-
정규 표현식(regexp)은 , 패턴(pattern) 과 선택적으로 사용할 수 있는 플래그(flag: 패턴 변경자) 로 구성되어 있습니다.
-
패턴(pattern) 은 시작 기호(패턴 구분자:
/), 정규표현식(패턴:정규표현식), 종료기호(패턴 구분자:/)) 로 구성되어 있습니다. -
ex)
/정규표현식/플래그
정규식 객체
정규식 객체를 만들 땐 두 가지 문법을 사용합니다.
1. 긴 문법
regexp = new RegExp("pattern", "flags");긴 문법을 사용하면 동적으로 사용할 수 있습니다.
아래의 예시를 보면 "어떤 태그를 찾고 싶나요?"를 보여주는 대화상자가 나타날 때 입력한 값이 tag에 위치하게 됩니다.
let tag = prompt("어떤 태그를 찾고 싶나요?", "h2");
let regexp = new RegExp(`<${tag}>`);
// 프롬프트에서 "h2"라고 대답한 경우, /<h2>/와 동일한 역할을 합니다.
// 프롬프트에서 "h1"라고 대답한 경우, /<h1>/와 동일한 역할을 합니다.1. 짧은 문법
슬래시(/) 는 자바스크립트에게 정규 표현식을 생성하고 있다는 것을 알려줍니다.
regexp = /pattern/; // 플래그가 없음
regexp = /pattern/gmi; // 플래그 g, m, i플래그
i
: 대소문자를 구별하지 않고 검색합니다.
g
: 문자열 내의 패턴과 일치하는 모든 것들을 검색합니다.
g 플래그가 없으면 패턴과 일치하는 첫 번째 결과만 반환됩니다.
m
: 다중 행 모드(multiline mode)이며 문자열 행이 바뀌더라도 계속 검색합니다.
s
: .이 개행 문자 \n도 포함하도록 ‘dotall’ 모드를 활성화합니다.
u
: 유니코드 전체를 지원합니다.
이 플래그를 사용하면 서로게이트 쌍(surrogate pair)을 올바르게 처리할 수 있습니다.
y
: 문자 내 특정 위치에서 검색을 진행하는 ‘sticky’ 모드를 활성화 시킵니다.
그룹과 범위
| (또는)
: 또는(or)의 의미
const target = 'A AA B BB Aa Bb';
const regExp = /A|B/g;
target.match(regExp);
// ["A", "A", "A", "B", "B", "B", "A", "B"]( )
: 그룹 지정
[ ] (문자 모음 내부 모두 또는 적용)
: 문자셋, 괄호안의 어떤 문자든 하나라도 만족하면
// []내의 문자는 or로 동작
const target = 'A AA B BB Aa Bb';
// "A"또는 "B"가 한 번 이상 반복되는 문자열
const regExp = /[AB]+/g;
target.match(regExp);
// ["A", "AA", "B", "BB", "A", "B"]- (문자 범위)
[] 내에 -를 사용하면 범위를 지정합니다.
const target = 'A AA BB ZZ Aa Bb';
// "A"또는 "B"가 한 번 이상 반복되는 문자열
const regExp = /[A-Z]+/g;
target.match(regExp);
// ["A", "AA", "BB", "ZZ", "A", "B"]ex) [a-zA-Z0-9] : a부터 z까지, A부터 Z까지, 0부터 9까지 하나라도 해당되면 찾기
const target = "AA BB 12,345"
// 0에서 9 또는 ','가 한 번 이상 반복되는 문자열
const regExp = /[0-9,]+/g;
target.match(regExp);
// ["12,345"]문자 모음 내부에서 정량자는 이스케이프가 필요 없습니다.
.은 이스케이프(\)가 필요하지만 ?는 문자 모음 내부에서 특수 의미를 잃기 때문에 이스케이프가(\) 필요하지 않습니다.
const target = "hello! are you okay? i am fine."
const regExp = /[\.?!]/gm;
target.match(regExp);
// ['!', '?', '.'][^ ] (문자 모음 안에 있는 문자를 제외한 값)
: 부정 문자셋, 괄호안의 ^뒤로 나오는 문자가 아닐때
(대괄호 안의 문자열을 제외한)
const target = "AA BB 12 Aa Bb";
// 숫자를 제외한 문자열이 한 번 이상을 반복하는 문자열 검색
const regExp = /[^0-9]+/g;
target.match(regExp)
// ["AA, BB", "Aa Bb"](?:문자열)
: 괄호 안의 문자열을 찾지만 기억(그룹 지정)하지는 않음
수량, 정량
문자 다음 정량자가 없다면 해당 문자가 정확하게 한번만 나타나야 한다는 것을 의미합니다.
