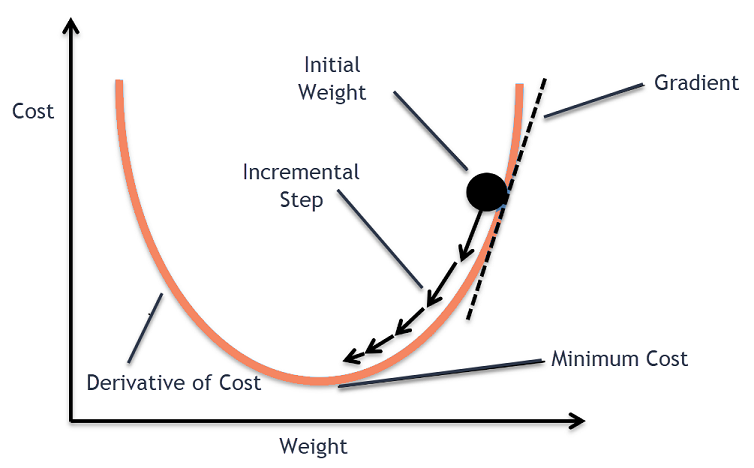
출처: https://editor.analyticsvidhya.com/uploads/631731_P7z2BKhd0R-9uyn9ThDasA.png
위 그림은 이해를 경사하강법의 이해를 돕기 위한 그림이다. x축이 W이고, y축이 Cost(손실함수)이다. 위 그림과 같이 gradient는 그 점에서의 기울기이다. 그림을 보면 알겠지만, 함수의 모양이 convex(아래로 볼록한 모양이라고 생각하면 편하다.)할 때 gradient의 반대방향이 항상 그 함수가 감소하는 방향이다. 따라서 위와 같이 W를 옮기는 것(Update)을 하나의 수식으로 표현할 수 있다.
이 식이 경사하강법(Gradient Descent)의 기본적인 형태이다. 위 식의 끝이 조금 긴 n과 비슷하게 생긴 친구의 이름은 에타(ETA)(기호이름)이다. 저 친구의 역할이 중요한데, 우리가 W를 업데이트할 때 그 속도를 조절한다. 학습하는 정도를 조절하기 때문에 학습률(learning rate)이라고 부른다.
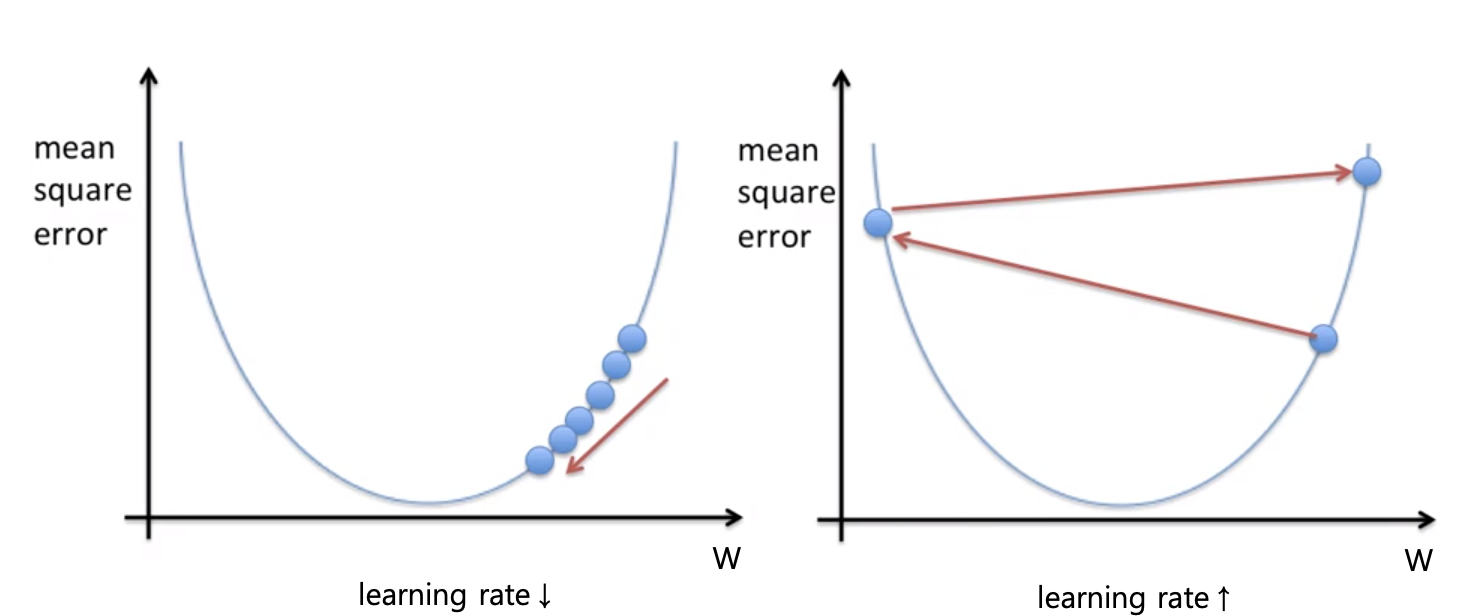
학습률이 너무 작은 경우에는 왼쪽의 그림처럼 목표를 달성하기 까지 오랜 시간이 걸릴 수 있다. 반대로 학습률이 너무 큰 경우에는 파라미터가 수렴하지 못하고 오히려 발산하여 영원히 학습이 끝나지 않을 수 있다. 따라서 학습률을 적절히 조정하는 것은 중요하다!
