📌 Hash Table
해시 테이블은 '키-값'쌍을 저장하는 자료구조입니다. 평균적으로 빠른 검색과 삽입이 가능하지만, 해시 함수 품질과 해시 충돌을 처리하는 방법이 중요합니다.
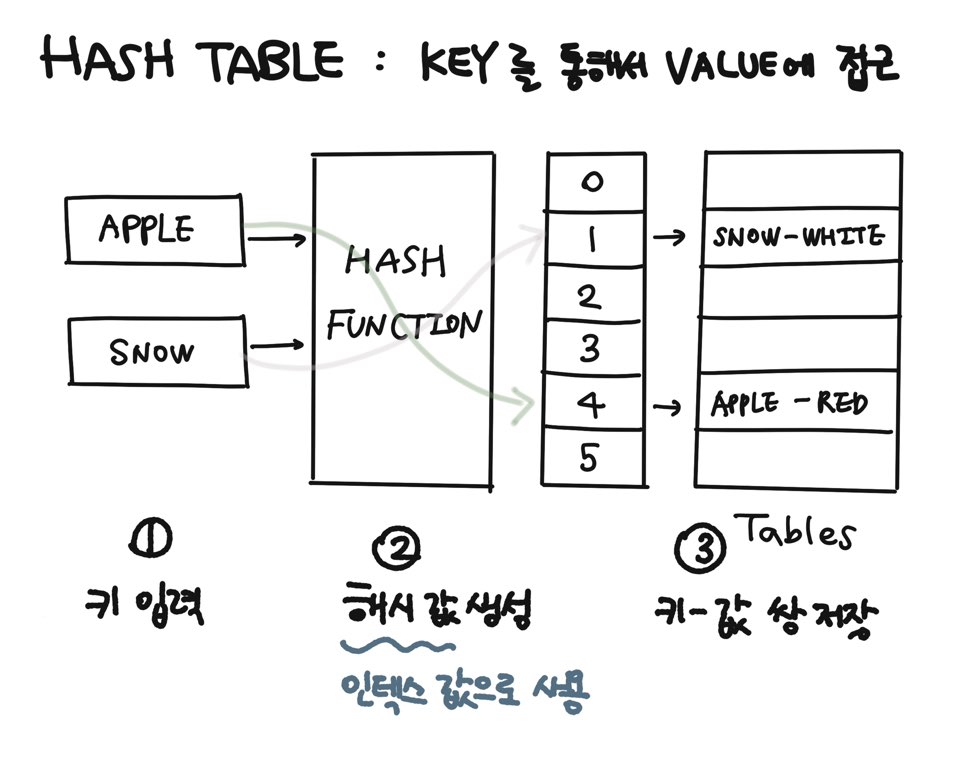
✅ 데이터 저장
- 키 입력: 키 값인 Apple을
해시 함수에 입력 - 해시 값 생성: 해시 함수가 키를 인덱스
4로 변환 - 해시 테이블에 저장: 생성된 해시 값을 사용해 해시 테이블에서 인덱스
[4]에 키-값Apple-Red쌍을 저장
✅ 데이터 접근
- 키 입력: 검색하는 키를 해시 함수에 입력
- 해시 값 변환: 해시 함수가 키를 해시 값으로 변환
- 해시 테이블에서 검색: 해시 값을 사용해 데이터가 저장된 위치에 접근해 값을 가져옴
✅ 시간 복잡도
삽입, 삭제, 검색 모두 평균적으로 O(1), 충돌이 많은 최악의 경우에는 O(n)
✅ 해시 충돌
만약 서로 다른 키 값이 해싱을 통해 동일한 인덱스를 얻어 해싱 충돌이 발생하는 경우에는 체이닝이나 개방 주소법등을 사용해 충돌을 해결할 수 있습니다.
- 체이닝 (분리 연결): 충돌이 발생한 인덱스에 연결 리스트를 두어 여러 키-값 쌍을 저장할 수 있도록 하는 방법입니다.
- 오픈 어드레스 (개방 주소법): 해당 위치에서 다음 위치로 이동하며 빈 인덱스를 찾아 저장하는 방법으로, 군집화 문제가 발생할 수 있습니다.