? (0 또는 1번 반복)
: ? 앞선 패턴(문자 하나)이 하나가 있거나 없는것 모두 찾기.
{0,1}과 같음.
const target = 'color colour';
// u가 0에서 1번 반복되고 'r'로 이어지는 문자열ㄴ
const regExp = /colou?r/g;
target.match(regExp);
// ["color", "colour"]* (0 이상 반복)
: * 앞의 문자 하나가 있거나 없거나 많거나(여러개거나)
const target = 'kittens kittens! kittens!!!';
// u가 0에서 1번 반복되고 'r'로 이어지는 문자열ㄴ
const regExp = /kittens!*/g;
target.match(regExp);
// ["kittens", "kittens!", "kittens!!!"]+ (1 이상 반복)
: + 앞선 패턴(문자 하나)이 최소 한번 이상 반복되는 문자열
const target = 'A AA B BB Aa Bb AAA';
const regExp = /A+/g;
target.match(regExp);
// ["A", "AA", "A", "AAA"]{n} (정확한 반복 횟수)
: {n} 앞의 문자가 n번 반복한 문자열
정확하게 원하는 반복 수가 있을 경우 사용합니다.
const target = 'kittens kittens. kittens...';
// u가 0에서 1번 반복되고 'r'로 이어지는 문자열ㄴ
const regExp = /kittens\.{3}/g;
target.match(regExp);
// ["kittens..."]{min, max} (반복 범위)
: {} 앞의 문자가 최소 min번, 그리고 최대 max번
const target = 'A AA B BB Aa Bb AAA';
const regExp = /A{1,2}/g;
target.match(regExp);
// ["A", "AA", "A", "AA", "A"]// {n,}는 n번 이상
const target = 'A AA B BB Aa Bb AAA';
const regExp = /A{2,}/g;
target.match(regExp);
// ["AA", "AAA"]경계
\b (단어 경계)
앞으로 설명할 문자열은 [0-9A-Za-z_]을 뜻합니다.
띄어쓰기 특수기호는 문자열이 아닙니다.
\b패턴
: 문자열의 시작에 쓰이는 패턴만.
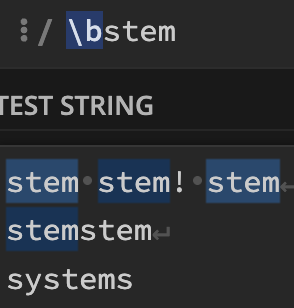
패턴\b
: 문자열의 끝에 쓰이는 패턴만.
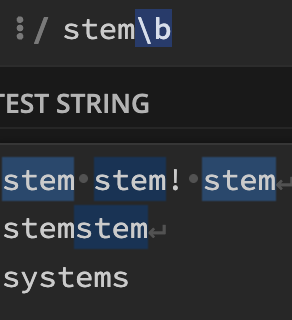
\b문자열\b
정확히 stem으로 시작해서 stem으로 끝나는 문자열만.
stemstem은 stemstem으로 시작해서 stemstem으로 끝남
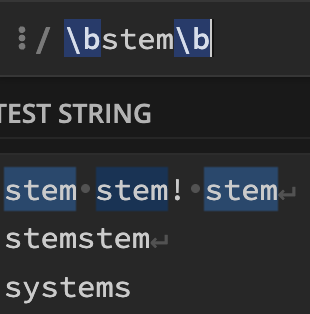
\B (단어 경계가 아님)
\B패턴
: 문자열의 시작에 쓰이지 않는 패턴만
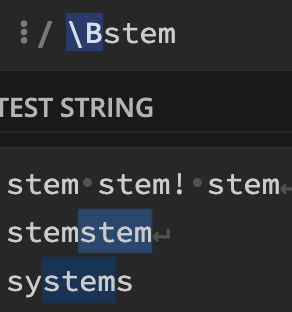
패턴\B
: 문자열의 끝에 쓰이지 않는 패턴만
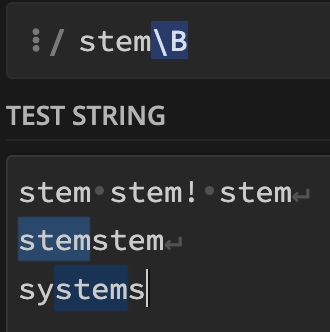
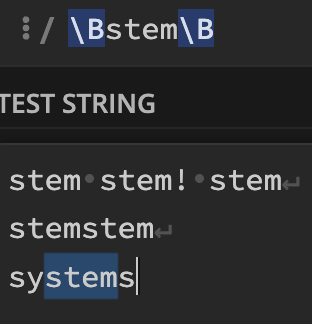
\B패턴\B
stem으로 시작하지 않고 stem으로 끝나지 않는 stem 문자열만.
