어떤 DB를 선택할지 결정하기 위해서는 아래와 같은 사항들이 고려되어야 한다.
- DDL 작업의 블로킹
- DML 문의 성능
- 트랜잭션 처리의 격리 수준
- 데이터 형의 느슨함, 유형 변환
- ...
위 사항들에 대해 결정하기 위해서는 각 DB에 대해 Depth있는 이해가 필요하지만 아직 내가 그정도까지는 도달하지 못했다. 다만, 본 포스트에서는 PostgreSQL과 MySQL의 데이터 쓰기 방식의 차이에 대해서 공부 차원에서 간략히 짚어보려 한다.
(MySQL, PostgreSQL의 세부적인 차이에 대해서는 최하단 참고URL을 확인하면 도움이 될 것이다.)
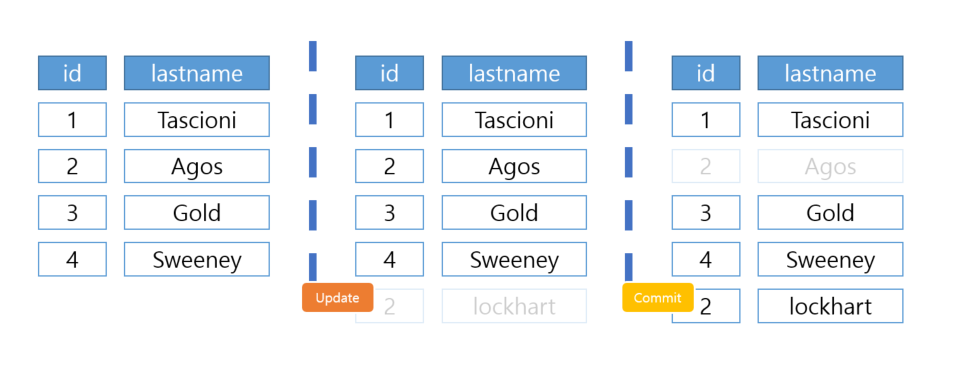
MGA - Multi Generation Architecture
MGA는 PostgreSQL에서 사용하는 방식이다.
어떤 데이터에 업데이트가 일어나면, 기존 데이터는 그대로 두고 새로운 데이터가 추가된다. 그리고 기존 데이터에 표시가 된다.
MGA 방식은 기존 데이터가 지워지지 않는다는 특징이 있다.
그래서 PostgreSQL은 주기적으로 VACUUM을 해줘야하며,
VACUUM을 하지 않을 경우 실제 데이터보다 데이터 용량이 훨씬 큰 것을 발견할 수 있다.
또한 업데이트가 발생한 데이터의 물리적 위치가 변경되므로, 업데이트시마다 인덱스 수정 작업이 항상 발생하여 성능 저하 요인이 된다.
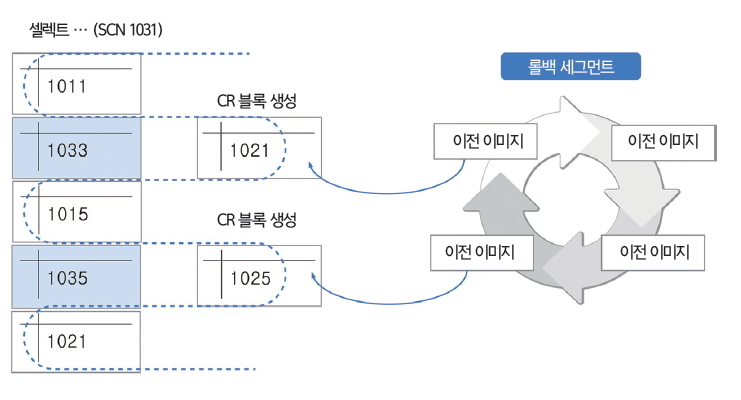
Rollback Segment (Undo Segment)
Rollback Segment는 Oracle, MySQL의 방식이다.
업데이트가 실행되면 기존 데이터 블록을 새로운 데이터로 변경하고 이전 데이터는 Rollback Segment에 보관된다.
데이터 변경 중, Select가 수행되면
Select쿼리는 SCN(System Commit Number)라는 고유한 번호를 가지고 데이터파일의 SCN을 비교한다.
이때, Select 쿼리의 SCN 번호보다 작은 데이터 파일의 SCN만 읽는다.
데이터가 변경되면 SCN이 변경되기 때문에 해당 데이터 파일은 변경 중 혹은 변경된 파일로 인식하고 Rollback Segment에서 이전 버전의 데이터 파일을 찾아 읽게 된다.
MGA와의 차이점은 업데이트 시 데이터의 물리적인 위치가 변경되지 않는다는 것이다.
즉, 업데이트 할때마다 인덱스 파일을 수정할 필요가 없고
Replication을 수행할 때 PK를 필수로 걸어 데이터를 판단할 필요가 없다.
물리적 위치를 사용하면 되기 때문이다.
(참고로, MySQL의 Replication 5.7버전부터는 물리적 복제가 Default로 변경되었다.)
첨언 - PostgreSQL vs MySQL
DB 선택시 자주 함께 고려되는 PostgreSQL과 MySQL의 경우, OLTP 관점에서 PostgreSQL이 더 우수하다.
그 이유는 MGA 방식을 기본으로한 Read Committed를 default로 동시성제어 성능 최적화를 지원하기 때문이다.
반면 OLAP 관점에서는 MySQL이 더 우수하다. Rollback Segment 방식을 기본으로하여 MySQL이 Select/Update문의 성능이 우수하기 때문이다.
(PostgreSQL에서 UPDATE문은 MGA방식으로 인해 실제로는 insert에 가까운 처리가 실행된다)
PostgreSQL은 다양한 기능을 제공하고 있다는 장점이 있고, MySQL은 임베디드 시스템에서 시작됐기 때문에 "복잡한 알고리즘은 가급적 지원하지 않는다"는 사상을 기반으로한 경량화된 Select/update 기능이 장점이다.
그에 따라 MySQL은 간단한 웹 서비스에 적합하며, PostgreSQL은 System Integrator에 더 적합하다.
다만, 실무에서 MySQL의 Select문이 PSQL에 비해 얼마나 빠른지, 어느 정도 복잡한 쿼리를 수행할 때 PSQL이 MySQL보다 우수한지 결정하는 것은 쉽지 않은 문제로 보인다.
개인적으로 MySQL은 복잡한 쿼리에 대한 성능 저하나, 과부하로 인한 문제를 배제할 수 없으며, Replication 문제와 라이센스 문제까지 있으므로 아무래도 PostgreSQL에 더욱 손이 가는 것 같다.
(PSQL은 MySQL에 Write Ahead Log 처리 기능을 제공)
사실 아직 개발하는 프로그램의 트래픽이 DB의 트랜잭션들을 세부적으로 컨트롤해줘야하는 수준도 아니고, 사용하는 쿼리도 간단하다.
하지만 개인적으로는 두 DB 중 더욱 복잡한 PSQL의 기능과 쿼리문들을 활용하여 최적화를 잘 해내는 레벨의 개발자를 지향하며 PSQL에 더 정이 가는 것 같다.
PostgreSQL과 MySQL의 차이점: https://yoonkh.github.io/code/2018/02/26/study_sql.html
https://valuefactory.tistory.com/m/497