Loss
Regression - mean_square_error
Binary classification - binary_crossentropy
Multiclass classification - categorical_crossentropy
Classification
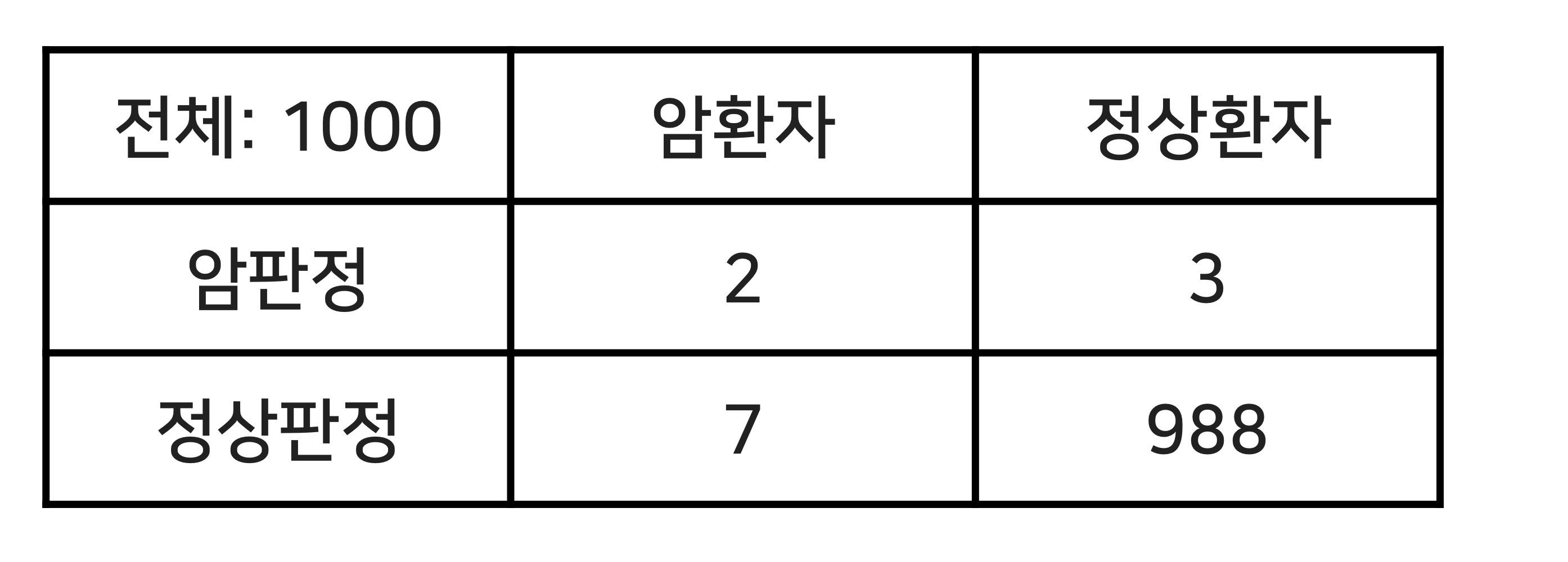
data가 imbalance하게 있어서 accuracy로 정확한 performance 측정이 어렵다.(ex.의료소송)
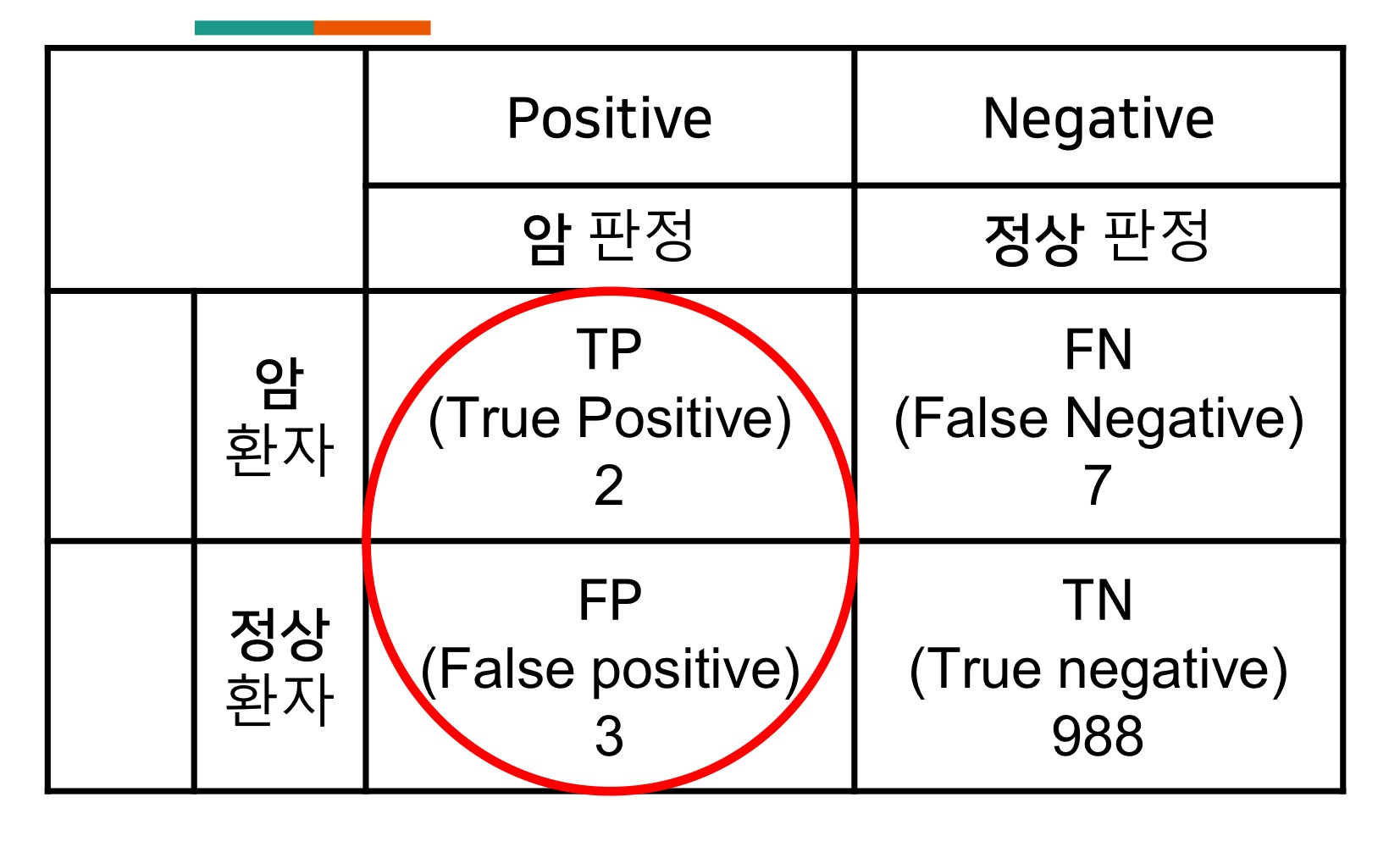
precision = 2/(2+3) = 40% ==> positive 판정 얼마나 정밀했나?
recall = 2/ (2+7) = 22% ==> positive 사건을 잘 재현 했나?