✅ Hash라는 이름이 들어가지만 서로 다른 자료구조
HashTable, HashMap, HashSet, LinkedHashSet은 모두 다른 자료구조입니다.
| 자료구조 | 저장 구조 | 동기화 지원 여부 | Null 허용 | 순서 보장 여부 | 중복 허용 여부 | 사용 목적 |
|---|---|---|---|---|---|---|
| HashTable | Key-Value 쌍 저장 | 동기화 지원 | Null 허용 안 함 | 순서 보장 안 됨 | 중복 허용 안 됨 | 멀티스레드 환경에서 동기화된 해시맵 |
| HashMap | Key-Value 쌍 저장 | 동기화 미지원 | Key와 Value에 Null 허용 | 순서 보장 안 됨 | 중복 허용 안 됨 | 일반적인 해시 기반 맵 |
| HashSet | 값만 저장 (Set) | 동기화 미지원 | Null 허용 | 순서 보장 안 됨 | 중복 허용 안 됨 | 중복되지 않는 값을 관리할 때 사용 |
| LinkedHashSet | 값만 저장 (Set) | 동기화 미지원 | Null 허용 | 삽입 순서 보장 | 중복 허용 안 됨 | 삽입 순서를 유지하며 중복을 허용하지 않을 때 사용 |
📌 Linked List
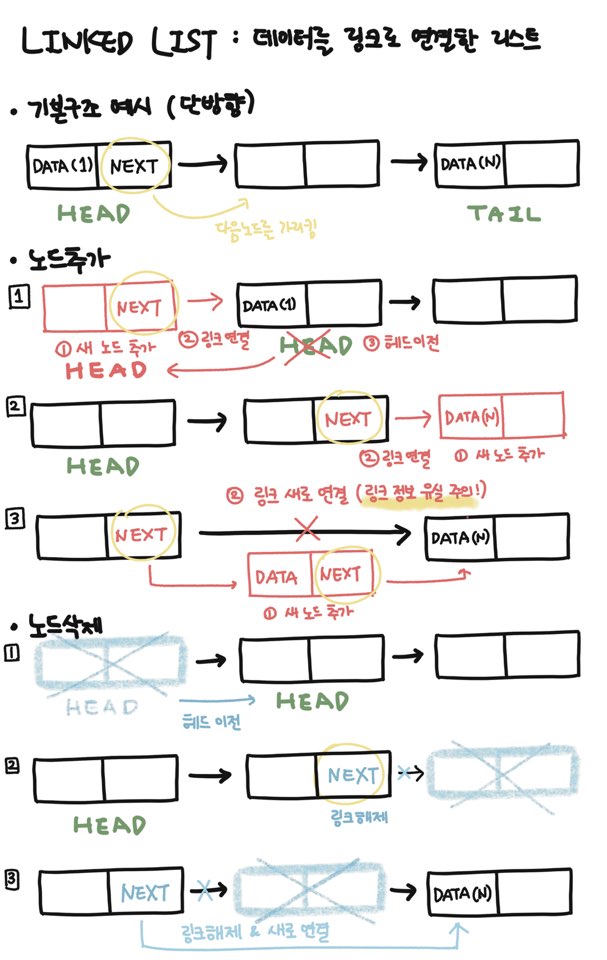
연결 리스트는 노드로 이루어진 자료 구조입니다. 각 노드는 데이터와 포인터를 포함하고 있습니다. 각 포인터는 다음 노드가 위치한 메모리 주소를 저장하는 방법으로 노드들 간의 연결을 유지합니다. 동적으로 메모리에 할당하기 좋지만 검색 성능이 낮고 포인터 관리가 중요합니다.
✅ 노드 추가
- 처음에 추가: 새 노드 생성 -> 포인터를 기존 첫 번째 노드로 연결 -> 시작 포인터(헤드)를 새 노드로 이전
- 끝에 추가: 새 노드 생성 -> 기존 마지막 노드의 포인터를 새 노드로 연결 -> 새 노드 포인터는 NULL로 설정
- 중간에 추가: 새 노드 생성 -> 이전 노드 포인터를 새 노드와 연결하고, 새 노드는 다음 노드와 연결
✅ 노드 삭제
- 처음 삭제: 첫 노드 삭제 후 시작 포인터를 다음 노드로 이전
- 끝 삭제: 끝 노드를 삭제 후 이전 노드 포인터는 NULL로 설정
- 중간 삭제: 삭제할 노드의 이전 노드가 삭제할 노드의 이후 노드와 연결되도록 포인터 설정 (사용되지 않는 중간 노드는 GC에 의해 제거된다)
아래는 단방향 연결 리스트의 예시로 그린 그림입니다.
