Transformer는 구글이 발표한 “Attention is All You Need” 논문에서 RNN을 사용하지 않고, Attention만으로 인코더-디코더 구조를 설계하여 문맥을 보다 효과적으로 학습하고, 긴 시퀀스를 처리할 수 있도록 만든 모델이다. 이 모델은 기존의 RNN 기반 seq2seq 모델보다 병렬 연산이 가능하고, 문맥 정보를 더 잘 유지할 수 있다는 점에서 혁신적이었다.
이러한 Transformer의 등장은 LLM(Large Language Model) 발전의 기초가 되었으며, 특히 인코더를 활용한 BERT(Bidirectional Encoder Representations from Transformers) 같은 문맥 이해 모델과, 디코더를 활용한 GPT(Generative Pre-trained Transformer) 같은 생성형 AI 모델이 등장하는 계기가 되었다.
Transformer 등장 전
기존의 seq2seq 모델은 RNN 기반의 Encoder - Decoder 구조로 이루어져 있었다.
Encoder와 Decoder에 대해 간략히 설명해 보자면,
우리의 뇌가 어떻게 번역을 하는지 원리는 모르지만,
한국어와 영어의 다른 언어 사이에 의미를 표현하는 어떤 중간 언어가 있을 것이고
그 언어가 Inter - lingua 라는 주장이 있다고 한다.
학습 모델에서는 Inter-lingua 가 context, meaning vector, semantic representation 등등으로 불린다고 한다.
Seq2Seq에는 번역이나 요약 등이 있는데, 번역을 예시로 Seq2Seq의 작동 원리를 간략히 나타내 보면 아래와 같다.
Input Data(한국어) → Encoder → Context(Inter-lingua) → Decoder → Output(영어)
이때 Input, Ouput Data들은 모두 자연어인데, 모델서 학습할 때 Encoder, Decoder, Context 모두 자연어가 아닌 행렬을 다룬다. 자연어를 행렬로 변환해줄 방법이 필요한데, 바로 이게 Embedding 이다.
- Encoder 는 행렬 문장을 입력받아 Context라는 행렬로 변환해주는 역할이고,
- Decoder는 Context 행렬을 대상의 언어 행렬로 변환해 주는 역할이다.
하지만 기존의 Word Embedding 방식에서는 다음과 같은 문제들이 있었다.
- 단어 간 관계를 정확히 표현하기 어려움
- 예를 들어, woman과 queen이 여자인 관계, go와 went가 같은 동사라는 관계를 정확히 표현하는 것이 어려웠다.
- 동음이의어, 오타, 새로운 단어 처리 문제
- 새로운 단어나 철자가 다른 단어를 제대로 인식하지 못하는 경우가 많았다.
- RNN의 순차적 입력 처리 방식
- 단어의 순서를 유지할 수는 있지만, 과거의 정보가 손실될 위험이 있었다. (특히 긴 문장에서 발생)
이러한 문제를 보완하기 위해 attention 메커니즘이 도입되었지만, 기존에는 attention이 RNN을 보조하는 역할에 머물렀다.
그런데, "굳이 RNN을 쓰지 말고, Attention만으로 인코더-디코더를 만들면 더 효과적이지 않을까?"라는 아이디어가 나오면서 Transformer가 등장하게 된 것이다.
Transformer 등장
Transformer의 핵심은 Multi-Head Attention으로 Encoder - Decoder를 아주 기가 막히게 잘한다는 것이다.
Transformer의 Encoder - Decoder도 위에서와 같은 작동 방식이다.
아래 그림에서와 같이 Input data가 들어가면 왼쪽 회색 상자인 Encoder를 지나가서 Add & Norm으로 나오게 되는데, 이게 Context이다.
이 Context가 다시 오른쪽 회색 상자인 Decoder로 들어가서 최종적으로 Output Probabilities라는 것을 만들게 된다.
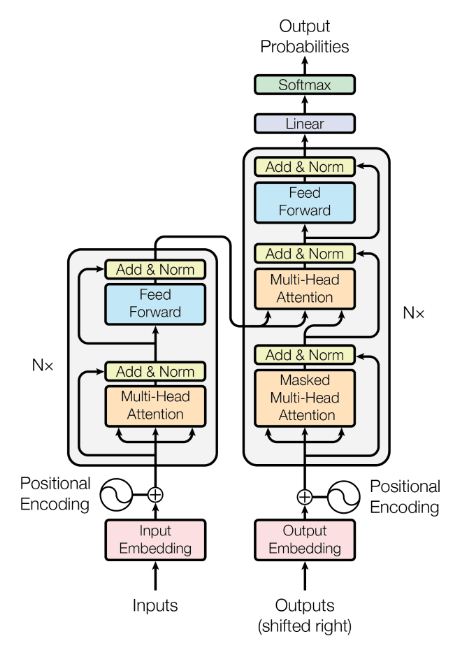
위에 그림을 보면 다음과 같은 궁금증이 생기게 된다.