precision: positive 판정이 맞을 확률
- 암 판정 중 실제 암일 확률/ 고양이 판정 중 실제 고양이일 확률
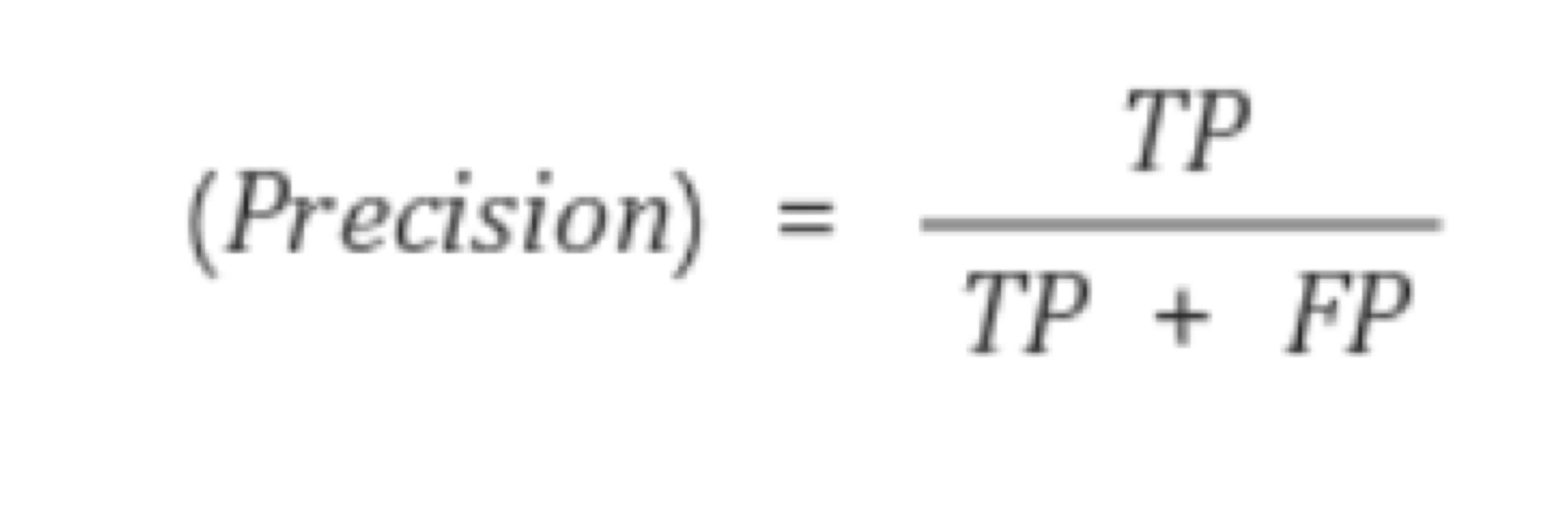
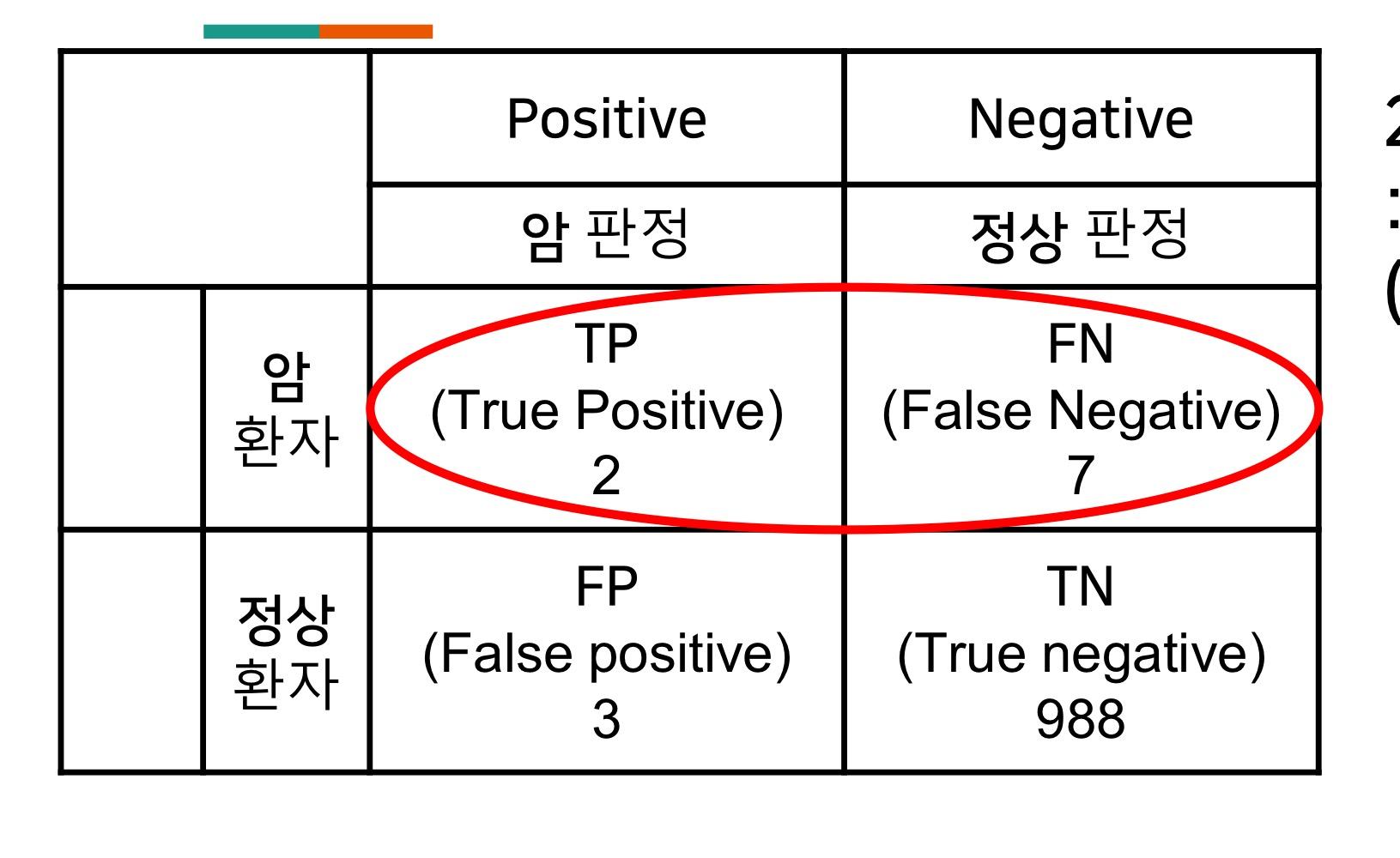
Recall: positive 사건이 잘 맞았는지
-암 환자 중 아믈 진단받을 확률/ 고양이 중 실제 고양이로 인식

- data imbalance& 잘못된 metric=> 오류 파악하지 못함
-> metirc 결정:
accuracy 사용// F1 score사용
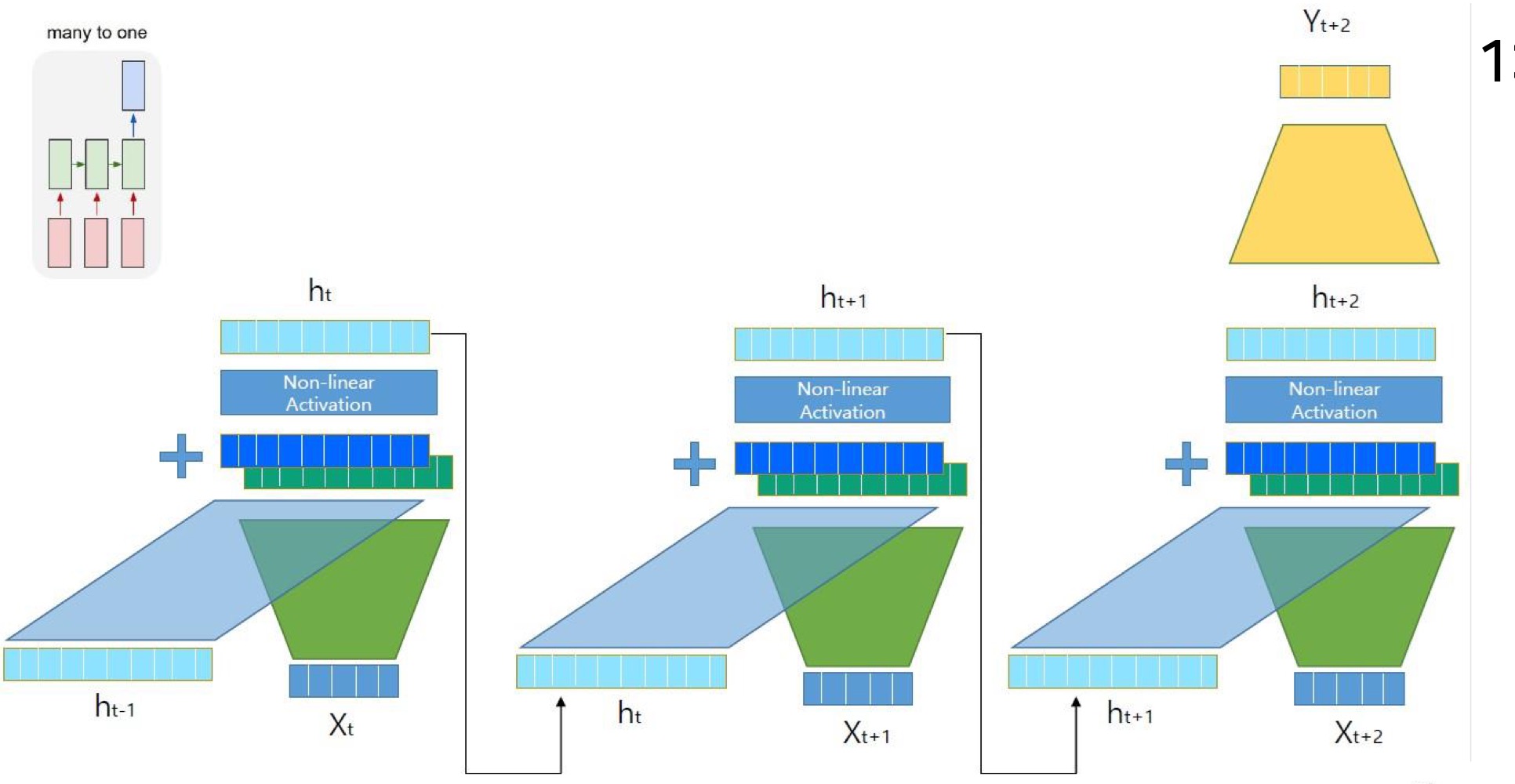
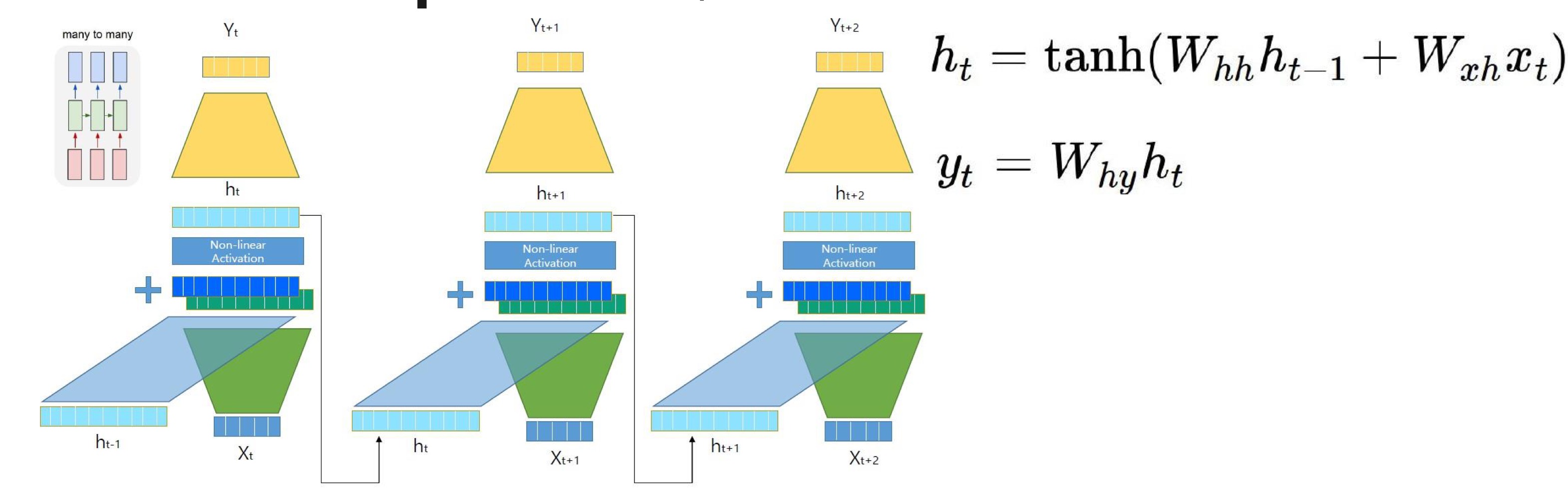
