📋 개요
원티드 프리온보딩 ML/DL코스의 첫번째 날이다.
시작하기앞서, 이번 강의에 참여한 목적에 대해 말하고자 한다.
1. 코드스테이츠에서 AI부트캠프를 마치고 확실한 목표를 정했다. NLP엔지니어가 되기로 한 것이다.
2. 위의 부트캠프에서는 팀과 협업할 기회가 적었고, 또한 NLP에 집중한 프로젝트를 할 기회가 적었다.
3. 2번의 아쉬움을 해소할 수 있으면서 현업 데이터를 다뤄볼 기회를 가진 코스는 무조건 참여하는게 좋다고 생각했다 !
4. 길다면 길고 짧다면 짧은 5주인것 같다. 평소에 느꼈던 부족한 부분을 채워나가고, 협업하는 팀원들도과 함께 좋은 성장을 이룰 수 있으면 좋겠다. ☺️
오늘 과제의 개요는 다음과 같다.
- NLP sub task 2가지 선택
- 문제 정의 (해결하고자 하는 task는 무엇인가?)
- task 해결을 위한 데이터 소개 / 데이터의 구조 설명
- SOTA 모델 소개 / 해당 모델 논문의 주요 keyword
✍️ NLP tasks
선택한 NLP task는 NER(Named Entity Recognition)과 Text Classification이다. 아직 모르는 것도 많고, 시간도 촉박하여 모델의 structure를 따져보기는 힘들다. 하지만 해당 task를 해결하기 위해 어떤 최신 모델이 있으며, 어떠한 데이터셋을 사용하는지 등을 알아보는 시간을 가질 것이다.
✔️ NER
NER은 한국어로 '개체명 인식'이라고도 하는 NLP task이다. 자연어 안에서 정보를 추출해내는 task중에 하나이며, 추출된 정보들은 NLP의 여러 분야에서 사용된다. 대표적으로 chatbot이 있다.
문제 정의
corpus 안에서 각 개체(Entity)가 어떠한 유형에 속하는지 인식하는 것이 이 task의 목적이다.
만약
'zhenxi는 어제 공차에 가서 블랙 밀크티를 마셨다.'
라는 문장이 있다면,
그 안에서 zhenxi(사람 이름), 어제(시간), 공차(장소), 블랙 밀크티(음식 이름)
등의 개체명을 가려낼 수 있다.
task 해결을 위한 데이터 소개
작성일 기준 paperswithcode에서 NER 부분 가장 상위에 랭킹된 모델이 사용한 데이터 셋을 소개하겠다.

해당 이미지는 huggingface에서 제공하는 CoNLL-2003 data set의 프리뷰이다.
각 열은 token과 해당 문장에 대한 고유 id, 품사 태그(pos_tags), 청크 태그(chunk_tags), 개체명 태그(ner_tags)로 구성된다.
각 태그는 정수로 맵핑되어 있으며, 어떠한 품사, 청크, 개체명이 어떤 숫자로 매핑되어 있는지는 위에 달아놓은 링크를 참고하면 된다.
한가지 예로
{
"chunk_tags": [11, 12, 12, 21, 13, 11, 11, 21, 13, 11, 12, 13, 11, 21, 22, 11, 12, 17, 11, 21, 17, 11, 12, 12, 21, 22, 22, 13, 11, 0],
"id": "0",
"ner_tags": [0, 3, 4, 0, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
"pos_tags": [12, 22, 22, 38, 15, 22, 28, 38, 15, 16, 21, 35, 24, 35, 37, 16, 21, 15, 24, 41, 15, 16, 21, 21, 20, 37, 40, 35, 21, 7],
"tokens": ["The", "European", "Commission", "said", "on", "Thursday", "it", "disagreed", "with", "German", "advice", "to", "consumers", "to", "shun", "British", "lamb", "until", "scientists", "determine", "whether", "mad", "cow", "disease", "can", "be", "transmitted", "to", "sheep", "."]
}해당 tokens 중에 European에 대해 살펴보면 다음과 같다.