- Decoder로 Context가 들어갈 때, 중간으로 들어가고 아래에 Output이 들어가서 Decoder 입력이 Context랑 Output 2개야.
- Output도 아니고 Output Probabilities는 뭐야?
- Multi-head attention은 뭐고 masked는 또 뭐야?
- 그 외에 Feed Forward랑 Add & Norm, Linear, Softmax는 뭐람… → 이건 나중에…
하나하나 살펴보자.
-
Decoder로 Context가 들어갈 때, 중간으로 들어가고 아래에 Output이 들어가서 Decoder 입력이 Context랑 Output 2개야.
사실 Transformer Decoder의 입력은 2가지 이다.
Encoder가 만든 Context와 Outputs
입력인데 Outputs? 이 Outputs은 바로 Decoder의 Output이다. (그림에선 Output Probabilities로 즉 디코더가 결정한 다음 단어라고 생각하면 됌.)
즉, 디코더의 결과가 다시 디코더의 입력으로 들어가는 것이다.
"나는 어제 학교에 갔다."라는 문장을 영어로 번역한다고 가정해보자.
- 먼저, Encoder가 해당 문장을 처리하여 Context라는 형태로 변환한다.
- Decoder는 단어를 예측하기 위해 두 가지 입력이 필요하다: Context와 이전에 생성된 출력(Outputs)이다.
- 하지만 처음에는 Decoder의 출력이 없기 때문에, 빈 문장(정확히는 시작 토큰)을 초기 Outputs으로 사용한다.
- Decoder는 이 Context와 빈 문장을 기반으로 첫 번째 단어를 예측한다. 예를 들어, 첫 번째 예측 결과가 "I"라고 해보자.
- 이후 같은 과정을 반복한다. 이번에는 Context는 그대로 유지되지만, 이전에 생성된 단어 "I"가 새로운 입력으로 들어간다. 이를 통해 Decoder는 다음 단어를 예측하며, 결과가 "went"라고 해보자.
- 같은 방식으로, 현재까지의 출력이 "I went"라면, 이를 입력으로 사용하여 다음 단어를 예측한다. 이번에는 "to"가 생성될 것이다.
- 이러한 과정을 계속 반복하여, 차례대로 "the", "school", "yesterday"가 생성될 때까지 진행된다. 이후, 모델이 종료 신호를 나타내는 특정 토큰(예:
<EOS>)을 예측하면 번역이 종료된다. - 최종적으로 Decoder가 생성한 단어들을 이어 붙이면, 완성된 번역 문장은 "I went to the school yesterday."가 된다.
이 과정에서 두 가지 중요한 개념이 등장한다.
- Decoder는 한 번에 한 단어(토큰)씩 예측한다. 즉, 한 문장을 한 번에 생성하는 것이 아니라, 마치 사람이 타이핑하듯이 단어를 하나씩 만들어간다. ChatGPT의 응답이 순차적으로 생성되는 것도 같은 원리다.
- Decoder가 생성한 결과가 다시 Decoder의 입력으로 사용된다. 이를 auto-regressive 방식이라고 하며, 이전 예측 결과를 기반으로 다음 단어를 생성하는 방식이다.
-
Output도 아니고 Output Probabilities는 뭐야?
Decoder는 최종적으로 Output Probabilities라는 것을 만든다. Output Probabilities는 입력에 가장 적합한 문장이 무엇일지 표현한 값이고, 이를 실제 자연어로 바꿔주는 부분은 그림에 생략되었다.
단어 그대로 확률이다! Ouput Probabilities에는 생성된 단어들의 확률값이 있어서 가장 높은 확률을 가진 단어가 Output이 되는거다.
그림처럼 Decoder는 블록처럼 생겼다. 즉, Encoder, Decoder는 각각 여러개의 Encoder Block, Decoder Block으로 쌓을 수 있다. 1번째 블록 출력이 2번째 블록의 이벽이 되는거다.
딥러닝 모델이 인공신경망 여러개 레이어 한 것처럼 여러 블록을 쌓을 수 있는데, 이 또한 딥러닝처럼 모델이 커질수록 모델의 표현력이 좋아지고 성능이 좋아질 수 있지만, 무작정 쌓는다고 좋아지는 것도 아니다.
