💡re 모듈
정규표현 처리를 하기 위해 표준 라이브러리인 re 모듈을 사용한다. 정규표현 패턴를 이용한 문자열의 추출이나, 치환, 분할 등이 가능하다.
◽ 왜 정규 표현식을 쓸까?
- 파이썬에서는 문자열에서도 기본적으로 특정 문자 또는 문자열이 존재하는지나 어느 위치에 있는지와 같은 기능을 제공합니다.
◽ re 함수
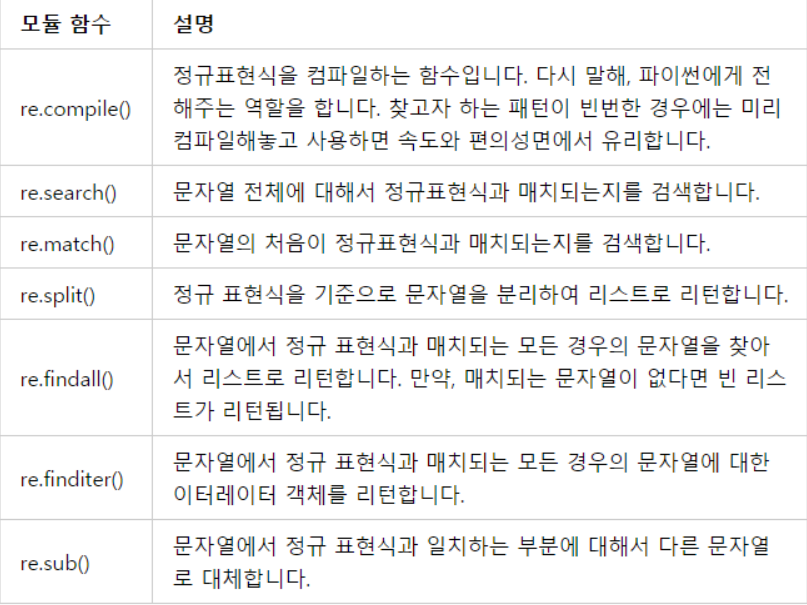
| re 함수 | 설명 | 사용 예 |
| re.compile(pattern, flags=0) | 정규식 객체로 compile함 정규식 객체는 match()와 search()에 사용 |
prog = re.compile(pattern) result = prog.match(string) 아래 코드와 동일 result = re.match(pattern, string) |
| re.search(pattern, string, flags=0) | string을 스캔하여 정규식 pattern이 일치하는 첫번째 위치를 찾고, 객체를 반환 일치하는 결과가 없으면 None으로 반환 |
|
| re.match(pattern, string, flags=0) | string이 시작 부분에서 0개 이상의 문자가 pattern과 일치하면, 일치 객체를 반환 | |
| re.fullmatch(pattern, string, flags=0) | '전체' string이 정규식 pattern과 일치하면 객체를 반환 | |
| re.split(pattern, string, maxsplit=0, flags=0) | string을 pattern으로 분리 | re.split('[a-f]+', '0a3B9', flags=re.IGNORECASE) → ['0', '3', '9'] |
| re.findall(pattern, string, flags=0) | string에서 겹치지 않는 pattern의 모든 일치를 문자열 리스트로 반환 | |
| re.finditer(pattern, string, flags=0) | string에서 겹치지 않는 RE pattern의 모든 일치를 일치 객체를 산출하는 iterator로 반환합니다 | |
| re.sub(pattern, repl, string, count=0, flags=0) | string에서 겹치지 않는 pattern의 가장 왼쪽 일치를 repl로 치환하여 얻은 문자열을 반환 | re.sub('[^A-Za-z0-9]', '', ‘(Hello123)’) → Hello123 (문자, 숫자가 아닌 부분을 ''로 대체) |
| re.subn(pattern, repl, string, count=0, flags=0) | re.sub() 동일하지만, (new_string, number of_subs_made)형태로 반환 | |
| re.escape(pattern) | pattern에서 특수 문자를 이스케이프 처리 | re.escape('http://www.python.org') → http://www\.python\.org |
| re.purge() | 정규식 cache를 삭제 |
◽ 정규 표현식 (Regular Expression)
| 정규 표현식 | 축약 표현 | 의미 |
| [0-9] | \d | 숫자를 찾음 |
| [^0-9] | \D | ^는 not을 의미. 즉 not [0-9] 이며, 숫자가 아닌 것을 찾음 |
| [ \t\n\r\f\v] | \s | 제어 문자(개행 문자, 탭 문자, 스페이스) 문자인 것을 찾음 |
| [^ \t\n\r\f\v] | \S | 제어 문자가 '아닌' 경우 |
| [A-Za-z0-9] | \w | 문자, 숫자를 찾음 |
| [^A-Za-z0-9] | \W | 문자, 숫자가 '아닌' 것을 찾음 |
| dot | . | 개행 문자를 제외한 문자를 찾음. [^\n\r]과 동일한 의미 |
| [ABC] | 특정 문자(ABC)를 찾음 | |
| 반복 ? | ? | 앞 문자가 0번 또는 1번 표시되는 패턴 |
| 반복 * | * | 앞 문자가 0번 또는 그 이상 반복되는 패턴 |
| 반복 + | + | 앞 문자가 1번 또는 그 이상 반복되는 패턴 |
| 반복 $ | $ | 문자열의 끝이나 문자열 끝의 개행 문자 바로 직전과 일치하고, MULTILINE 모드에서는 개행 문자 앞에서도 일치 |
| \ | \ | 특수 문자를 이스케이프 하거나 ('*', '?' 등의 문자를 일치시킬 수 있도록 합니다), 특수 시퀀스를 알림 |
| {n} | 앞 문자가 n번 반복되는 패턴 | |
| {m,n} | 앞 문자가 m번 반복되는 패턴부터 n번 반복되는 패턴 |
