
(1) 내장 톰캣을 가진다
-
웹서버 : 클라이언트가 요청하는 정적 컨텐츠를 전달하는 서버
-
웹 컨테이너 : Servlet, jsp를 실행할 수 있는 소프트웨어, 서블릿 컨테이너라고도 한다. 톰캣은 서블릿 컨테이너중 하나이다.
-
요청을 받을시 서블릿 컨테이너(톰캣)가 request, response 객체를 생성한다. (톰캣에서 BufferedWriter, BufferedReader를 통해 요청으로부터 가변길이의 문자를 받고 request, response 객체를 생성)
-
이후 요청에 매핑된 서블릿이나 프론트 컨트롤러로 전달
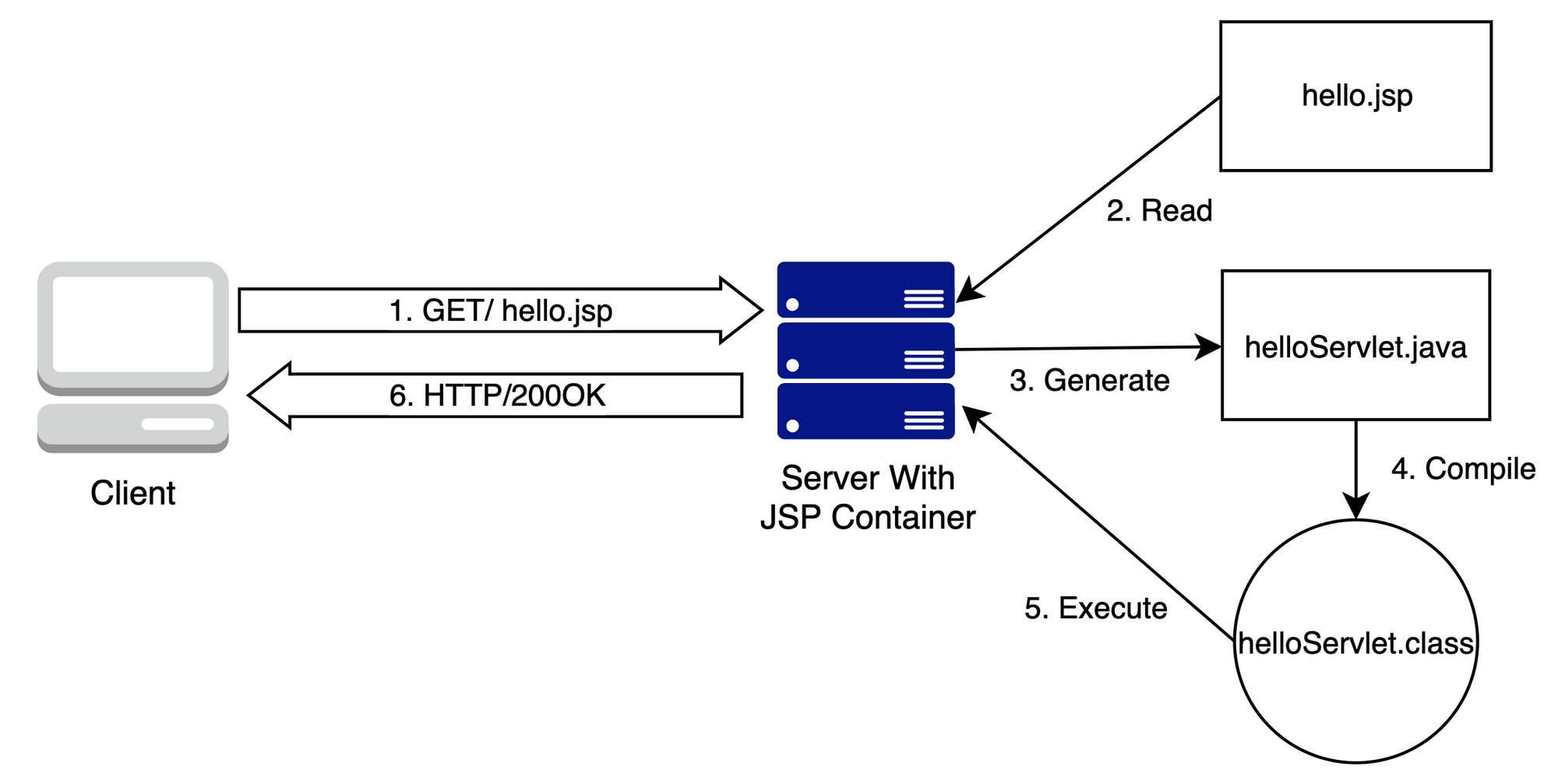
JSP 파일을 요청했을 때 동작.
