💡 Most Common Word
작년에 알고리즘을 공부했을 때 기억나는 문제였다. 그 때도 애를 먹어서 쉽지 않은 문제라고 생각하고 있었다.

◽ 문제
주어진 문자열 paragraph에서 가장 많이 나온 단어를 찾는다.
이 때 banned라는 문자 배열이 주어지는데 banned에 있는 단어는 제외하고 가장 많이 나온 단어를 찾아 반환하는 문제이다.
이 때 최소한 한 단어는 ban 당하지 않으며 빈도가 동일한 것 없이 가장 많이 나온 단어는 단 하나라는 조건이 있다.
또 주어진 paragraph는 대소문자를 구분하지 않으며(case-insensitive), 결과는 소문자로만 반환되어야 한다.
-
금지된 단어 제외한 가장 흔하게 등장하는 단어를 출력.
-
대소문자 구분하지 않는다.
-
구두점(마침표,쉼표 등) 는 무시
◽ 풀이
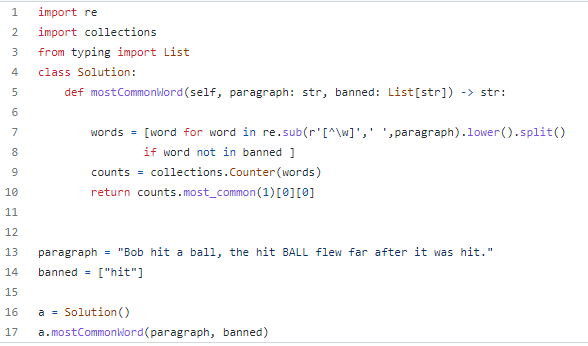
처음에는 for문이나 sorted 즉 반복문과 조건문 활용해서 문제를 풀었지만 조금 더 간단하게 구현할 수 있는 counter 모듈을 사용하였다.
7,8번째 줄에서 정규표현식 re.sub()를 이용해서 특수문자를 제거하고, lower()함수를 이용해서 소문자로 통일, 공백으로 분리하고 난 다음에 banned의 단어가 아니면 해당 단어들을 list로 만든다.
Collections에 있는 Counter()함수를 이용해서 7,8작업에서 전처리 한 words를 counts 변수에 저장한다.
💡 배운 점
◽ re.sub()
re.sub(정규 표현식, 대상 문자열, 치환 문자)
- 정규 표현식 : 검색 패턴을 지정
- 대상 문자열 : 검색 대상이 되는 문자열
- 치환 문자 : 변경하고 싶은 문자
처음에 문제를 보고 생각이 났던 아이디어 중 하나가 lower()함수 사용해서 소문자로 바꿔주고 특수문자를 제거하면 되겠다는 아이디어가 있었다.
그러나 정확한 정규 표현식의 활용이 생각이 나지 않았고 미숙하기 때문에 응용을 하지못했다.
◽ Collections 모듈
Collections 모듈은 파이썬에 기본적으로 내장되어있는 내장함수이다.
처음 아이디어인 반복문 for문을 이용해서 문자의 개수를 구하려고 했지만 Collections의 Counter()함수를 사용하면 보다 편리하고 간결하다.
◾ Counter()
collections.Counter(a) : a에서 요소들의 개수를 세어, 딕셔너리 형태로 반환한다. {문자 : 개수} 형태
또한 counter()함수를 이용해서 얻은 값은 값들끼리 연산이 가능하다. 단 [+ , - , &(교집합), |(합집합)]
◾ most_common()
collections.Counter(a).most_common(n) : a의 요소를 세어, 최빈값 n개를 반환한다. (리스트에 담긴 튜플형태로)
가장 높은 빈도(frequency)로 등장하는 값 (value)를 구한다.
