💡 관계형 DB 개요
◽ 데이터베이스(DB)
-
특정 기업이나 조직 또는 개인이 필요에 의해 데이터를 일정한 형태로 저장해 놓은 것
-
DBMS를 이용하여 효율적인 데이터 관리와 데이터 손상이 복구 가능하다.
-
DBMS(Database Management System)❓ :많은 사용자들은 보다 효율적인 데이터의 관리 뿐만 아니라 예기치 못한 사건으로 인한 데이터의 손상을 피하고,필요시 필요한 데이터를 복구하기 위한 강력한 기능의 소프트웨어를 필요로 하게 되었고 이러한 기본적인 요구사항을 만족시켜주는 시스템
◽ 데이터베이스의 발전
-
1960년대 : 플로우차트 중심의 개발 방법 사용, 파일구조를 통해 데이터를 저장
-
1970년대 : 데이터베이스 관리 기법이 처음 태동, 계층형 데이터베이스, 망형 데이터베이스 상용화
-
1980년대 : 관계형 데이터베이스 상용화, Oracle, Sybase, DB2 제품 사용
-
1990년대 : Oracle, Sybase, Informix, DB2, Teradata, SQL Server 등 핵심 솔루션이 됨, 객체 관계형 데이터베이스로 발전
◽ 관계형 데이터베이스 (Relational Database)
1970년 영국의 수학자 E.F. Codd 박사의 논문에서 처음으로 관계형 데이터베이스 소개 후 기존의 파일시스템과 계층형, 망형 데이터베이스를 대부분 대체하면서 현재 주력 DB SQL을 사용하여 관리함으로 관계형 데이터베이스와(RDB) SQL의 중요성 높아졌다.
종류는 (계층형 DB, 네트웨크형 DB, 관계형 DB) 3가지가 있다.
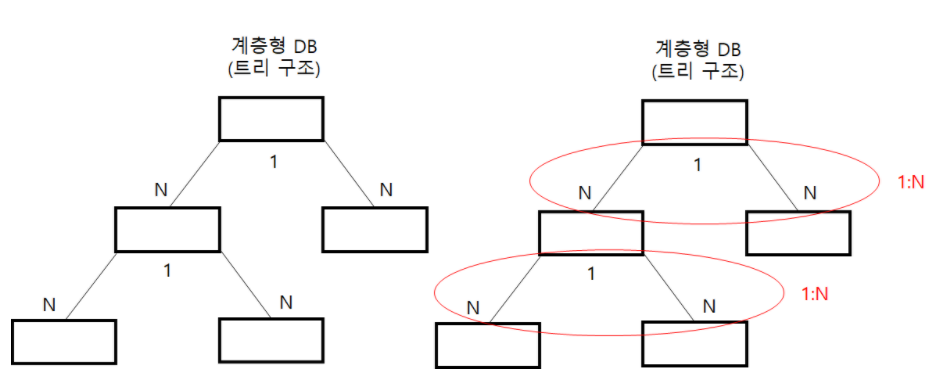
▪ 계층형 DB
◽ 트리 형태의 자료구조에 데이터 저장하며, 1:N 관계를 표현한다.
▪ 네트웨크형(망 형) DB
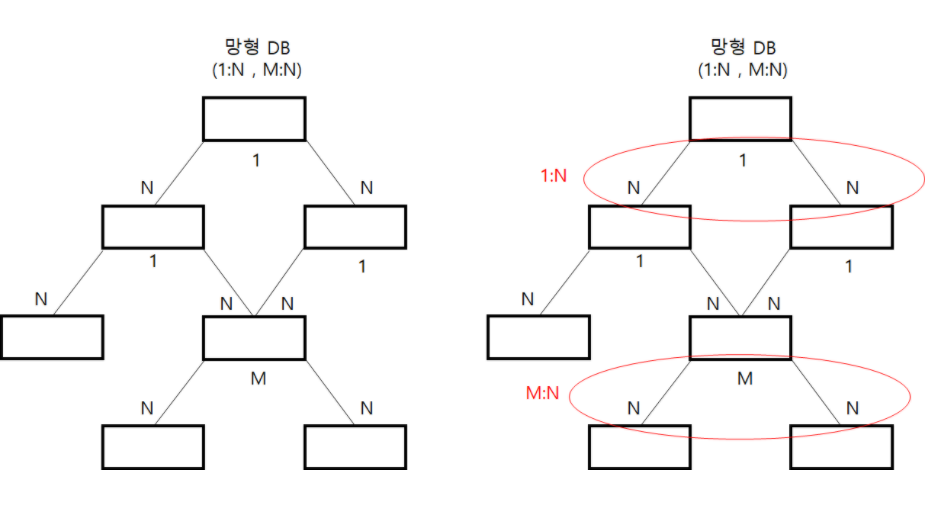
◽ 오너와 멤버 형태로 데이터 저장하며, 1:N과 함께 M:N 관계도 표현도 가능하다.