- pos_tags : 22 : NNP(고유명사)
- ner_tags : 3 : B-ORG(ORG:Organization)
- chunk_tags : 12 : I-NP(NP:Noun Phrase)
(참고로 chunk는 구(Phrase)에 해당한다고 생각하면 쉽다.)
이처럼 태그를 달아놓은 토큰들을 학습하여 NER 작업을 할 수 있다.
추가로, 한국어로 된 dataset도 찾아보았다.
이 역시 hugging face에서 찾은 kor_ner dataset이다.
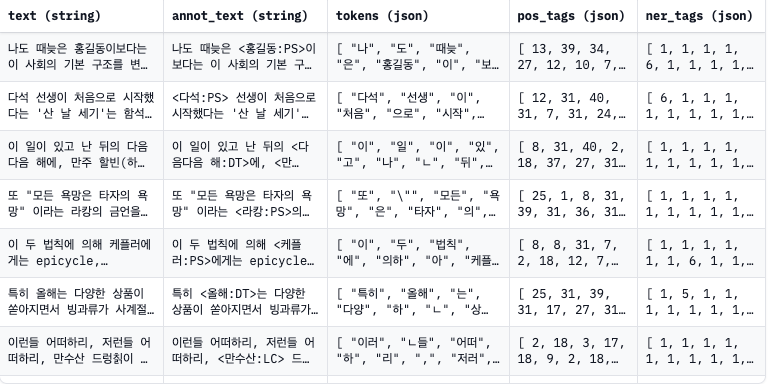
전체 text 문장과, annotated text가 추가된 것을 제외하면 위의 dataset과 비슷한 양상이다. 자세한 것은 링크를 참고하면 된다.
SOTA 모델 소개
ACE + document-context은 알리바바 그룹에서 발표한 논문 Automated Concatenation of Embeddings for Structured Prediction에서 제안한 모델이다.
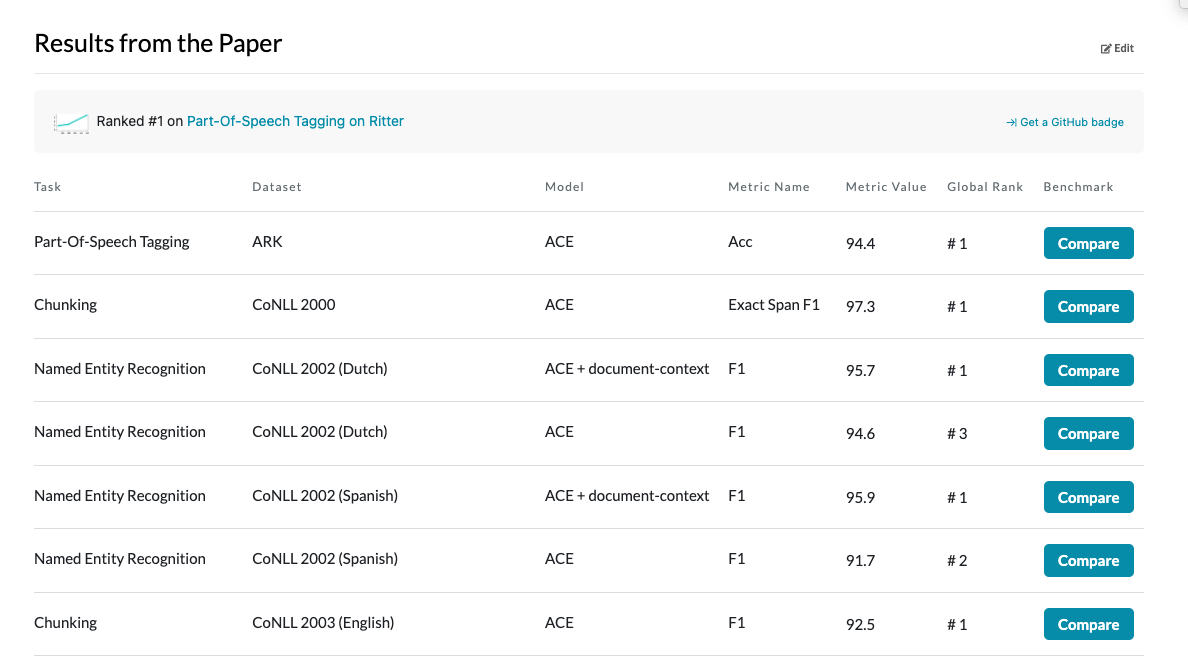
위 이미지에서 보는 바와 같이 NER이나, tagging, Chunking 등의 작업에서 극 상위권을 차지하고 있다.