RNN
RNN의 종류
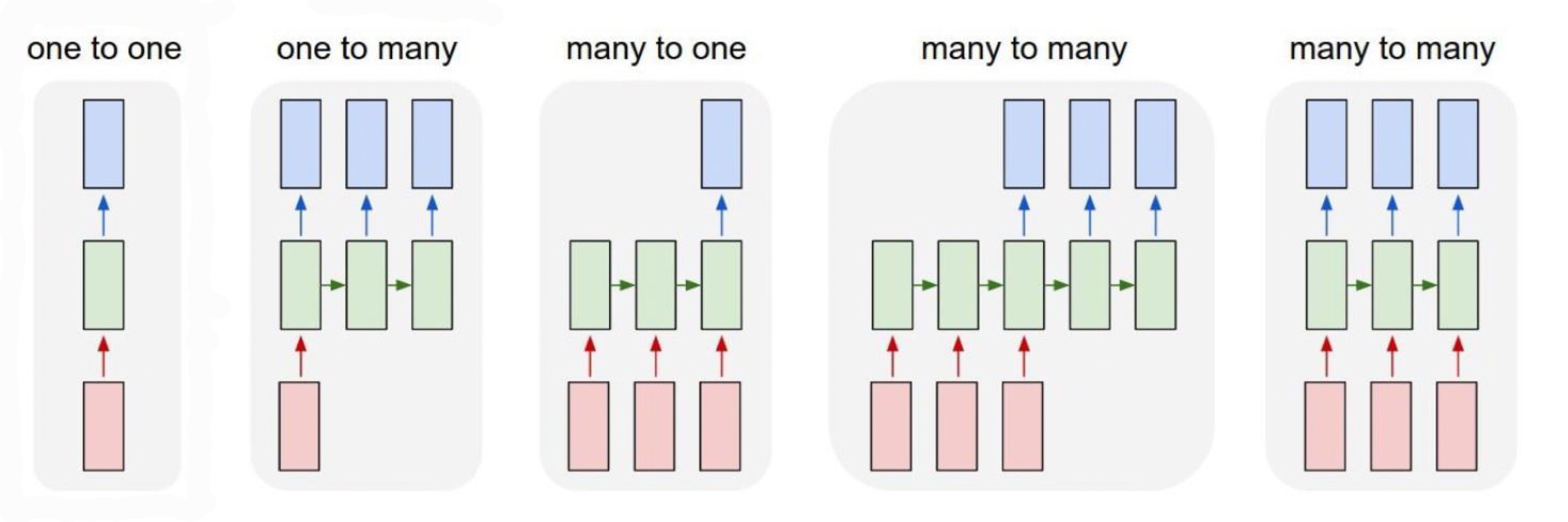
1.Fully-Connected Layer
one to one/ Dense Layer 모양
2.Image Captioning
one to many/ sequential하지 않은 data를 input으로 받고 sequential한 output을 출력
3.Sentiment Classification
many to one
4.Machine Translation
many to many/ 문장을 끝까지 앍은 시점부터 번역된 문장을 출력
5.Video Classification
many to many/ 과거부터 현재까지의 image를 통해 output 값을 출력
용어정리