▪ 관계형 DB
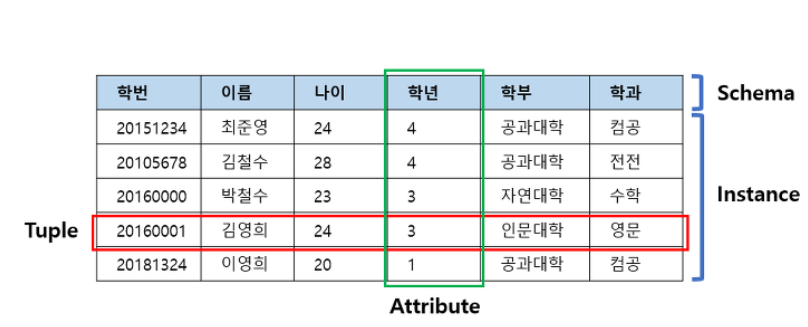
◽ 릴레이션에 데이터 저장,관리하며 릴레이션을 사용해서 집합연산과 관계 연산을 할 수 있다.
- 릴레이션(Relation)주로 테이블(Table)과 같은 의미로 사용되며, 데이터의 집합을 의미한다.
- 튜플(Tuple)과 어트리뷰트(Attribute)로 구성되어있다.
◽ 집합 연산
| 집합 연산 | 설명 |
|---|---|
| 합집합(Union) | - 두 개의 릴레이션을 하나로 합하는 것이다. - 중복된 행(튜플)은 한 번만 조회된다. |
| 차집합(Difference) | 본래 릴레이션에는 존재하고 다른 릴레이션에는 존재하지 않는 것을 조회한다. |
| 교집합(Intersection) | 두 개의 릴레이션 간에 공통된 것을 조회한다. |
| 곱집합(Cartesian product) | 각 릴레이션에 존재하는 모든 데이터를 조합하여 연산한다. |
◽ 관계 연산
| 관계 연산 | 설명 |
| 선택 연산 | 릴레이션에서 조건에 맞는 행(튜플)만을 조회한다. |
| 투영 연산 | 릴레이션에서 조건에 맞는 속성만을 조회한다. |
| 결합 연산 | 여러 릴레이션의 공통된 속성을 사용해서 새로운 릴레이션을 만들어 낸다. |
| 나누기 연산 | 기준 릴레이션에서 나누는 릴레이션이 가지고 있는 속성과 동일한 값을 가지는 행(튜플)을 추출하고 나누는 릴레이션의 속성을 삭제한 후 중복된 행을 제거하는 연산 |
◽ SQL(Structured Query Language)
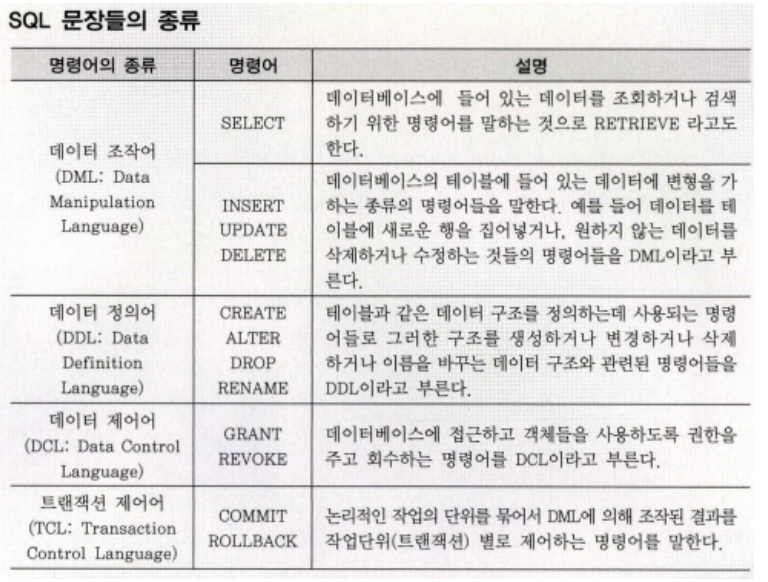
-
관계형 데이터베이스(RDB)에서 사용하는 언어.