-
클라이언트가 어떤 동작을 함으로써 hello.jsp 를 요청.
-
클라이언트가 JSP 파일을 요청할 경우 제어권이 서블릿컨테이너(톰캣)로 넘어감
-
JSP 컨테이너가 JSP 파일을 읽는다.
-
JSP 컨테이너가 Generete (변환) 작업을 통해 Servlet ( .java ) 파일을 생성한다.
-
.java 파일은 다시 .class 파일로 컴파일된다.
-
Execute (실행) 을통해 HTML 파일을 생성하여 웹서버에게 전달한다.
-
HTTP 프로토콜을 통해 HTML 페이지를 클라이언트 에게 전달한다.
URI 식별자 접근을 통한 서블릿 실행
-
스프링에서는 URL을 통한 자원 접근 X, URI를 통한 식별자 접근 → 특정한 파일 요청을 할 수 없고 요청시에는 무조건 자바를 거친다
URL (자원 접근) : http://www.naver.com/a.png
URI (식별자 접근) : http://www.naver.com/picture/a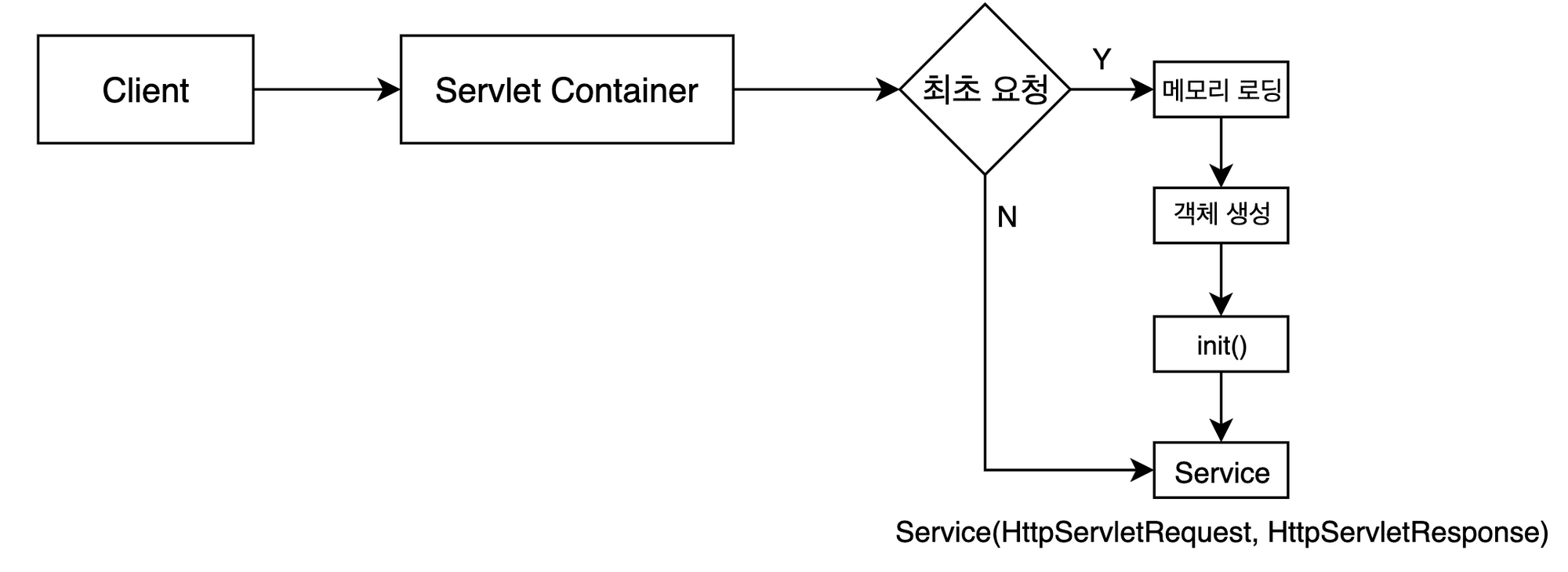
-
최초 요청시 첫번째 쓰레드에서 서블릿 객체 실행 (new) → 힙 메모리에 인스턴스 정보 올라감(메소드)
-
생성된 스레드는 응답 후에도 종료되지 않고 (힙 메모리 유지) 똑같은 요청이 들어올 시 독립된 스택공간에서 메소드 실행 후 응답
-
여러 사용자가 동시에 요청시 쓰레드의 갯수가 늘어남(최대 20이라 가정)
-
최대 쓰레드 이상의 사용자가 요청 시 대기하다가 응답이 종료된 쓰레드부터 재사용 (pooling)
참고로 알아 둘 지식 : 동시 최대 쓰레드의 설정은 컴퓨터 성능에 의존함,
이 때 두가지 방식으로 동시 최대쓰레드의 갯수를 늘릴 수 있음
Scale Up : 컴퓨터의 성능 자체를 상향시키는 방법
Scalue Out : 배치방식으로 분산처리로 여러대의 컴퓨터가 처리하도록 함
-
(2) 웹 애플리케이션 배포설명자 web.xml
- 웹 애플리케이션 배포설명자란? → 애플리케이션의 클래스, 리소스 구성 및 웹서버가 이를 사용해서 요청을 처리하는 방법을 기술하는곳
- web.xml에 작성되는 내용
- ServletContext의 초기 파라미터
- Session의 유효시간 설정
- Servlet/JSP에 대한 정의 & Mapping
참고로 Servlet/JSP Mapping시(web.xml에 직접 매핑 or