shape(sample, time_step, input_dim)
sample: sample 개수(1회 train기준 = batch_size)
time_step= input_length: 어느 정도의 시간을 고려할 것인가
input_dim: input data의 feature수
RNN 1 layer -> Cell(RNN의 기본 구성 단위) -> Unit(Cell 내부의 hidden unit 개수)
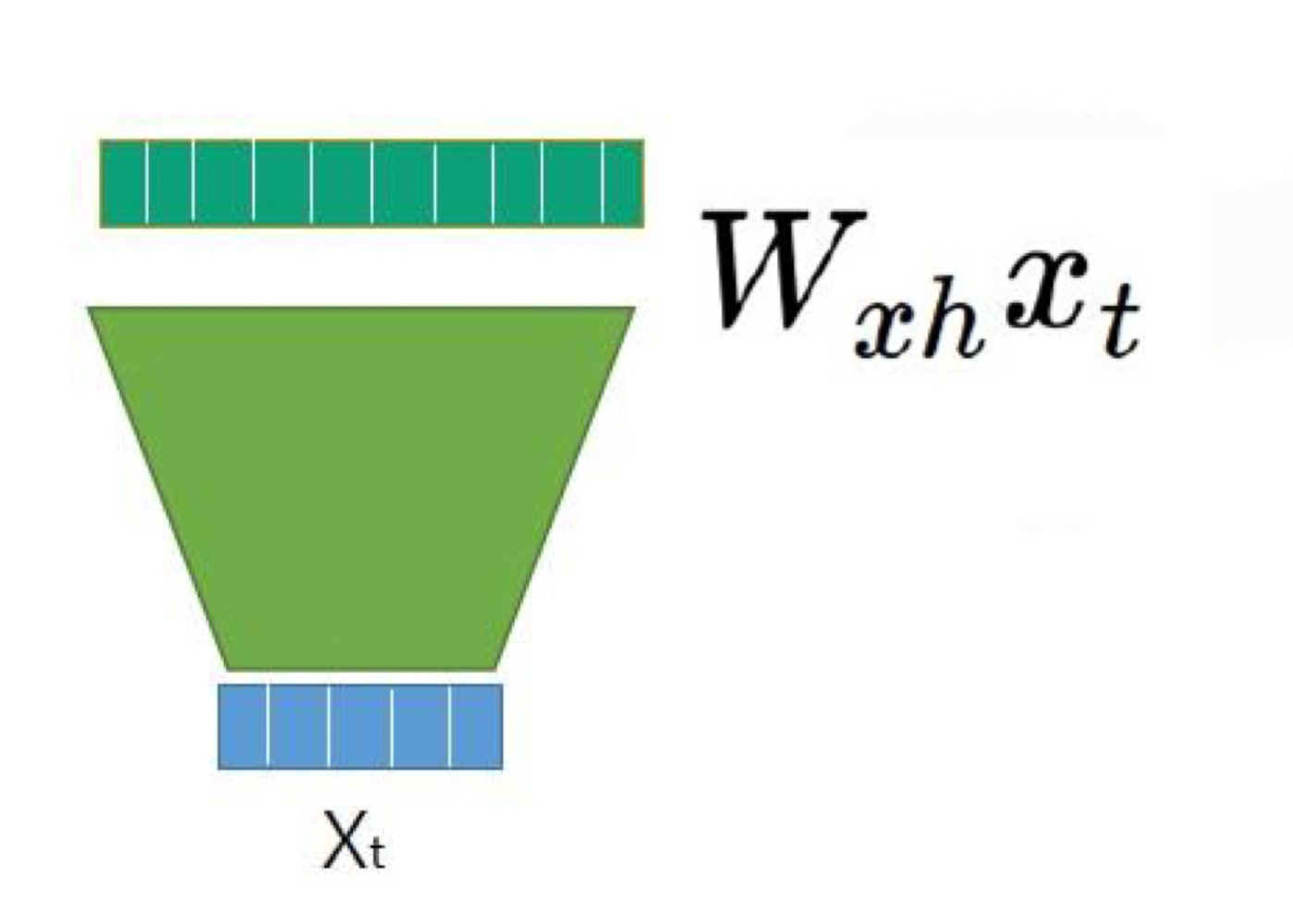
cell연산
1. input 연산(unit)
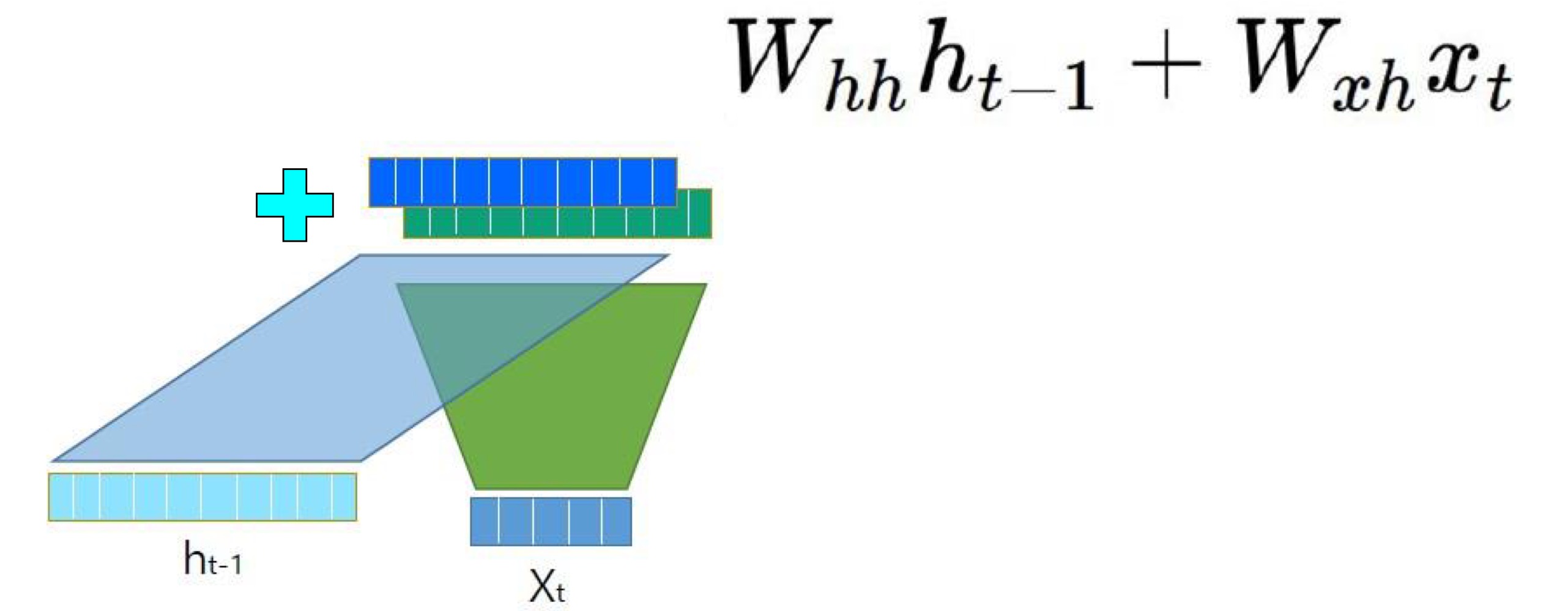
2.hidden_state 연산(이전 unit의 연산 결과를 받음)
3.activation function