-
데이터 구조 정의/ 데이터 조작/ 데이터 제어 등을 할 수 있는 절차형 언어
◽ 테이블(Table)
데이터는 관계형 데이터베이스의 기본단위인 테이블 형태로 저장된다.
또한 모든 자료는 테이블에 등록이 되고 우리는 테이블로부터 원하는 자료를 꺼내 올 수 있다.
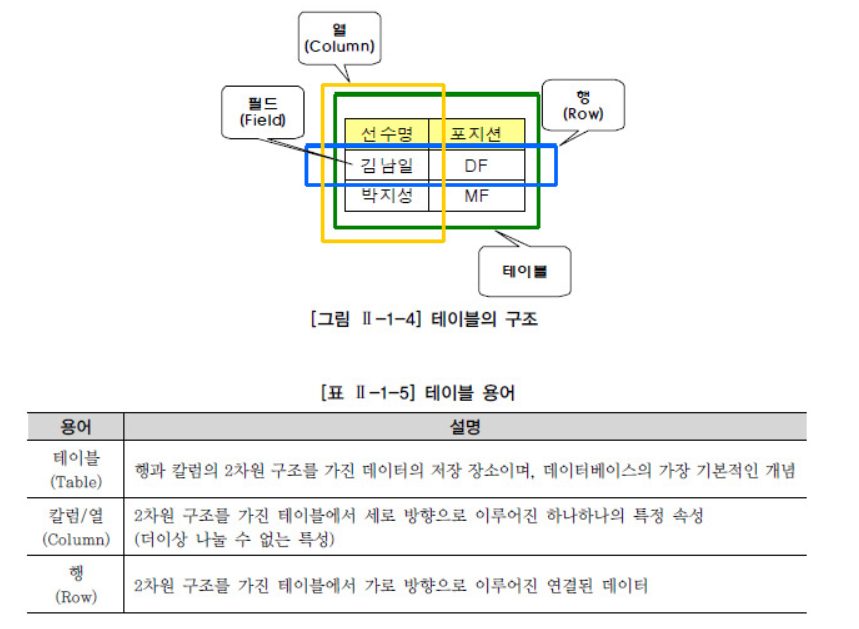
-
테이블은 데이터를 저장하는 객체(Object)로서 관계형 데이터베이스의 기본단위이다.
-
관계형 데이터베이스에서는 모든 데이터를 칼럼과 행의 2차원 구조로 나타낸다.
-
세로 방향을 칼럼(Column), 가로방향을 행(Row)이라고 하고, 칼럼과 행이 겹치는 하나의 공간을 필드라고 한다.
◽ ERD (Entity Relationship Diagram)
엔티티(사람, 사물 등)간의 관계를 잘 표현할 수 있는 것은 ERD이다. 이는 관계의 의미를 직관적으로 표현할 수 있는 좋은 수단이다.
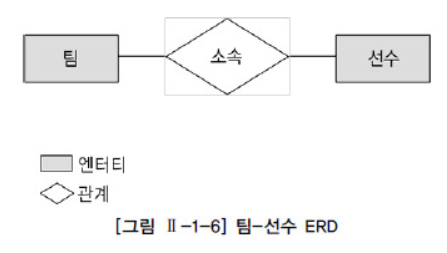
ERD의 구성요소는 엔티티(Entity), 관계(Relationship), 속성(Attribute) 세가지 이다. 현실세계의 데이터는 이 3가지 구성요소로 모두 표현이 가능하다.