^ (캐럿 기호: 시작 패턴 지정)
: 문장의 시작을 정합니다.
ex) ^문자열 : 문장의 앞(시작)에 쓰이는 문자열만
// "문자열이 시작하고 바로 Mary가 나타난다"라는 뜻
let str1 = "Mary had a little lamb";
alert( /^Mary/.test(str1) ); // trueconst target = 'Mary had a little lamb';
const newTarget = ' Mary had a little lamb';
const regExp = /^ +.*/g;
target.match(regExp);
// null
newTarget.match(regExp);
// [' Mary had a little lamb']$ (달러 기호)
: 문장의 끝
ex) 문자열$ : 문장의 뒤(끝)에 쓰이는 문자열만
// 문자열이 snow로 끝나는지 검사
let str1 = "it's fleece was white as snow";
alert( /snow$/.test(str1) ); // true^...$ (고정자)
두 앵커를 같이 쓰는 ^...$는 문자열이 패턴과 완전히 일치하는지 확인할 때 자주 사용
// ^...$을 사용하면 문자열 전체가 \d\d:\d\d 형식에 정확히 일치해야 함
let goodInput = "12:34";
let badInput = "12:345";
let regexp = /^\d\d:\d\d$/;
alert( regexp.test(goodInput) ); // true
alert( regexp.test(badInput) ); // false단, /정규표현식/m
: m(multiline) 을 입력하지 않는다면 전체 문장에만 기준이 됨
(전체 문장 내의 문장들에는 적용되지 않음)
const target = 'This is another sentence! Is this a sentence?';
const regExp = /[A-Z][^\.?!]+[\.?!]/gm;
// 고정자를 사용하면 라인 전체를 문자열로 보기 시작
const newRegExp = /^[A-Z][^\.?!]+[\.?!]$/gm;
target.match(regExp);
// ['This is another sentence!', 'Is this a sentence?']
target.match(newRegExp);
// nullconst target = 'akdfjleakdfjla;'
const regExp = /[^Ee]{6,}/gm;
// 고정자를 사용하여 문자열 전체를 매칭, 문자열 전체에 "E"또는 "e"가 포함되어 있으면 매치 x
const newRegExp = /^[^Ee]{6,}$/gm;
target.match(regExp);
// ['akdfjl', 'akdfjla;']
target.match(newRegExp);
// null앵커 ^와 $의 여러 행 모드, 'm' 플래그
여러 행 모드(multiline mode)는 ^와 $의 작동 방식에만 영향을 줍니다.
예시
캐럿 기호 ^가 기본적으로는 텍스트의 시작 위치에만 대응하기 때문에 m 플래그 없이 ^로 행 시작 검색하면 맨 앞 숫자만 검색됩니다.
let str = `1st place: Winnie
2nd place: Piglet
3rd place: Eeyore`;
alert( str.match(/^\d/g) ); // 1m 플래그를 사용하면 각 행이 시작하는 위치에 있는 숫자를 찾을 수 있습니다.
let str = `1st place: Winnie
2nd place: Piglet
3rd place: Eeyore`;
alert( str.match(/^\d/gm) ); // 1, 2, 3'행 끝’이라는 것은 '줄 바꿈 직전’을 의미합니다.