✅ 특징
- 각 노드는 메모리상에서 연속되지 않은 위치에 저장
- 동적으로 메모리는 할당할 수 있음
- 삽입과 삭제가 빠른 편
- 특정 노드에 접근하기 위해서는 순차적으로 검색해야 하므로 접근 시간이 길 수 있음
- 단일 연결 리스트, 이중 연결 리스트 (포인터가 이전과 다음 노드를 가리킴), 원형 연결 리스트 (마지막 노드가 첫 노드를 가리킴) 등이 있음
✅ 시간 복잡도
특정 노드를 삽입, 삭제할 때는 O(1), 검색은 O(n)
📌 Heap
힙은 특정한 순서 규칙을 따르는 트리 기반의 자료 구조입니다. 가장 크거나 가장 작은 값을 효율적으로 찾거나 제거할 수 있습니다.
✅ 종류
- 최소 힙: 부모 노드는 항상 자식 노드보다 작거나 같음 (가장 큰 값은 루트 노드 값)
- 최대 힙: 부모 노드는 항상 자식 노드보다 크거나 같음 (가장 작은 값은 루트 노드 값)
✅ 주요 연산
- 삽입 (heapify up): 새 노드는 트리 가장 마지막에 추가한 후 해당 힙의 속성(최소 힙 vs 최대 힙)을 만족할 때까지 부모 노드와 비교해서 올라가며 위치를 조정합니다. (아래 그림 설명에서 노란색 하이라이트 부분)
- 삭제 (heapify down): 루트 노드를 제거 후 마지막 노드를 루트 노드 자리로 이동 후, 해당 힙 속성을 만족할 때까지 자식 노드와 비교해서 내려가며 위치를 조정합니다. 루트 노드의 값 다음으로 우선순위가 높은 노드를 추출하는 데 사용할 수 있습니다.
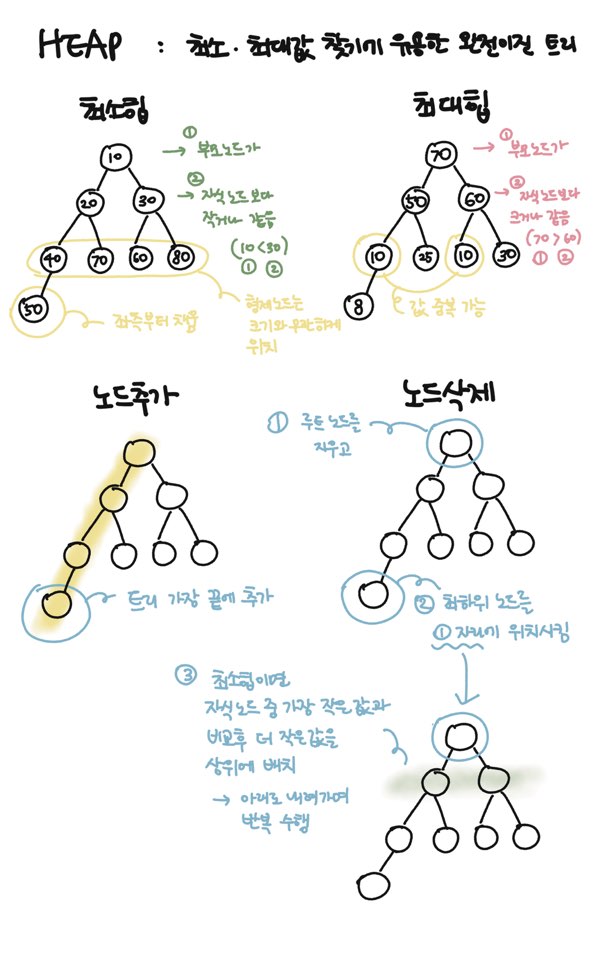
✅ 특징
- 완전 이진 트리: 모든 트리가 완전히 채워져 있고, 마지막 레벨은 왼쪽부터 채웁니다.
- 부분적 정렬: 부모-자식 간에는 대소 관계가 있지만 형제 노드 간엔 적용되지 않습니다.
- 우선순위 큐 구현: 최우선 순위가 되는 요소(트리상 루트 노드에 있는 값)을 빠르게 찾을 수 있습니다.
✅ 시간 복잡도
- 삽입, 삭제할 때는
O(log n): 완전 이진 트리 구조에서 트리 높이가 log n이기 때문에, 노드가 최상단이나 최하단으로 움직이는 최악의 경우를 고려했을 때 O(log n)이 소요 - 최소/최대값 검색시
O(1)
1. JPA가 DB에서 객체를 가져올 때 protected 생성자와 private 생성자의 차이
- JPA는 리플렉션(reflection)이라는 기술을 사용하여 데이터베이스에서 객체를 가져올 때 자동으로 객체를 생성합니다.
