📋 개요
원티드 프리온보딩 세번째 날이다. NLG(Natural language generation) task에 대해 알아보았다. 아직 benchmark가 NLU보다 잘 형성되지 않은 분야이며, 연구가 활발히 진행되는 분야 중 하나이다. 오늘은 NLU의 sub task 중 하나인 Machine Translation에 대해 글을 써보고자 한다.
글의 순서는 다음과 같다.
- NLG란?
- Machine Translation
- 문제 정의
- 데이터셋 소개
- SOTA 모델 소개
- Reference
✍️ NLG란?
언어를 생성하는 건 정확히 무엇을 뜻할까?
언어의 방향성에 따라 축약과 보강, 그리고 재구성으로 나눌 수 있다.
- 축약(Text Abbreviation) → 문장의 핵심만
- Summarization
- Abstractive : 문서에 있는 단어로 요약
- Extractive : 문서에 없던 단어로 요약
- Application: 뉴스요약
- 현업에서 수요가 많은 서비스
- Question generation
- Application: onlline 학습 도구
- Distractor generation
- 오지선다에서 오답을 생성
- Application : 데이터 증강
- Summarization
- 보강(Text Expansion) → 부족한 정보를 추가
- Short text expansion
- 정보를 추가해 데이터 길이를 늘리기
- Application : 짧은 제목으로 내용 생성
- Topic to essay generation
- Application : “가족", “장난감", “크리스마스" → “케빈은 크리스마스에 혼자 집에서...”
- Short text expansion
- 재구성(Text Rewriting) → 기존 정보의 형태를 변형 / 기존 정보로 추론해서 답
- Style Transfer
- 긍정 ↔ 부정
- 아침에 샌드위치 먹었는데 맛있었어 → 아침에 샌드위치 먹었는데 맛없었어😑
- Application : 데이터 증강, 말투 변화(사투리 변형 등등)
- Dialogue Generation
- 페르소나를 가진 참여자의 대화를 생성
- Application : 챗봇
- Style Transfer
🤔 Machine Translation
Machine Translation은 내가 가질 직무와 직접적인 연관이 있을지 모호한 분야이지만, 외국어 전공자로서 항상 궁금했던 분야이기도하다. (학부 4년간 papago는 최대의 라이벌이자, 친구였다.🤔) 현재 Machine Translation의 주류 아키텍쳐는 무엇인지, SOTA모델은 무엇이 있는지 살펴보고자 한다.
문제 정의
Machine Translation(MT), 기계 번역은 인간의 개입 없이 한 언어를 다른 언어로 자동으로 변환하는 task를 의미한다.

MT에는 아래의 세가지 방법이 해당된다.
- Rule-based machine translation (RBMT)
- Statistical machine translation (SMT)
- Neural machine translation (NMT)
MT에 대한 정보는 이 링크를 참고하면 된다.
인공 신경망을 이용한 기계번역(NMT)이 현재 주류를 이루고 있다.
데이터셋 소개
소개할 데이터셋은 WMT 2014 dataset이다.
해당 데이터셋은 두쌍의 언어(독일어-영어, 프랑스어-영어, 러시아어-영어..)가 묶여있다. 아래는 그 중 '독일어-영어'로 묶인 데이터셋의 일부이다.
{ "de": "Wiederaufnahme der Sitzungsperiode", "en": "Resumption of the session" }
{ "de": "Ich bitte Sie, sich zu einer Schweigeminute zu erheben.", "en": "Please rise, then, for this minute' s silence." }
{ "de": "(Das Parlament erhebt sich zu einer Schweigeminute.)", "en": "(The House rose and observed a minute' s silence)" }같은 의미를 가진 두 언어가 한문장씩 묶여있다.
이를 MT모델에 적용시켜 독일어를 영어로 변환시키는 번역기를 학습시킬 수 있다.
SOTA 모델 소개
MT모델에 대해 서치한 결과 아래와 같은 리더보드를 보았다. 한가지 눈에 띄인 점은 SOTA 모델들도 언어의 쌍에 따라 다르다는 사실이다. 언어는 자국어와 외국어로 이분화할 수 있는 영역이 아니기 때문이라서 그런지 모델이 언어에 대한 영향을 많이 받는 것 같다.

