클라우드 보안과 저장소 개념 정리
이전 포스팅에서는 클라우드 네트워크 아키텍처에 대해 공부했다.
이번 포스팅에서는 클라우드 보안(Security)과 저장소(Storage)에 대한 주요 개념과 역할을 정리해보자.
보안(Security)
클라우드 환경에서는 데이터를 보호하고, 애플리케이션과 사용자의 보안을 유지해야 한다.
이를 위해 네트워크, 애플리케이션, 데이터, 사용자 보안을 고려해야 한다.
1. 주요 보안 기술 및 서비스
- 네트워크 보안: Security Groups, Network ACLs, AWS WAF(Web Application Firewall)
- 데이터 보안: 암호화(AWS KMS, Azure Key Vault), 백업(AWS Backup, Google Backup & DR)
- 인증 및 권한 관리: IAM(Identity and Access Management), AWS Cognito
- 위협 탐지 및 대응: AWS GuardDuty, Azure Security Center
2. Security Group(SG) & Network ACL(NACL)
보안 그룹과 NACL은 네트워크 구성 시 다계층 보안 및 방화벽 설정을 위해 사용된다.
방화벽(Firewall)이란?
외부에서 들어오는 트래픽을 필터링하여 차단, 거부 또는 특정 요청만 허용하는 역할을 한다.
| 항목 | Security Group (SG) | Network ACL (NACL) |
|---|---|---|
| 적용 범위 | 인스턴스 레벨 | 서브넷 레벨 |
| 상태 저장 여부 | 상태 저장 (Stateful) | 무상태 (Stateless) |
| 규칙 유형 | Allow(허용)만 가능 | Allow(허용) 및 Deny(거부) 모두 가능 |
| 기본 정책 | Inbound: All Deny (모든 포트 차단) Outbound: All Allow (모든 포트 허용) | 사용자가 Inbound/Outbound 트래픽 규칙을 정의 |
2-1) Inbound & Outbound
- Inbound(인바운드): 외부 → 서버(내부)로 들어오는 트래픽
- Outbound(아웃바운드): 서버(내부) → 외부로 나가는 트래픽
- 규칙 설정: 트래픽 방향, 통신 프로토콜, 포트, IP 주소를 기준으로 보안 설정 가능
2-2) SG (Security Group)
- 인스턴스 레벨(EC2, ALB, RDS 등)에서 동작하는 가상 방화벽
- Inbound 및 Outbound 트래픽을 룰(Rule) 기반으로 선언
- 유형별로 공통 SG를 생성 후, 여러 인스턴스에 적용 가능
2-3) NACL (Network Access Control List)
- VPC 단위로 생성되며, 서브넷 레벨에서 적용
- Inbound 및 Outbound 트래픽을 룰(Rule) 기반으로 선언
- 서브넷에 여러 개의 NACL을 생성하고 공통 또는 개별 적용 가능
- Allow(허용) & Deny(거부) 모두 지정 가능
- 규칙 번호에 따라 순서대로 평가됨
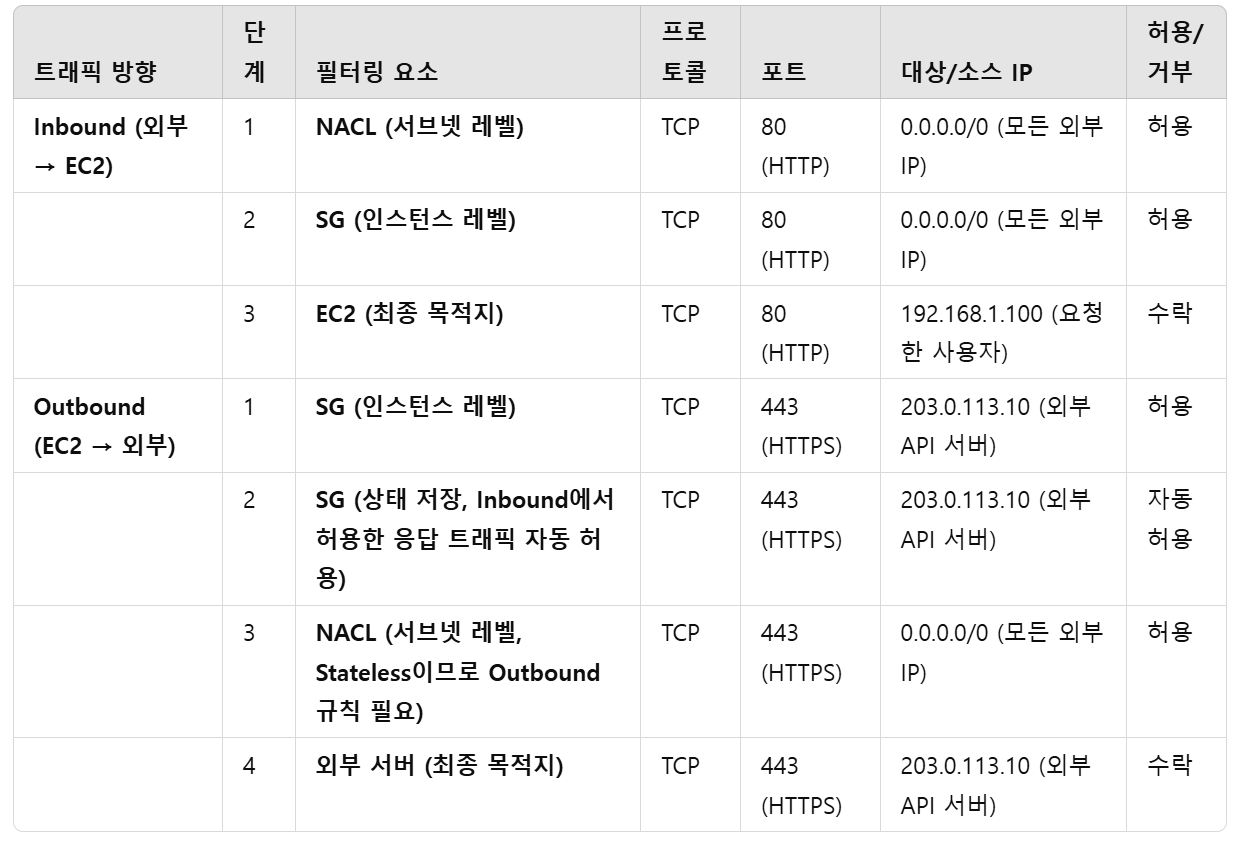
3. 트래픽 필터링 과정
3-1) Inbound 트래픽 (외부 → EC2)
- VPC 내부로 들어올 때 NACL 필터링
- NACL이 허용한 트래픽만 서브넷 인스턴스로 전달
- NACL이 허용한 트래픽 중 SG가 허용한 것만 인스턴스에 도달
3-2) Outbound 트래픽 (EC2 → 외부)
- EC2 인스턴스에서 외부로 나가는 트래픽을 SG가 필터링