-
Multi-Head Attention은 뭐야? Masked Multi-Head Attention은 뭐고??
Attetion → Self-Attention → Multi-Head Attention, Masked 순으로 알면 된다.
Attention은 RNN 기반의 Seq2Seq에서 사용된 주요 개념이다.
Seq2Seq 작동 원리를 다시 상기해보면, Input Data → Encoder → Context → Decoder → Output 이다.
Context로 문장을 변환할 때, 문장에서 집중해서 봐야 할 단어들을 알려주면 더 예측이 쉬워지지 않을까? 하는 원리가 바로 Attention 이다.Attention이 입력 문장의 어느 부분을 집중해야 하는지 알려주는 정보라면, Transformer는 비슷하지만 살짝 다른 Self-Attention을 사용한다.
Self-Attention은 Attention의 대상이 다른 문장이 아닌 자기 자신이여서 문장 내에서 각 단어가 다른 단어들과의 관계를 학습할 수 있도록 하는 메커니즘이다.
예를 들어, "It is on the table." 같은 문장에서 it이 정확히 무엇(table)을 가리키는지 판단할 수 있도록 한다.
그리고 Transformer는 이러한 Self-Attention을 병렬로 여러 개 두어 학습하는
Multi-Head Attention 구조를 가지고 있다. attention 값 행렬을 attention head라 부른다.여기서 Multi-Head Attention이 중요한 이유는 다음과 같다.
- 여러 개의 attention head를 사용하면, 각 head가 서로 다른 부분에 집중할 수 있음
- 덕분에 단어 간 다양한 관계를 포착할 수 있어 문맥 표현력이 향상됨
예를 들어 “Which do you like better, coffee or tea?"라는 문장을 보면,

위처럼 여러 개의 attention head가 병렬로 작동하면서 서로 다른 관계를 학습한다.
덕분에 Transformer는 입력 시퀀스를 더 풍부하게 표현할 수 있고, 긴 문맥도 보다 효과적으로 이해할 수 있게 되었다.
Masked Multi-Head Attention은 무엇이고, 왜 필요할까?
Masked Multi-Head Attention은 Transformer의 Decoder에서 사용되는 Self-Attention 기법으로, 미래 단어를 보지 못하도록 제한하는 Masking이 적용된 Multi-Head Attention이다.
다음 단어를 예측할 때, 정답 데이터의 미래 정보를 미리 알지 못하도록(과적합, 일관된 생성 확률 방지) 만들기 위해 사용된다.
더 자세히 설명해보자면, Transformer 전 Seq2Seq 학습 방식과 Transformer의 학습 방식을 비교해보면 된다.
Transformer 이전의 번역 모델(Seq2Seq)은 RNN이나 LSTM을 사용했으며, 입력 데이터를 순차적으로 처리했다.
기존 RNN 방식
"I"를 보고"나는"예측- "went"
까지 보고"갔다"` 예측 "to"까지 보고"에"예측"school"까지 보고"학교"예측
순차적으로 한 단어씩 계산해야 함 (병렬 처리 불가능, 속도 저하)
반면, Transformer 방식
"I went to school"을 한 번에 입력받고 모든 단어의 Attention Score를 동시에 계산- 각 단어가 어떤 다른 단어를 참고해야 하는지 한 번에 계산
- 모든 단어의 출력을 동시에 얻어냄
한 번의 연산으로 모든 단어를 예측할 수 있음 (병렬 처리 가능, 학습 속도 향상)
위와 같이 Transformer는 병렬 연산이 가능해서 훈련(Training)할 때 한번에 전체 문장을 입력 받아 모든 단어에 대한 예측을 동시에 수행한다.
훈련할 때 Decoder는 두 개의 입력을 받는다.
- Decoder Input (입력):
<sos> I went to school - Decoder Target (정답):
I went to school <eos>
(※ <sos> or <bos>는 시작 토큰, <eos>는 문장 끝을 나타내는 토큰)
하지만 이 경우, "went"를 예측할 때 "to school"을 이미 알고 있다면 너무 쉬운 문제가 된다.
미래 단어를 참조하면 모델이 실제 번역 과정과 다르게 동작할 가능성이 높아진다.
이를 방지하기 위해 Masked Multi-Head Attention을 적용하여, 미래 단어를 가리는 과정을 추가한다.