@WebServlet어노테이션 사용)에 모든 클래스에 Mapping을 적용시키기에는 코드가 너무 복잡해지기 때문에 FrontController 패턴을 이용함. - Mime Type Mapping
- Welcome FileList
- ErrorPage 처리(Error Handling)
- 리스너/ 필터 설정
- 보안
- Spring에서의 web.xml
- Dispatcher Serlvet
- ContextLoaderListener
- Encoding Filter
(3)FrontController 패턴
모든 클래스에 Mapping을 적용시키기에는 코드가 너무 복잡해짐 → 최초 앞단에서 request 요청을 받아서 컨트롤러를 통해 필요한 클래스에 넘겨준다
- 서블릿 하나로 클라이언트의 요청을 받음
- 프런트 컨트롤러가 요청에 맞는 컨트롤러를 찾아서 호출
- 프런트 컨트롤러를 제외한 나머지 컨트롤러는 서블릿을 사용하지 않아도 됨
- 정리하자면, FrontController는 공통 코드를 처리하고 요청에 맞는 컨트롤러를 매핑해주는 역할 (앞서 언급한 Servlet, JSP를 통한 MVC 패턴의 단점 해결)
- ex) 스프링 웹 MVC의 DispatcherServlet
- 이 때 새로운 요청이 생기기 때문에 request, response가 새롭게 생성(new)될 수 있다 그래서 필요한 것이 RequestDispatcher → 필요한 클래스 요청이 도달했을 때 FrontController에 도착한 request, response를 그대로 유지시켜준다.
RequestDispatcher란?
RequestDispatcher는 클라이언트로부터 최초에 들어온 요청을 JSP/Servlet 내에서 원하는 자원으로 요청을 넘기는(보내는) 역할을 수행하거나, 특정 자원에 처리를 요청하고 처리 결과를 얻어오는 기능을 수행하는 클래스, 페이지간 데이터 이동이 가능하게 해줌
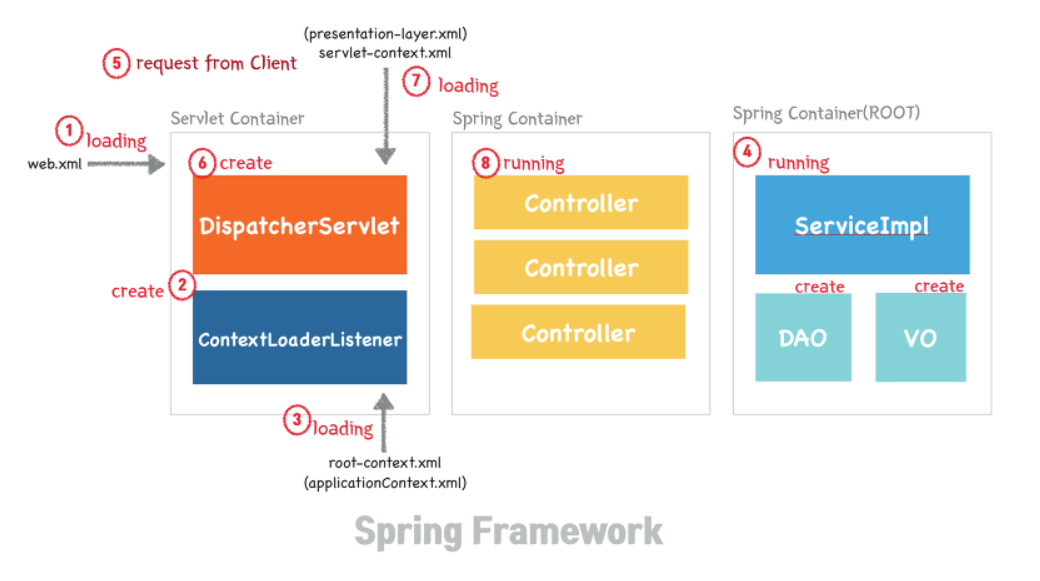
(4)DispatcherServlet
스프링에서는 FrontController 패텅을 직접 짜거나 RequestDispatcher를 직접 구현할 필요가 없다. 스프링 프레임워크에는 DispatcherServlet이 있기 때문,
- DispatcherServlet은 FrontController 패턴 + RequestDispatcher 이다.