- SG는 상태 저장(Stateful) 방식이므로, Inbound에서 허용한 응답 트래픽은 자동 허용
- NACL이 최종 필터링 후 Outbound 트래픽이 서브넷을 빠져나감
보안 흐름 이미지
스토리지(Storage)
클라우드는 다양한 유형의 스토리지 서비스를 제공하며, 필요에 따라 확장할 수 있다.
1. 주요 스토리지 기술 및 서비스
- 객체 스토리지 (Object Storage): AWS S3, Google Cloud Storage, Azure Blob Storage
- 블록 스토리지 (Block Storage): AWS EBS(Elastic Block Store), Google Persistent Disks
- 파일 스토리지 (File Storage): AWS EFS (Elastic File System), Google Filestore
- 데이터베이스 (Databases)
- 관계형 데이터베이스 (RDBMS): AWS RDS, Google Cloud SQL, Azure SQL Database
- NoSQL 데이터베이스: AWS DynamoDB, Google Firestore, MongoDB Atlas
- 데이터 웨어하우스: AWS Redshift, Google BigQuery
2. 데이터베이스 관리 및 트랜잭션 특성
데이터베이스는 다수의 사용자가 동시에 접근하더라도 데이터의 정확성과 일관성을 유지해야 한다.
이를 보장하기 위해 ACID 트랜잭션 특성을 따른다.
2-1) ACID (Atomicity, Consistency, Isolation, Durability)
- 원자성 (Atomicity): 트랜잭션이 완전히 실행되거나 전혀 실행되지 않아야 함 (오류 발생 시 Rollback)
- 일관성 (Consistency): 트랜잭션이 완료된 후 데이터는 항상 일관된 상태 유지
- 고립성 (Isolation): 동시 실행되는 트랜잭션 간 상호 간섭 방지
- 지속성 (Durability): 트랜잭션이 완료된 후, 장애가 발생해도 데이터가 유지됨
3. 모놀리식 vs. MSA 데이터베이스 구조
3-1) 모놀리식 아키텍처 (Monolithic Architecture)
- 모든 기능이 하나의 애플리케이션 내에서 동작
- 공통 데이터베이스를 사용하여 데이터 관리가 간편함
3-2) MSA (Microservices Architecture)
- 각 서비스가 독립적인 데이터베이스를 가질 수 있음
- MSA에서 개별 DB를 사용하는 이유
- 서비스 독립성 유지 → 스키마 변경이 다른 서비스에 영향 주지 않음
- 장애 격리 → 특정 서비스 장애 시, 전체 시스템에 영향 최소화
- 확장성 → 서비스별 읽기/쓰기 최적화 가능
- 기술 다양성 → 서비스 특성에 맞는 최적의 데이터 저장 기술 선택 가능
| 항목 | 모놀리식 아키텍처 | MSA 아키텍처 |
|---|---|---|
| 데이터베이스 구조 | 하나의 공통 DB 사용 | 서비스별 개별 DB 사용 |
| 서비스 독립성 | 스키마 변경 시 모든 서비스 영향 | 각 서비스가 개별 DB 관리 |
| 장애 격리 | 특정 서비스 장애가 전체에 영향 | 특정 서비스만 영향 |
| 확장성 | 전체 DB 확장 필요 | 서비스별 최적 확장 가능 |
| 기술 다양성 | 단일 기술 스택 사용 | 서비스별 최적 DB 선택 가능 |
4. MSA에서 데이터베이스 간 통신 (API 활용)
- MSA는 독립적으로 운영되지만, 서로 데이터를 주고받아야 하는 경우가 많음
- API 기반 데이터 연동 장점
- 각 서비스의 내부 구조를 몰라도 안전하게 데이터 공유 가능
- 보안 및 로깅 강화