여러 행 모드에서 $을 사용한 검사는 줄 바꿈 문자 \n 바로 앞의 모든 위치와 일치합니다.
m 플래그가 없으면 달러 기호 $는 전체 텍스트의 끝에만 일치하므로 가장 뒤에 있는 마지막 숫자만 찾게 되지만 m 플래그를 사용하면 행 끝에 있는 숫자를 전부 찾을 수 있습니다.
let str = `Winnie: 1
Piglet: 2
Eeyore: 3`;
alert( str.match(/\d$/gm) ); // 1,2,3문자
\d (숫자)
: 숫자(digit) 0에서 9사이의 문자 전부 검색.
[0-9]와 같음.
\w (문자)
: 문자(word) 전부 검색.
라틴 문자나 숫자, 밑줄 _을 포함.
키릴 문자나 힌디 문자같은 비 라틴 문자는 포함되지 않음
[0-9A-Za-z_]와 같음
\s (공백)
: 공백(space), 탭(\t), 줄 바꿈(\n)을 비롯하여 아주 드물게 쓰이는 \v, \f, \r 을 포함하는 공백 기호 전부 검색.
[\r\n\t\v\f]와 같음.
\D (숫자 제외)
: 숫자(digit) 아닌 모든 것들.
\d와 일치하지 않는 일반 글자 등의 모든 문자
[^0-9]와 같음.
\W (문자 제외)
: 문자(word)가 아닌 모든 것들.
\w와 일치하지 않는 비 라틴 문자나 공백 등의 모든 문자.
[^0-9A-Za-z_]와 같음
\S (공백 제외)
: 공백(space) 제외한 모든 것들.
\s와 일치하지 않는 일반 글자 등의 모든 문자
[^\r\n\t\v\f]와 같음.
\특수문자 (백슬래시 이스케이프)
: 정규표현식에서 사용되고 있는 특수 문자를 찾고 싶을 때
\로 사용되는 빈칸 문자들
| 문자 | 의미 |
|---|---|
| \t | tab character |
| \n | newline |
| \r | carriage return |
| \f | form feed |
| \v | vertical tab |
- tab 과 b
const target = ' bee bright';
const regExp = /\tb/g;
target.match(regExp);
// ['\tb']- space 하나 이상으로 시작, newline을 제외한 모든문자 0번 이상
const target = 'peter piper picked a peck of pickled peppers';
const regExp = / +.*/g;
target.match(regExp);
[' piper picked a peck of pickled peppers']. (모든 문자)
: 줄 바꿈 문자(new line)를 제외한 모든 문자와 일치하는 특별한 문자 클래스입니다.(스페이스도 포함함)
예시
alert( "Z".match(/./) ); // Z
let regexp = /CS.4/;
alert( "CSS4".match(regexp) ); // CSS4
alert( "CS-4".match(regexp) ); // CS-4
alert( "CS 4".match(regexp) ); // CS 4 (공백도 문자예요.)점은 아무 문자에나 일치하지만 '문자의 부재’와 일치하지는 않습니다. 반드시 일치하는 문자가 있어야 합니다.
alert( "CS4".match(/CS.4/) );
// null, 점과 일치하는 문자가 없기 때문에 일치 결과가 없습니다.점은 줄 바꿈 문자 \n와는 일치하지 않습니다.
하지만 정규 표현식에 플래그 s를 사용했을 때 점.은 모든 문자와 일치합니다.
alert( "A\nB".match(/A.B/) ); // null (일치하지 않음)
alert( "A\nB".match(/A.B/s) ); // A\nB (일치)메서드
정규 표현식은 문자열 메서드와 조합하여 사용합니다.
str.match()
str에서 regexp와 일치하는 것들을 찾아냅니다.
str.match(regexp);플래그에 따른 결과 차이
1) 정규 표현식에 플래그 g가 붙으면 패턴과 일치하는 모든 것을 담은 배열을 반환합니다.
let str = "We will, we will rock you";
str.match(/we/gi)
// ['We', 'we'] (패턴과 일치하는 부분 문자열 두 개를 담은 배열)숫자를 모두 찾아 합쳐서 숫자만 남은 전화번호를 만드는 방법입니다.
let str = "+7(903)-123-45-67";
let regexp = /\d/g;
alert( str.match(regexp) ); // 일치하는 문자의 배열: 7,9,0,3,1,2,3,4,5,6,7
// 이 배열로 숫자만 있는 전화번호를 만듭시다.
alert( str.match(regexp).join('') );
// 79035419441\D로 숫자가 아닌 문자를 찾아 문자열에서 없애버려 숫자만 남은 전화번호를 만드는 방법입니다.
let str = "+7(903)-123-45-67";
alert( str.replace(/\D/g, "") );
// 790312345672) 플래그 g가 붙지 않은 경우엔 패턴에 맞는 첫 번째 부분 문자열만 담은 배열을 반환합니다.