- DispatcherServlet이 생성될 때 컴포넌트 스캔을 통해 수많은 객체가 IoC컨테이너에 등록된다. 이들은 보통 필터들이며, 해당 필터들은 내가 직접 등록할 수도 있고 기본적으로 필요한 필터들은 자동으로 등록됨
- IoC 컨테이너에 컴포넌트를 올린 후 주소를 분배할 수 있게 된다
- DispatcherServlet이 등장함에 따라 web.xml의 역할을 상당히 축소되었음
(5)스프링 컨테이너
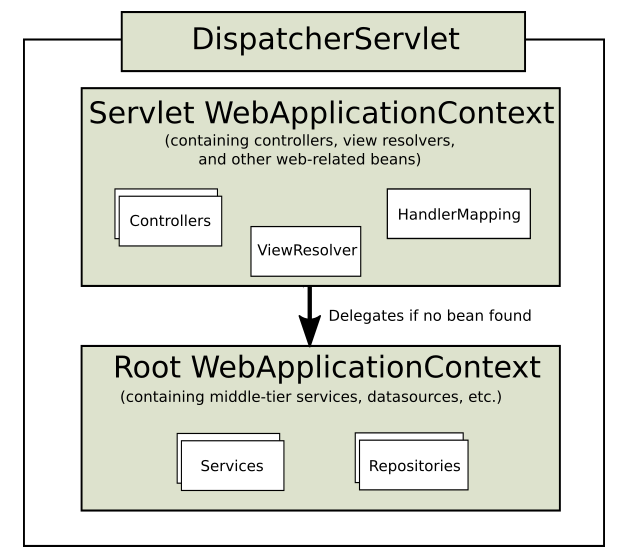
DispatcherServlet에 의해 생성되는 수많은 객체들은 어디에서 관리될까?
Application Context
- Dispatcher 서블릿이 생성되기 전에 web.xml에서 ContextLoaderListener를 실행시킨다. ContextLoaderListener에서 모든 요청, 모든 스레드에서 공통적으로 사용하는 요소(DB 관련 객체, Service, Repository)를 스캔하고 Application Context에 등록(root_ApplicationContext파일에 정의) → root-applicationContext
- Dispatcher Servlet의 컴포넌트 스캔을 통해 수많은 객체들이 Application Context에 등록됨 (IoC) → servlet-applicationContext
- 개발자가 객체를 생성하고 레퍼런스 변수를 관리하는것은 어렵다. 그래서 스프링이 직접 객체를 관리한다. 따라서 개발자는 주소를 몰라도 되고 필요할때 Application Context로부터 DI하면 된다.
- Application Context는 싱글톤으로 관리되기 때문에 어디에서 접근하든 동일한 객체라는 것이 보장된다.
BeanFactory
- 필요한 객체를 Bean Factory에 등록할 수도 있음
- 특정 메소드가 리턴하는 객체가 있다면, 메소드에
@Bean어노테이션을 붙혀 사용 - 이 때 초기에 메모리에 로드되지 않고 필요할때 getBean()이라는 메소드를 통하여 메모리에 로드하고 호출할 수 있음. 이 또한 IoC이며 필요할때 DI하여 사용할 수 있음
- Application Context와 다른점은 미리로드 되지 않는다는 점, 즉 lazy-loading이 가능하다는점이다.
(6) 요청 주소에 따른 적절한 컨트롤러 요청(Handler Mapping)
특정 주소 요청이 오면 (HTTP Method에 따라) 적절한 컨트롤러의 함수를 찾아서 실행한다
(7) 응답
- html파일을 응답할지 Data를 응답할지 결정해야 하는데 html 파일을 응답하게 되면 ViewResolver가 관여하게 된다.
- Data를 응답하게 되면 (리턴 타입이 객체)MessageConverter가 작동하게 되는데 메시지를 컨버팅할 때 기본전략은 json이다. (
@ResponseBody)

{kind=link}
좋아요, 필터를 이해하고 구현하는 데 좋은 계획인 것 같네요! 로깅이나 인증 같은 일반적인 작업에 대한 요청을 가로채야 할 필요성을 정확히 파악하셨고, Java EE와 Spring Boot 모두에서 필터를 통해 이를 구현할 수 있다는 점에 대해서도 정확히 지적하셨습니다. e-zpassny com