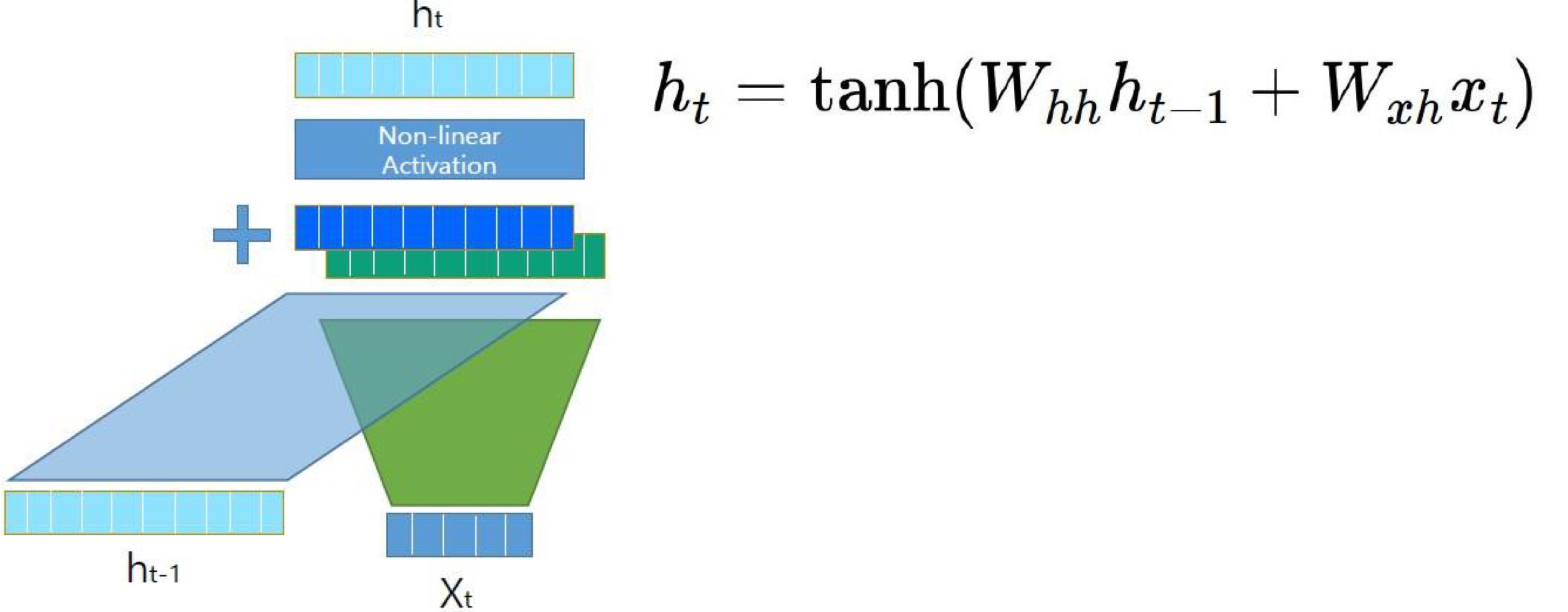
4.output연산
return_sequences = False
return_sequences = True
- Pandas 자료구조
Series: index와 value로 이루어진 1차원의 structured data형식 numpy 1d array와 유사, numpy와 달리 index가 있음
DataFrame: 여러 개의 Series로 이루어진 2차원의 structured data형식
DataFrame 각각의 column vector(열)를 하나의 Series라고 보면 된다
2d array와 비슷하지만 index와 column이 있음
2.파일 불러오기 및 저장하기
해당 위치의 csv 파일을 불러서 출력
filepath_or_buffer: 경로 설정