단, 정규 표현식을 괄호로 둘러싼 경우엔 메서드 호출 시 반환되는 배열에 0 이외에도 다른 인덱스가 있을 수 있습니다.
let str = "We will, we will rock you";
let result = str.match(/we/i); // 플래그 g 없음
result // ['We', index: 0, input: 'We will, we will rock you', groups: undefined]
// We (패턴에 일치하는 첫 번째 부분 문자열)
// index: 0 (부분 문자열의 위치)
// input: We will, we will rock you (원본 문자열)첫 번째 숫자를 반환합니다.
let str = "+7(903)-123-45-67";
let regexp = /\d/;
alert( str.match(regexp) ); // 7CSS + 숫자와 일치하는 단어 하나를 반환합니다.
let str = "Is there CSS4?";
let regexp = /CSS\d/;
alert( str.match(regexp) );
// CSS4공백 + 단어 + 단어 + 단어 + 단어 + 숫자로 이루어진 단어를 반환합니다.
alert( "I love HTML5!".match(/\s\w\w\w\w\d/) ); // ' HTML5'3) 플래그 g의 유무와 상관없이 패턴과 일치하는 부분 문자열을 찾지 못한 경우엔 null이 반환됩니다.
let matches = "JavaScript".match(/HTML/);
// matches엔 null이 저장됨
if (!matches.length) { // TypeError: Cannot read property 'length' of null
alert("바로 윗줄에서 에러가 발생합니다.");
}str.match 호출 결과가 항상 배열이 되게 하려면 아래와 같은 방법을 사용하면 됩니다.
let matches = "JavaScript".match(/HTML/) || [];
if (!matches.length) {
alert("정규 표현식과 일치하는 부분 문자열이 없습니다."); // 이제 에러없이 잘 동작s
}str.replace()
str 내 부분 문자열 중 regexp에 일치하는 부분 문자열을 replacement로 교체할 수 있습니다.
str.replace(regexp, replacement)플래그에 따른 결과 차이
1) 플래그 g가 있으면 모든 부분 문자열이 교체됩니다.
// 플래그 g 있음
"We will, we will".replace(/we/ig, "I");
// I will, I will2) 플래그 g가 없으면 첫 번째 부분 문자열만 교체됩니다.
// 플래그 g 없음
"We will, we will".replace(/we/i, "I");
// I will, we willreplacement의 특수 대체 패턴
두 번째 인수 replacement는 문자열인데, 문자열 안에 다음과 같은 특수 문자를 넣어주면 독특한 방식으로 문자열을 교체할 수 있습니다.
| 특수 문자 | 교체 방식 |
|---|---|
| $& | 패턴과 일치하는 부분 문자열을 삽입 |
| $` | 일치하기 전에 문자열의 일부를 삽입 |
| $' | 일치하는 문자열의 뒤에 오는 문자열의 일부를 삽입 |
| $n | n이 1-2자리 숫자인 경우, n번째 캡처링 그룹의 내용을 삽입 |
$<name> | 지정된 "name"과 함께 캡처링 그룹의 내용을 삽입 |
| $$ | 문자 "$" 삽입 |
- $& 예시
패턴은 HTML이기 때문에 $&에 HTML이 삽입되어 I love HTML and JavaScript가 출력됩니다.
alert( "I love HTML".replace(/HTML/, "$& and JavaScript") );
// I love HTML and JavaScriptRegExp.prototype.test()
패턴과 일치하는 부분 문자열이 하나라도 있는 경우 true가, 그렇지 않으면 false가 반환됩니다.