특정 언어 번역을 위한 논문 역시 심심찮게 발견 할 수 있었다.
언어에 따라 MT의 방법을 달리하기도 하는데, papago의 경우에 타 언어들은 NMT 기법을 이용하였지만, 한국어-일본어 번역에 SMT 기법을 사용한 사례가 있었다고 한다. (현재는 어떤 방식을 사용하는지 모르겠지만!)
MT분야에서는 현재 Transformer나 그 일부를 응용한 모델들이 많이 생겨나고 있다.
따라서 Transformer 모델과 Machine Translation on WMT2014 English-German 데이터셋에 대한 SOTA 모델인 Transformer Cycle에 대해 간단하게 설명하고자 한다.
Transformer
Transformer 이전, seq2seq모델의 한계는 고정된 크기의 context vector(문맥 벡터)가 소스 문장의 모든 정보를 가지고 있어야 하므로 성능이 저하 된다는 것이다. 또한 sequence의 길이가 길수록 연산 시간이 오래 걸린다는 단점도 있었다.
Transformer에서는 그러한 한계를 타파하고자, Attention만으로 encoder와 decoder를 구현했다.
다음은 너무나도 유명한 그 논문, Attention Is All You Need에서 발췌한 이미지이다.
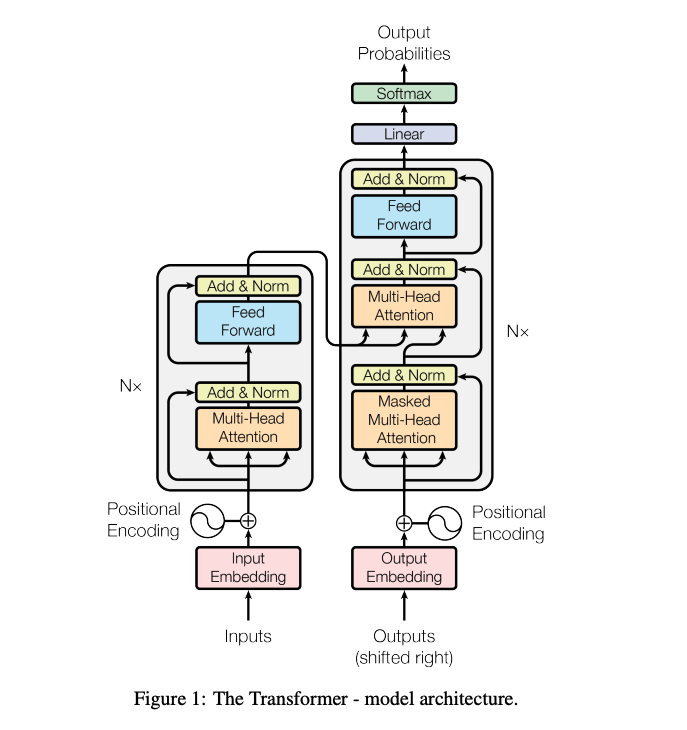
Transformer의 전체적인 구조를 나타내고 있는데, 주목할만한 점은 Positional Encoding과 3개의 Multi-Head Attention이다.
Transformer는 병렬화를 위해 모든 단어 벡터를 동시에 입력받는다. 컴퓨터는 어떤 단어가 어디에 위치하는지 알 수 없게 된다. 따라서 단어의 위치 정보를 제공하기 위해 벡터를 만들어 주는데, 그것이 바로 Positional Encoding이다.
Transformer의 주요 메커니즘인 Self-Attention은 문장 내부 요소의 관계를 잘 파악하기 위해 문장 자신에 대해 어텐션 메커니즘을 적용한다.