◽ DDL(Data Definition Language)
-
관계형 데이터베이스(Relation Database)는 릴레이션(Relation)에 데이터를 저장, 관리한다.
-
릴레이션은 데이터베이스 관리시스템(DBMS)에서 테이블(Table)로 생성된다.
-
데이터베이스를 사용하기 위해서는 테이블을 먼저 생성해야 한다.
테이블 생성 테이블 변경 테이블 삭제 Create Table Alter Table Drop Table - 새로운 테이블 생성
- 기본키, 외래키, 제약사항 설정- 생성된 테이블 변경
- 칼럼 추가, 변경, 삭제
- 기본키, 외래키 설정- 해당 테이블 삭제
- 데이터 구조, 저장된 데이터 모두 삭제
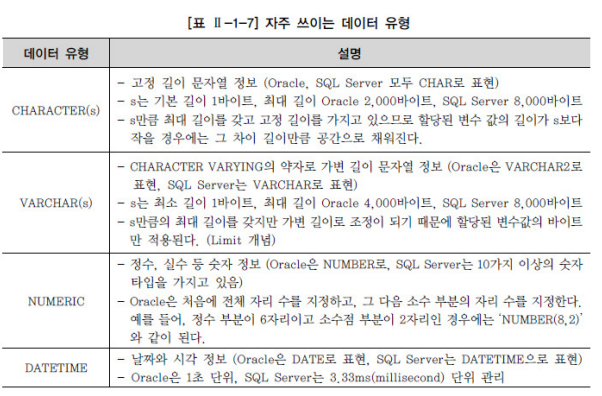
▪ 데이터 유형
▪ CREATE TABLE
| Create Table | 칼럼 정보 | 데이터 타입 | 기본키 (PK) |
| - 테이블 하나를 생성 - Create Table 테이블명 - ( ) 사이에 칼럼 입력 - 마지막은 세미콜론 ; |
- 테이블에 포함시킬 칼럼의 이름, 데이터타입 입력 - 칼럼이름은 영문, 한글, 숫자 모두 가능함 |
- number: 숫자형 타입 - varchar2: 가변길이 문자열 - char: 고정된 크기의 문자열 - date: 날짜형 타입 |
- 칼럼 옆에 primary key 입력하여 테이블의 기본키를 지정 |
SQL >>
CREATE TABLE 테이블 이름 (칼럼명1 DATATYPE [DEFAULT 형식], 칼럼명1 DATATYPE [DEFAULT 형식], 칼럼명1 DATATYPE [DEFAULT 형식] );
- EX)
CREATE TABLE PLAYER
( PLAYER_ID CHAR(7) NOT NULL, PLAYER_NAME VARCHAR(20) NOT NULL,
TEAM_ID CHAR(3) NOT NULL, E_PLAYER_NAME VARCHAR(40),
NICKNAME VARCHAR(30), JOIN_YYYY CHAR(4), POSITION VARCHAR(10),
BACK_NO TINYINT, NATION VARCHAR(20), BIRTH_DATE DATE, SOLAR CHAR(1),
HEIGHT SMALLINT, WEIGHT SMALLINT,
CONSTRAINT PLAYER_PK PRIMARY KEY (PLAYER_ID),
CONSTRAINT PLAYER_FK FOREIGN KEY (TEAM_ID) REFERENCES TEAM(TEAM_ID) );
-
제약조건(CONSTRAINT): 사용자가 원하는 조건의 데이터만 유지하기 위한 방법 즉, 데이터의 무결성을 유지하기 위한 데이터베이스의 보편적인 방법으로 테이블의 특정 칼럼에 설정하는 제약
-
기존테이블의 제약조건 중 NOT NULL만 새로운 복제테이블에 적용된다.
-
테이블 생성 시 CASCADE 옵션 사용: 참조관계(기본키-외래키 관계)가 있는 경우, 참조되는 데이터를 자동으로 반영할 수 있다 또한 CASCADE 옵션을 사용하여 참조 무결성을 준수할 수 있다.
