- 데이터베이스에서 인덱스는 대용량 데이터에서 빠른 검색을 가능하게 하는 중요한 기능. 책의 목차와 유사한 역할 수행
인덱스의 효율성
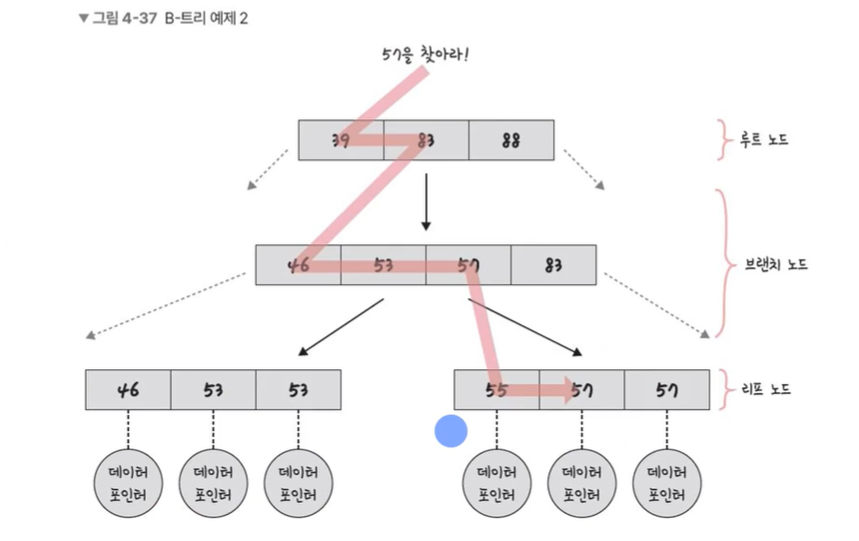
- 인덱스가 효율적인 이유는 균형 잡힌 B-Tree 구조이기 때문. 탐색, 삽입, 삭제 작업을 평균
O(logN)시간에 처리할 수 있어 매우 효율적. - 대수확장성의 특징으로 인해 노드의 수가 증가해도, 트리의 수는 비교적 적게 증가하므로 대량의 데이터를 효율적으로 관리 가능
B-Tree
- 루트 노드, 리프 노드, 브랜치 노드(중간 노드)로 구성되어 있으며 자식 노드가 2개 이상
- 전체 데이터를 순차적으로 찾을 때보다 , B-Tree를 이용하면 훨씬 더 빠르게 찾을 수 있음
인덱스 최적화 기법
- 비용 고려
- 인덱스는 탐색 비용을 감소시키지만, 유지 관리 비용이 발생함에 유의
- 테스팅 중요성
- 인덱스 최적화는 서비스의 특성에 따라 달라짐 -> 정기적 테스팅 필요
- 복합 인덱스 전략 - 아래의 순서대로 인덱스를 잡아야 한다
같음 > 정렬 > 다중(<,>) > 카디널리티(고유성)
Clustered vs Non-Clustered Index
Clustered
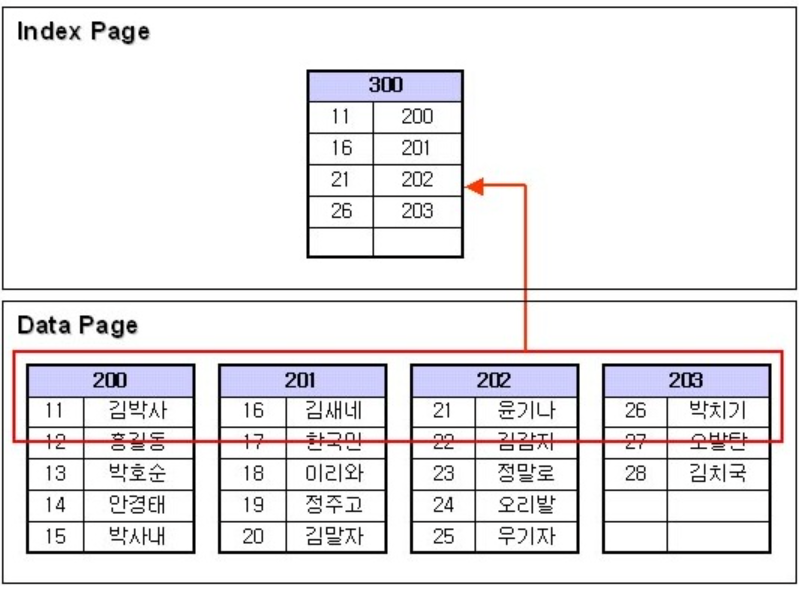
- 클러스터형 인덱스는 테이블의 데이터와 물리적 순서가 일치
- 데이터의 삽입, 삭제, 수정 시 전체 정렬이 필요해 비효율적
- primary key
Non-clustered
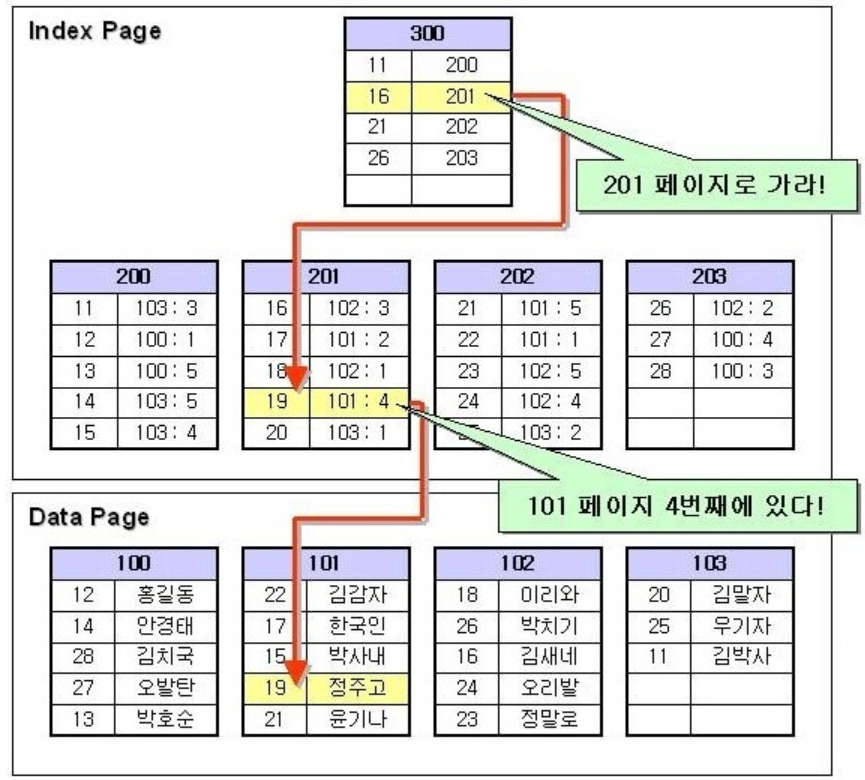
- 비 클러스터형 인덱스는 보조 인덱스
- 데이터의 물리적 순서와 인덱스가 독립적
- 삽입, 삭제, 수정은 빠르지만 탐색은 더 느림
- 인덱스 페이지 리프 노드에 실제 데이터가 있는 것이 아니라 데이터 페이지에 관한 포인터가 존재

의견 나누는 것을 좋아합니다 ლ(・ヮ・ლ)