Decoder의 Self-Attention에서 미래 단어를 보지 못하도록 마스킹을 적용하면 다음과 같은 Attention이 형성된다.
| 현재 예측하는 단어 | 볼 수 있는 단어 (Masking 적용) |
|---|---|
| I | <sos> |
| went | <sos>, I |
| to | <sos>, I, went |
| school | <sos>, I, went, to |
즉, 각 단어는 자신 이전의 단어까지만 보도록 Masking이 적용된다.
결과적으로 Decoder가 미리 정답을 훔쳐보지 않도록 학습을 진행할 수 있다.
실제 번역하는 추론(Inference) 단계에서는 Decoder가 단어를 하나씩 생성하면서, 이전 단어들을 기반으로 다음 단어를 예측한다.
이때는 Masking이 필요하지 않다. 왜냐하면, Decoder는 어차피 이전 단어까지만 입력으로 받고, 미래 단어를 모르는 상태에서 예측을 수행하기 때문이다.
Inference 과정
- 처음에는
<sos>와 Encoder의 Context를 보고"I"를 생성. "I"를 Decoder에 다시 입력하고,"I"와 Context를 보고"went"를 생성."I went"를 Decoder에 다시 입력하고"I went"와 Context를 보고"to"를 생성."I went to"를 Decoder에 다시 입력하고"I went to"와 Context를 보고"school"을 생성.
이 과정에서는 Masking을 별도로 적용할 필요가 없다.
왜냐하면 Decoder는 Auto-regressive)방식으로 단어를 하나씩 생성하므로, 미래 단어를 참조할 가능성이 없기 때문이다.
이러한 혁신 덕분에 Transformer 기반 모델들이 빠르게 발전하게 되었고, LLM의 핵심 기술이 되었다.
Transformer 등장 후
Transformer의 인코더 구조를 활용하여 발전한 대표적인 모델이 BERT다.
BERT는 양방향(Bidirectional) 학습을 사용하여 문맥을 더 깊이 이해할 수 있는 모델이다.
예를 들어 문장에서 빈칸을 채우는 Masked Language Model(MLM) 방식으로 훈련되면서, 문장의 앞뒤 관계를 모두 고려할 수 있다.
반면, Transformer의 디코더를 활용하여 발전한 것이 GPT 같은 생성형 AI 모델이다.
GPT는 순차적(Auto-Regressive) 방식으로 다음 단어를 예측하는 구조이며, 문장을 생성하는 데 최적화되어 있다.
생성형 AI의 한계
GPT와 같은 생성형 AI의 특징은, 출력 과정에서 softmax를 거쳐 확률이 가장 높은 단어를 생성한다는 점이다.
이 때문에 "확률적으로 가장 가능성이 높은 단어를 예측하는 것"이지, 사실(Fact)을 기반으로 하는 것은 아니다.
이러한 특성 때문에 생성 모델이 “확률론적 앵무새(Stochastic Parrot)”라고 불리기도 한다.
또한, GPT는 학습된 데이터에 없는 질문을 받으면 가장 높은 확률의 답변을 생성하기 때문에, 사실과 다른 정보를 만들어내는 문제가 발생한다. 이를 할루시네이션(Hallucination)이라고 부른다.
이를 해결하기 위해 연구자들은 다양한 접근 방식을 시도하고 있다.
- Retrieval-Augmented Generation (RAG) 기법
- 외부 데이터베이스에서 검색한 정보를 바탕으로 답변을 생성하는 방식
- 검색 기반 LLM(Retrieval-based LLM)과 결합하면 더 정확한 정보를 제공할 수 있음
- Vector Database (벡터DB) 활용
- 특정한 정보를 임베딩 벡터로 저장해 놓고, 필요할 때 검색하여 활용
- 기존 LLM보다 최신 정보를 반영할 수 있어 할루시네이션을 줄이는 데 도움을 줌
이처럼 LLM이 발전하면서 단순한 텍스트 생성뿐만 아니라 검색 기능을 결합한 모델, 나아가 멀티모달 AI (텍스트+이미지+음성)를 처리하는 모델까지 연구가 활발히 진행되고 있다.
출처 및 참조
https://wikidocs.net/31379
https://www.blossominkyung.com/deeplearning/transformer-mha
아래 링크를 많이 참조했습니다. 아래 포스팅을 읽어보길 추천합니다!
https://jins-sw.tistory.com/entry/Large-Language-Model-2-LLM%EC%9D%84-%EA%B0%80%EB%8A%A5%EC%BC%80%ED%95%9C-%EC%82%BC%EB%B0%95%EC%9E%90