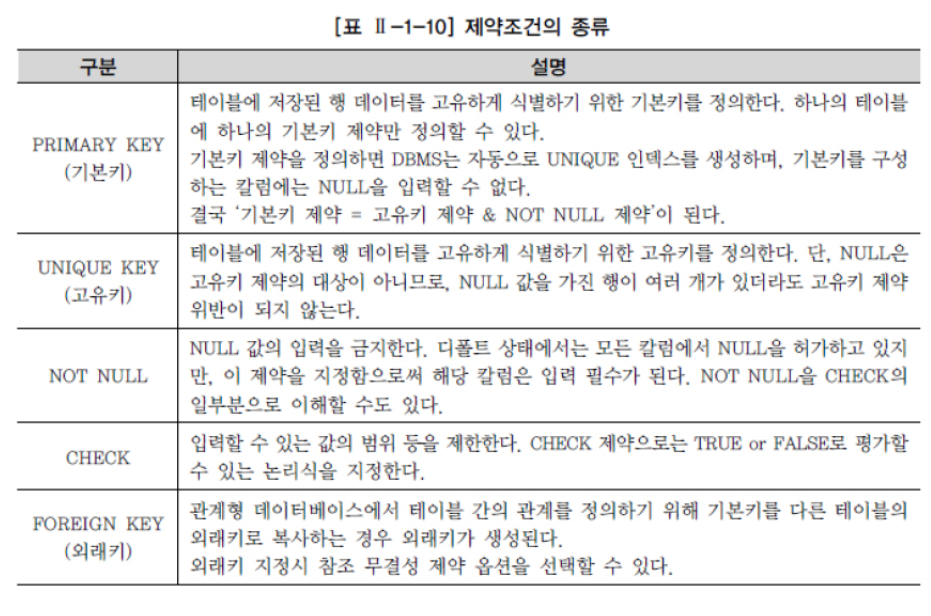
✔ NULL은 “아직 정의되지않은 미지의 값”, “현재 데이터를 입력하지 못하는 경우” 이며, DEFAULT는 데이터입력 시에 칼럼의 값이 지정되어 있지 않을 경우 기본값을 설정 가능하다.
✔ SELECT 문장을 통한 테이블 생성 사례: (Create Table ~ As Select~), (Select ~ Into ~)
✔ NULL과의 수치연산: NULL 비교연산: FALSE 출력
✔ 생성된 테이블 구조 확인
- Oracle: “DESCRIBE 테이블명;”
- SQL Server: “sp_help ‘dbo.테이블명’”
▪ ALTER TABLE | 테이블 변경
-
테이블의 칼럼 관련 변경 명령어
ALTER TABLE 테이블이름 ADD 속성_이름 데이터타입 [DEFAULT]; //추가 ALTER TABLE 테이블이름 ALTER 속성_이름 [SET DEFAULT]; //속성명변경 ALTER TABLE 테이블이름 DROP 속성_이름 [CASCADE | RESTRICT]; //속성 삭제 ALTER TABLE PLAYER ADD ADDRESS VARCHAR(80); ALTER TABLE PLAYER DROP COLUMN ADDRESS; ALTER TABLE TEAM_TEMP ALTER COLUMN ORIG_YYYY VARCAHR(8) NOT NULL;``` -
DROP COLUMN: 데이터가 있거나 없거나 모두 삭제 가능. 한번에 하나의 칼럼만 삭제 가능.
- 삭제 후 복구를 할 수 없다.
- 삭제 후 복구를 할 수 없다.
-
MODIFY COLUMN:칼럼 설정 변경
- NULL만 있거나, 행이 없는 경우에만 칼럼의 크기 축소 가능하다.
- NULL만 있을 때는 데이터 유형도 변경 가능하다.
- NULL이 없으면 NOT NULL 제약조건 추가 가능하다.
- 기본값 변경 작업 이후 발생하는 데이터에 대해서만 기본값이 변경된다.
-
RENAME COLUMN : 칼럼명 변경
-
DROP CONSTRAINT: 테이블 생성 시 부여했던 제약조건을 삭제하는 명령어
-
ADD CONSTRAINT: 테이블 생성 이후에 필요에 의해서 제약조건을 추가한다.