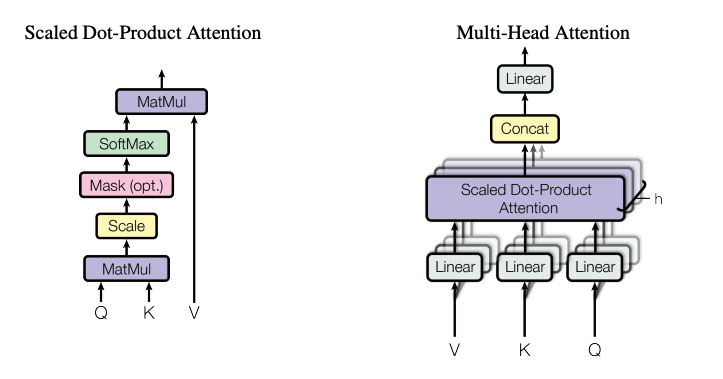
이 과정에서 Query, Key, Value 벡터를 만든다. 순서는 다음과 같다.
- 특정 단어의 쿼리(q) 벡터와 모든 단어의 키(k) 벡터를 내적한다. 내적을 통해 나오는 값이 Attention 스코어(Score)가 된다.
- 트랜스포머에서는 이 가중치를 q,k,v 벡터 차원 의 제곱근인 로 나누어준다. (계산값을 안정적으로 만들어주기 위한 계산 보정)
- Softmax를 취해준다. 쿼리에 해당하는 단어와 문장 내 다른 단어가 가지는 관계의 비율을 구할 수 있다.
- 밸류(v) 각 단어의 벡터를 곱해준 후 모두 더한다.
Transformer에서는 이 Attention을 여러개 만들어 다양한 특징에 대한 Attention값을 볼 수 있도록 한다. 이것이 바로 Multi-Head-Attention이다.
decoder는 Auto-Regressive(왼쪽 단어를 보고 오른쪽 단어를 예측)하게 단어를 생성한다. 따라서 예측을 하지 않은 단어에 대해 masking을 해줘야 한다. 이때 사용하는 것이 Masked Self-Attention이다.
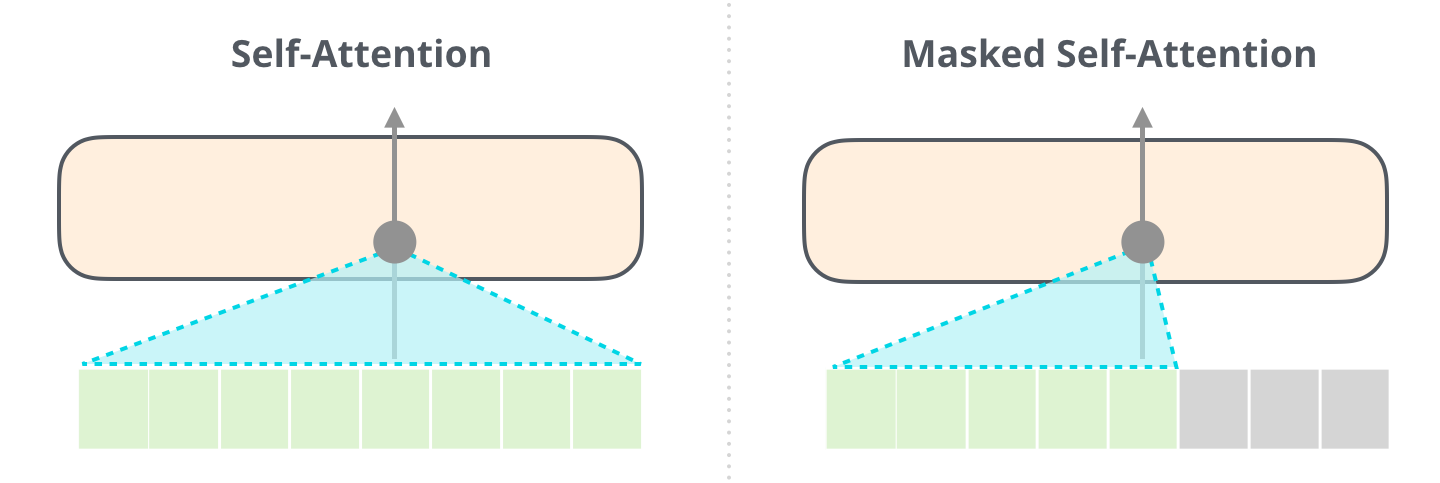
Masked Self-Attention에서는 Softmax를 취해주기 전, 가려주고자 하는 요소에만 에 해당하는 매우 작은 수를 더해준다. 이로써 Softmax를 취했을때 0이 나오게 되고 Value 계산에 반영되지 않는다.