- JPA는 리플렉션을 통해 생성자에 직접 접근해 객체를 생성할 수 있습니다. 이때, JPA는
protected생성자에 접근할 수 있지만,private생성자에는 접근하지 못합니다. 그래서 JPA는 기본적으로protected나public생성자를 요구합니다. private생성자는 오직 해당 클래스 내부에서만 사용할 수 있으므로, JPA가 이를 사용할 수 없습니다. 그래서 JPA가 객체를 생성할 때는protected생성자를 사용하여 객체를 초기화하게 됩니다.
2. 댓글을 LinkedHashSet으로 관리해서 중복을 허용하지 않게 됐는데, 중복의 기준은 무엇인가?
LinkedHashSet은 객체의equals()와hashCode()메서드를 기반으로 중복 여부를 판단합니다.- 같은 content를 가진 댓글을 작성하더라도,
equals()와hashCode()기준에 따라 중복 여부가 판단됩니다. - 현재
equals()와hashCode()메서드가id필드를 기준으로 작성되어 있으므로,id가 다르면 동일한 content를 가진 댓글이라도 중복으로 처리되지 않습니다. 즉,id가 유일하다면, content, createdAt, createdBy 등이 달라도 댓글이 각각 등록될 수 있습니다.
3. hashCode() 메서드를 id 필드를 기준으로 재정의한 이유
hashCode()메서드를id필드를 기준으로 재정의하면, 이 객체가 해시 기반 컬렉션(HashSet,HashMap)에서 어떻게 처리될지 결정됩니다.- 재정의된
hashCode()메서드를 통해Article객체가id를 기준으로 중복되지 않도록 관리할 수 있습니다. 즉, 같은id를 가진 객체는 같은 해시 값을 가지게 되어, 중복으로 간주됩니다. - 이는 해시 기반 컬렉션에서 중복 저장을 방지하고, 빠르게 조회하는 데 사용됩니다.
4. HashTable, HashMap, HashSet은 서로 다른 자료구조라는 말이 맞는가?
- 네, 맞습니다. 이 세 가지는 각각 다른 자료구조입니다.
HashTable은 키-값 쌍을 저장하는 자료구조로, 동기화된 버전입니다.HashMap은 키-값 쌍을 저장하지만, 동기화되지 않은 버전으로 성능이 더 좋습니다.HashSet은 값만 저장하는 자료구조로, 중복을 허용하지 않고, 내부적으로HashMap을 사용하여 값을 관리합니다.
5. 표로 정리: HashTable, HashMap, HashSet의 차이점
6. 정적 팩토리 메서드(of)에 대한 쉬운 설명
- 정적 팩토리 메서드는 객체를 생성하는 특별한 메서드로, 일반적인
new키워드를 사용하지 않고 객체를 생성할 수 있게 합니다. of라는 메서드를 통해 객체를 생성하면 더 읽기 쉬운 코드가 됩니다. 예를 들어,Article.of("제목", "내용", "해시태그")처럼 사용할 수 있어 객체를 생성하는 의도가 더 명확하게 드러납니다.- 정적 팩토리 메서드는 클래스의 인스턴스를 반환하는 메서드이며, 추가적인 로직을 포함할 수 있는 유연한 방법입니다. 또한 생성자보다 더 설명적인 이름을 가질 수 있어서 가독성이 높아집니다.
7. hashCode() 메서드와 해시 기반 컬렉션 쉽게 설명
- 해시 기반 컬렉션(
HashSet,HashMap등)은 데이터를 저장할 때 해시 값이라는 숫자를 사용해 데이터의 위치를 정합니다. hashCode()메서드는 객체의 데이터를 기반으로 고유한 해시 값을 계산하는 메서드입니다.- 예를 들어,
Article객체에서id필드를 기준으로 해시 값을 만들면, 같은id를 가진 객체는 같은 해시 값을 가지므로, 중복되지 않고 저장될 수 있습니다. - 해시 기반 컬렉션의 장점은 데이터를 빠르게 찾을 수 있다는 것입니다. 해시 값을 기반으로 데이터를 적은 연산으로 효율적으로 저장하고 빠르게 검색할 수 있습니다.
예시:
- 만약
Article객체를HashSet에 저장할 때,hashCode()메서드가id를 기준으로 해시 값을 계산하면, 동일한id를 가진 두 객체는 중복으로 처리되므로, 한 번만 저장됩니다. 이를 통해 중복된 데이터를 저장하지 않게 하여, 메모리를 절약하고, 데이터 조회 성능을 높일 수 있습니다.

오늘의 기록은 내일의 보물