▪ RENAME TABLE |테이블 삭제
ALTER TABLE 테이블명
RENAME COLUMN 변경해야할 컬럼명 TO 새로운 컬럼명;
ALTER TABLE PLAYER
RENAME COLUMN PLAYER_ID TO TEAM_ID;
▪ DROP TABLE |테이블 삭제
DROP TABLE DEPT CASCADE CONSTRAINT;
ALTER TABLE 테이블명 DROP COLUMN 삭제할 컬럼명;
DROP TABLE PLAYER; ➡(테이블 전부 삭제, 회복 불가)
ALTER TABLE PLAYER DROP COLUMN ADDRESS; ➡(테이블 의 일부 칼럼 삭제, 회복 불가)-
테이블의 데이터와 구조 삭제, 복구 불가
-
CASCADE CONSTRAINT 옵션: 해당 테이블의 데이터를 외래키로 참조한 슬레이브 테이블, 관련된 제약사항까지 모두 삭제한다.
(CREATE TABLE에서 ON DELETE CASCADE 옵션으로도 동일 기능 실현 가능)
▪ TRUNCATE TABLE
TRUNCATE TABLE 테이블명 DROP COLUMN 삭제할 컬럼명;
- 테이블 자체가 삭제되는 것이 아니라, 해당테이블에 들어있던 모든 행들이 제거되는 것 즉 데이터만 제거
- 기존에 사용하던 테이블의 모든 로우(Row)를 제거하기 위한 명령어이다.
◽ DML (Data Manipulation Language)
- DML: 테이블에서 데이터를 입력, 수정, 삭제, 조회하기 위한 SQL문
- 조건문 : WHERE절로 조건문을 생성하여 원하는 조건을 검색한 다음, 데이터 수정 or 삭제 or 조회를 수행한다.
▪ INSERT | 테이블에 데이터 입력
INSERT INTO ~ VALUES ~~
INSERT INTO 테이블명 (COLUMN_LIST)VALUES (COLUMN_LIST에 넣을 VALUE_LIST);
INSERT INTO 테이블명VALUES (전체 COLUMN에 넣을 VALUE_LIST);
PLAYER INSERT INTO PLAYER
(PLAYER_ID, PLAYER_NAME, TEAM_ID, POSITION, HEIGHT, WEIGHT, BACK_NO) —>(칼럼 리스트)
VALUES ('2002007', '박지성', 'K07', 'MF', 178, 73, 7);| INSERT 문 | SELECT 문으로 입력 | Nologging 사용 |
| 테이블명-칼럼명-데이터 순서로 입력 | 데이터를 조회하여 바로 테이블로 삽입 | 로그파일 기록 최소화 → 성능 향상 |
| - 모든 칼럼에 대해 데이터 삽입하는 경우: 칼럼명 생략 가능 - 문자열 입력하는 경우: 작은 따옴표 사용 - 데이터 파일에 저장되는 것이 아님 → 저장하려면 TCL문 Commit 실행 |
- 다른 테이블에서 SELECT 문으로 데이터를 조회하여, 해당 테이블로 삽입 - 입력되는 테이블은 사전에 생성되어 있어야 함 |
- 데이터베이스에 데이터 입력 → 로그파일에 정보 기록됨 - Nologging 옵션: 로그파일 기록 최소화 → Buffer Cache 메모리 영역을 생략 → 데이터 입력 시 성능 향상↑ |
▪ UPDATE 문 | 데이터 수정
UPDATE ~ SET ~~
UPDATE 테이블명 SET 수정되어야 할 칼럼명 = 수정되기를 원하는 새로운 값;
UPDATE PLAYER SET BACK_NO = 99;
UPDATE PLAYER SET POSITION = 'MF'; ➡(문자값인 경우 ‘ ’ 사용)- WHERE절에서 원하는 조건으로 데이터 검색 → 해당 데이터 값을 수정
- 조건문이 있으면 → WHERE절에서 검색된 행 수만큼 수정됨
- 조건문이 없으면 → 모든 데이터가 수정된다.
▪ DELETE 문 | 데이터 삭제
DELETE FROM ~
DELETE FROM 삭제를 원하는 정보가 들어있는 테이블명 WHERE 조건절;
DELETE FROM PLAYER; ➡(조건절이 없으면 전체 테이블 삭제)
-
DELETE문은 "삭제 여부"만 표시함 → 용량 초기화 X → 테이블 용량 감소 X
-
TRUNCATE문은 테이블의 데이터 삭제 & 용량 초기화 → 테이블 용량 감소
- 테이블 구조는 삭제하지 않는다.