논문 - Attention Is All You Need의 키워드는 다음과 같다.
- Transformer
- Attention / Self-Attention
- Encoder & Decoder
Transformer Cycle
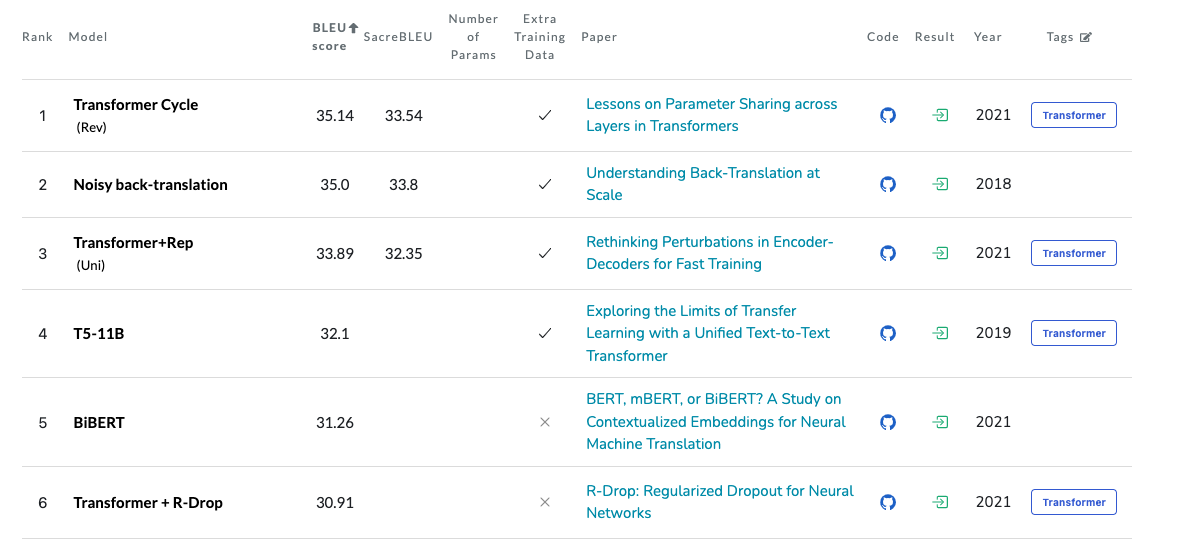
'Machine Translation on WMT2014 English-German' 데이터셋에 대해 가장 높은 BLEU Score를 달성한 모델이다. (35.14)
Abstract과 Introduction의 model figure만을 살펴보았는데, 대략적으로 말하자면, 기존의 Transformer 모델에 layer마다 parameter를 쉐어하는 방식을 취한걸로 보인다.
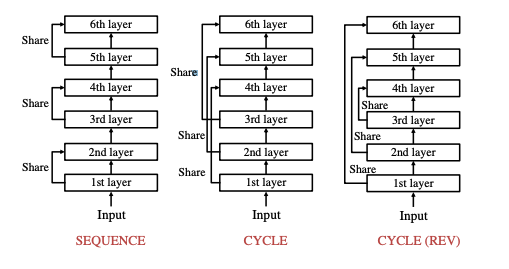
위 이미지에 보이는 것처럼 SEQUENCE, CYCLE, and CYCLE(REV) 세가지의 방식 parameter를 쉐어했다.
논문 - Lessons on Parameter Sharing across Layers in Transformers의 키워드는 다음과 같다.
- Transformer
- parameter sharing method
- SEQUENCE, CYCLE, and CYCLE(REV)
🌈 Reference

3개의 댓글

Transformer 설명에 이어서 활용한 machine translation SOTA 모델까지 잘 정리해주셔서 이해가 잘 됐어요!

rnasterpiece 너무 웃기네요 ㅋㅋㅋㅋㅋ transformer는 봐도 봐도 새로운 것 같아요.. 다른 시각에서 정리해주시니까 또 좋네요! 감사합니다
트랜스포머 자세히 설명해 주셔서 감사합니다!