header: 열이 되는 행을 지정 (default = 0)
index_col: DataFrame의 행 index가 되는 column을 지정 (default = None)
절대경로/ 상대경로
'./'은 현재 해당 파일이 있는 폴더, '../'은 현재 해당 파일의 부모 폴더
csv 파일 저장하기 (pd.DataFrame.to_csv)
path_or_buf: 저장할 경로
index: index를 새롭게 추가할 것인가? (default: True) ==> 그래서 웬만하면 False로 하는 것이 낫다
- Indexing & Slicing
행
ndadrray 처럼 df[행, 열] 방식으로 indexing과 slicing이 불가능
loc (location의 약자) 혹은 iloc (integer location의 약자)를 사용해야 한다
loc - index가 정수형이 아닌 경우에 사용
df.loc를 쓰게 되면 ndarray indexing & slicing 사용하듯 쓸 수 있음
다른 점은 '[start:end]= start이상 end이하'가 된다
iloc - index가 정수형인 경우에 사용한다
열
DataFrame에서 하나의 column(열)은 series이다
column의 name으로 indexing & slicing 한다
- 행과 열 제거 및 결합
행과 열 제거 (drop)
행과 열 결합
열끼리의 결합 (join)
행끼리의 결합 (append)
- 누락, 중복 data 처리
-.info()
DataFrame에 대한 요약 정보가 담겨 있으며 한 번에 null의 개수를 확인할 수 있다
-.isna(), .notna()
누락 data를 찾는 직접적인 방법이며, 전체 DataFrame을 출력(요약적이지 않음)
isna(): 누락 data에서 True를 반환 (== isnull() )
누락 data 채워 넣기
-fillna
0으로 채워 넣기notna(): 누락 data에서 False를 반환 (== notnull() )
중복 data 확인 (duplicated)
중복 data 제거 (drop_duplicates)
- data의 분포 확인
-describe
describe는 각 columns에 대한 통계정보를 볼 수 있다
-unique
각 column이 어떤 값들을 갖는지 확인하고 싶다
-value_counts
각 column이 갖는 값들의 개수를 알고 싶을 때