경사하강법의 한계
이렇게 멋있는 알고리즘이지만 경사하강법에는 크게 두 가지 한계가 존재한다.
1. 학습 속도가 느리다.
경사하강법은 파라미터를 업데이트할 때, 모든 데이터를 고려한 방향으로 업데이트한다. 즉, 데이터의 양이 많아질수록 학습 속도가 느려진다.
이를 보완하여 나온 알고리즘이 SGD(stochastic gradient descent)이다.
2. local minimum에 빠질 수 있다.
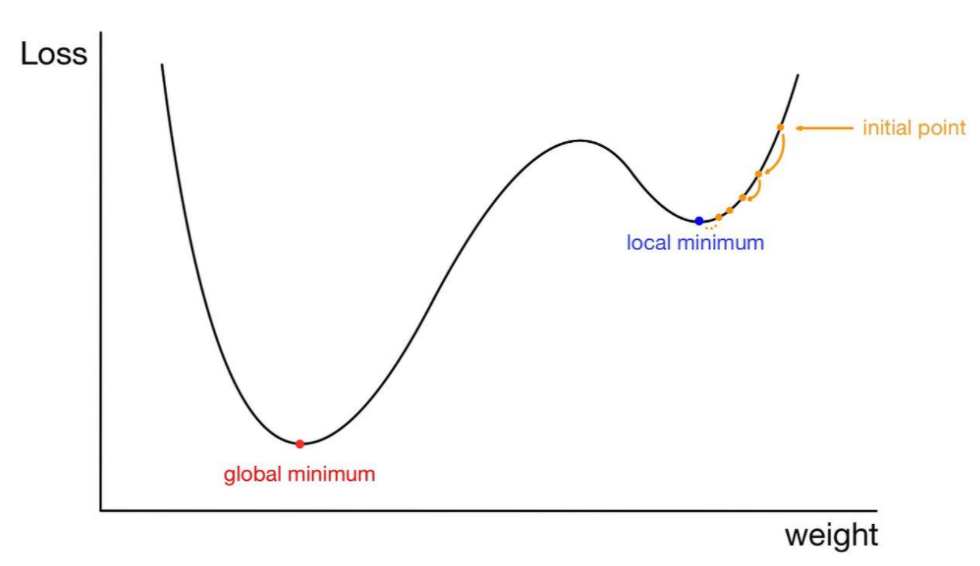
위 그림처럼 처음 시작하는 점의 위치와 함수의 모양에 따라서는 경사하강법은 local minimum에 빠질 수 있다.
이를 보완하여 나온 알고리즘이 Momentum이다.
다음에 SGD와 Momentum에 대해도 포스트할 것이다.

첫 번째 글이여서 많이 서툴고 제대로 설명하지 못한 것 같다. ㅠㅠ
내 블로그는 누가 읽어도 이해할 수 있는 글을 적고 싶어서 쉽게 적으려고 노력했다.
이 글을 읽고 조금이더라도 경사하강법에 대해 알고 갔으면 좋겠다.
궁금하거나 잘못된 부분이 있으면 댓글을 남겨주세요!

{kind=link}