Reactor
타입
Publisher의 타입으로 0~N개의 타입을 제공한다.
-
Mono: 0건 또는 1건의 데이터를 emit
-
Flux: N건의 데이터를 emit
Non-Blocking 방식의 통신
Reactor는 요청 쓰레드가 Non-Blocking 통신을 완벽히 지원하여 서비스간의 통신이 잦은 MSA기반 애플리케이션에 적합
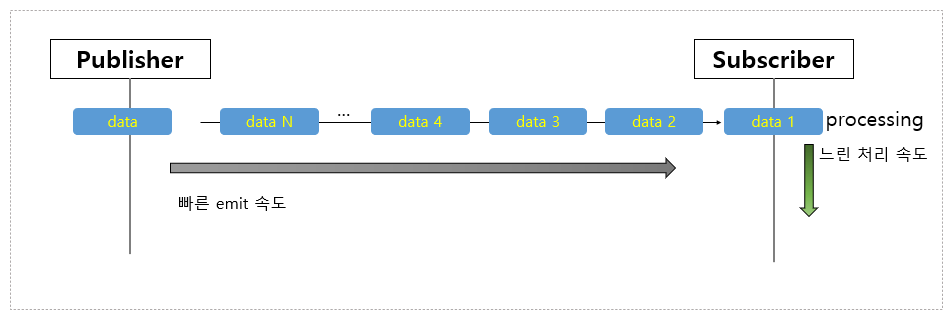
Backpressure
Subscriber의 처리 속도가 Publisher의 emit 속도를 따라갈 수 있도록 조절하는 전략
마블 다이어그램
다이어그램 상에서 시간의 흐름에 따라 변화하는 데이터의 흐름을 표현
API를 더 쉽게 이해할 수 있도록 도와준다.
왼쪽에서 오른쪽으로 시간이 흐르며, |는 정상 종료, X는 에러로 인한 비정상 종료를 의미한다.
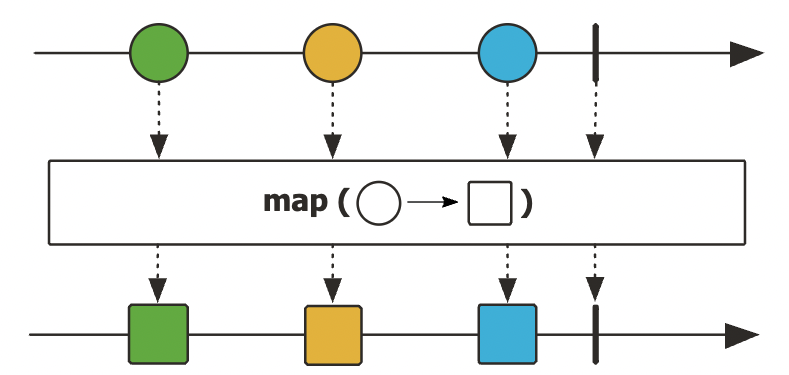
map 연산에서 동그라미 데이터가 네모 데이터로 바뀌는 것을 알려주는 마블 다이어그램
Scheduler
-
쓰레드를 관리하는 관리자의 역할
-
복잡한 멀티쓰레딩 프로세스를 단순화
-
subscribeOn(): 데이터 소스에서 데이터를 emit하는 원본 Publisher의 실행 스레드를 지정하는 역할
-
publishOn(): 전달 받은 데이터를 가공 처리하는 Operator 앞에 추가하여 실행 스레드를 별도로 추가하는 역할 -
publishOn()는 여러번 추가하였을 때, 별도의 스레드가 추가로 생성되지만subscribeOn()은 하나의 스레드만 추가된다.
Operators
비동기적인 데이터 스트림을 쉽게 다룰 수 있으며, 코드의 가독성과 유지보수성을 높일 수 있다.
생성자(creation)
Flux와 Mono를 생성하는 함수를 제공한다.
| 메서드명 | 설명 |
|---|---|
just() | 주어진 값 또는 생성하는 함수로부터 Flux, Mono를 생성 |
fromIterable() | Iterable 객체에서 Flux를 생성 |
range() | 지정된 범위에서 정수 값을 생성하여 Flux를 생성 |
interval() | 일정 시간 간격으로 Flux를 생성 |
empty() | 빈 Flux를 생성 |
never() | 아무것도 발생하지 않는 Flux를 생성 |
변환(transformation)
데이터 스트림을 변환하거나 조작하는 함수로 데이터의 형태나 내용을 변경하고 여러 개의 Flux를 합치거나 분리할 수 있음
| 메서드명 | 설명 |
|---|---|
map() | 데이터 스트림에서 각 데이터 항목을 변환 |
flatMap() | 데이터 스트림에서 각 데이터 항목을 Flux나 Mono로 변환 |
concatMap() | flatMap()과 유사하지만, 순서가 보장 |
groupBy() | 기준에 따라 데이터를 그룹화하여 Flux를 생성 |
window() | 일정한 크기의 데이터 스트림을 포함하는 Flux를 생성 |
필터링(filtering)
데이터 스트림에서 특정 조건을 만족하는 데이터만 선택하는 함수로 데이터의 흐름을 제어할 때 사용
| 메서드명 | 설명 |
|---|---|
filter() | 조건에 맞는 데이터만 포함 |
take() | 지정된 수의 데이터를 선택 |
skip() | 지정된 수의 데이터를 건너뜀 |
distinct() | 중복 데이터를 제거 |
elementAt() | 지정된 위치의 데이터만 선택 |
결합(combination)
두 개 이상의 데이터 스트림을 결합하는 함수로, 데이터의 순서와 방식을 제어할 때 사용
| 메서드명 | 설명 |
|---|---|
zip() | 두 개 이상의 Flux 또는 Mono에서 동일한 인덱스의 요소를 조합하여 새로운 단일 Flux를 생성 |
merge() | 두 개 이상의 Flux 또는 Mono에서 실시간으로 요소를 가져와 하나의 Flux를 생성 |
concat() | 두 개 이상의 Flux 또는 Mono를 연결하여 순차적인 하나의 Flux를 생성 |