논문에 작성된 주요 keyword는 다음과 같다.
- Automated Concatenation of Embeddings (ACE)
- neural architecture search (NAS)
- Transformer
- LSTM
- embedding concatenations
✔️ Text Classification
말그대로 text를 정해진 category에 분류하는 NLP task이다. NLP의 sebtask중 가장 큰 갈래라고도 생각하여 해당 task에 대해 알아보기로 하였다.
(classification 문제에 대해서는 정말 클래식한 모델을 주로 사용해온지라, 최신 딥러닝 모델이 뭐가 있는지 궁금하기도 했다.)
문제 정의
사실 위에서 설명한 것이 다이다. target이 되는 category는 선택한 문제와 dataset에 따라 달라진다.
예를 들어 메일이 스팸인지 스팸이 아닌지 분류하는 이진 분류 task가 있을 수 있고,
영화 줄거리를 보고 해당 영화가 어떠한 장르인지 분류하는 task가 있을 수 있다.
task 해결을 위한 데이터 소개
이 역시 작성일 기준 paperswithcode에서 NER 부분 가장 상위에 랭킹된 모델이 사용한 데이터 셋을 소개하겠다.
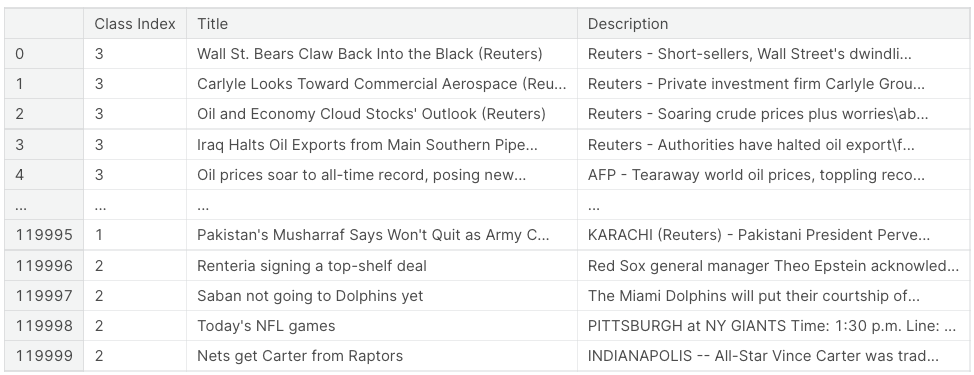
해당 이미지는 Kaggle에 등록된 AG News dataset의 프리뷰이다.
3개의 열로 구성되어 있고, 뉴스 기사에 대한 class index와 기사의 title, description으로 구성되어 있다.
class는 1:World, 2:Sports, 3:Business, 4: Sci/Tech 총 4개이다.
그럼 이 데이터로 어떻게 classification을 진행했는지 살펴보자.
SOTA 모델 소개

XLNet은 XLNet: Generalized Autoregressive Pretraining for Language Understanding에서 제안한 모델이다.


해당 모델은 이처럼 text classification 뿐만 아니라 다른 task에서도 매우 높은 성능을 보인다. XLNet은 BERT에서 사용되는 AE(auto-encoder)과 GPT에서 사용되는 AR(auto-regressive)의 장점만을 결합해 만든 모델로, 논문에 따르면 20개의 task(question answering, sentiment analysis 등)에 대해서 BERT보다 큰 폭으로 능가했다.
논문에 작성된 주요 keyword는 다음과 같다.
- AR(auto-regressive)
- AE(auto-encoder)
- BERT
- Transformer
- masking
🌈 Reference



해당 내용을 군더더기없이 깔끔히 작성해 주셔서 보기가 좋았습니다. XLNet 모델 잘 알아갑니다~!