regexp.test(str)예시
let str = "I love JavaScript";
let regexp = /LOVE/i;
alert( regexp.test(str) ); // true
예시
숫자 하나 이상
const regex = /\d+/gm
const search_target = 'Luke Skywarker 02-123-4567 luke@daum.net 다스베이더 070-9999-9999 darth_vader@gmail.com princess leia 010 2454 3457 leia@gmail.com'
search_target.match(regex)
// ['02', '123', '4567', '070', '9999', '9999', '010', '2454', '3457']자연수 찾기
const regex = /[1-9]\d*/g
const search_target = 'Luke Skywarker 02-123-4567 luke@daum.net 다스베이더 070-9999-9999 darth_vader@gmail.com princess leia 010 2454 3457 leia@gmail.com'
search_target.match(regex)
// [123, 4567, 70, 9999, 9999, 10, 2454, 3457]'-' 또는 공백을 포함하거나 포함하지 않는 전화번호
// 숫자가 하나 이상 + '-' 또는 공백이 있거나 없거나 + 숫자가 하나 이상 + '-' 또는 공백이 있거나 없거나 + 숫자가 하나 이상
const regex = /\d+[- ]?\d+[- ]?\d+/g
const search_target = 'Luke Skywarker 02-123-4567 luke@daum.net 다스베이더 070-9999-9999 darth_vader@gmail.com princess leia 010 2454 3457 leia@gmail.com'
search_target.match(regex)
// ['02-123-4567']연속된 한글
const regex = \[가-힣]+\
const search_target = 'Luke Skywarker 02-123-4567 luke@daum.net 다스베이더 070-9999-9999 darth_vader@gmail.com princess leia 010 2454 3457 leia@gmail.com'
search_target.match(regex)
// 다스베이더특정 단어로 시작하는지 검사
const url = 'https://example.com';
// 'htttp://' 또는 'https://'로 시작하는지 검사
/^https?:\/\//.test(url);
// true특정 단어로 끝나는지 검사
const fileName = 'index.html';
// 'html'로 끝나는지 검사
/html$/.test(fileName);
// true숫자로만 이루어진 문자열인지 검사
const target = '12345'
/^\d+$/.test(target);
// true하나 이상의 공백으로 시작하는지 검사
const target = ' Hi!';
// 하나 이상의 공백으로 시작하는지 검사
/^[\s]+/.test(target);
// true전화번호 검색
/\d{2,3}[- .]\d{3,4}[- .]\d{4}/gm
1. \d{2,3} 숫자가 최소 2개에서 최대 3개
2. [- .] 대시, 공백, 마침표 중 하나
3. \d{3,4} 숫자가 최소 3개에서 최대 4개
4. [- .] 대시, 공백, 마침표 중 하나
5. \d{4} 숫자가 4개 있는 문자 찾기
이메일 검색
/[a-zA-Z0-9._+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9]+/gm
1. [a-zA-Z0-9._+-]+ 알파벳, 숫자, 마침표, 아래대쉬, 더하기 기호, 대쉬가 하나 또는 많이 있음
2. @ 기호가 있음
3. [a-zA-Z0-9-]+ 알파벳, 숫자, 대쉬가 하나 또는 많이 있음
4. \. 마침표가 있음
5. [a-zA-Z0-9]+ 알파벳, 숫자가 하나 또는 많이 있음
유튜브 주소들 뒤의 아이디만 검색
ex) http://www.\[youtu.be/](http://youtu.be/)-ZClicWm0zM
ex) https://www.youtu.be/-ZClicWm0zM
ex) https://youtu.be/-ZClicWm0zM
ex) youtu.be/-ZClicWm0zM
/(?:https?:\/\/)?(?:www\.)?youtu.be\/(a-zA-Z0-9){11}/gm
(?:https?:\/\/)?http는 있고, s는 있거나 없으며 / 기호가 두번 나오는 문자열이 있거나 없으며 그룹을 지정하지 않음(?:www\.)?www. 가 있거나 없으며 그룹을 지정하지 않음youtu.be\/youtu.be/ 가 있음
4/(a-zA-Z0-9){11}알파벳이나 숫자 11개가 있음- 그룹은
(a-zA-Z0-9){11}만 지정됨
기타 사항
Can I Use에서 정규식 지원 여부의 최신 상황을 확인해보세요.
이 글을 작성하는 시점에 s 플래그는 Firefox, IE, Edge에서 아직 지원하지 않습니다.
대안으로 [\s\S]같은 정규 표현식을 사용해 '모든 문자’와 일치시킬 수 있습니다.
[\s\S] 는 '공백 문자 또는 공백 문자가 아닌 문자’라는 의미입니다.
alert( "A\nB".match(/A[\s\S]B/) ); // A\nB (일치)자료 출처:
모던 JavaScript 튜토리얼
드림코딩
모던 자바스크립트 Deep Dive