- 테이블의 데이터를 모두 삭제한 후 테이블 공간을 초기화한다.
▪ SELECT 문 | 데이터 조회
SELECT ~ FROM ~~
SELECT 칼럼명 FROM 테이블;
SELECT PLAYER_ID, PLAYER_NAME, TEAM_ID, POSITION FROM PLAYER;
SELECT DISTINCT POSITION FROM PLAYER; ➡(DISTICNT: 중복데이터를 1건으로 표시)
SELECT * FROM PLAYER; ➡(*: 모든 칼럼명 선택)
SELECT PLAYER_NAME AS 선수명 FROM PLAYER; ➡(AS: 칼럼명에 별명붙이고 별명으로 표시)-
SELECT문: 특정 칼럼 or 행만 조회
-
SELECT columns: 칼럼 지정
-
FROM table: 테이블 지정
-
WHERE ~~: 행 지정
-
| SELECT문 사용 | 정렬: ORDER BY | 정렬 회피: INDEX | 중복제거 및 별칭지정 |
| - SELECT columns FROM table; - WHERE: 조건문 지정 |
- ORDER BY column; - 오름차순: ASC - 내림차순: DESC |
- 기본키가 인덱스인 경우 - 자동으로 오름차순 index 생성 |
- 중복제거: Distinct - 별칭지정: Alias |
※ 앨리어스(Alias)❓
- SELECT 칼럼명 AS “별명” : 출력되는 칼럼명 설정
- FROM 테이블명 별명 : 쿼리 내에서 사용할 테이블명 설정, 칼럼명이 중복될 경우 SELECT절에서 앨리어스 필수
- 문자열의 합성 연산자: ‘+’(플러스), CONCAT 함수로도 2개 문자열 합성 가능, Oracle에서는 ‘||’(수직선 2개)도 가능
- DUAL : Oracle의 기본 더미 테이블, 연산 수행을 위해 사용됨
▪ 산술연산자 & 합성 연산자
SELECT PLAYER_NAME 이름, HEIGHT - WEIGHT "키-몸무게" FROM PLAYER;
우선순위를 위한 괄호 적용이 가능하다.
일반적으로 산술 연산을 사용하거나 특정 함수를 적용하게 되면 기존의 칼럼에 대해 새로운 의미를 부여한 것이므로 적절한 ALIAS를 새롭게 부여하는 것이 좋다.
- Oracle SQL>>
SELECT PLAYER_NAME || ‘선수, ' || HEIGHT || 'cm,' || WEIGHT || 'kg' 체격정보 FROM PLAYER; ``` - SQL>>
SELECT PLAYER_NAME +'선수, '+ HEIGHT +'cm, '+ WEIGHT +'kg'체격정보 FROM PLAYER; >>> 정경량선수173cm,65kg 정은익선수,176cm,63kg 레오마르선수,183cm,77kg 명재용선수,173cm,63kg```
◽ TCL(Transaction Control Language)
▪ 트랜잭션 개요: “데이터베이스의 논리적 연산 단위” ➡ (계좌이체 트랜젝션)
- 하나 이상의 SQL문을 포함한다.
▪ 트랜잭션 특성(ACID)
| 원자성 [Atomicity] |
트랜잭션에서 정의된 연산들은 모두 성공적으로 실행되던지 아니면 전혀 실행되지 않은 상태로 남아야한다. → all or nothing |
| 일관성 [Consistency] |
트랜잭션 실행 전의 데이터베이스 내용이 잘못되지 않으면 트랜잭션 실행 후에도 데이터베이스 내용이 잘못되면 안된다. |
| 고립성 [Isolation] |
트랜잭션 실행 도중에 다른 트랜잭션의 영향을 받아 잘못된 결과를 만들면 안된다. LOCKING으로 고립성 보장 |
| 영속성, 지속성 [Durability] |
트랜잭션 실행이 성공적일 때, 그 트랜잭션이 갱신한 데이터베이스 내용은 영구적으로 저장된다. |
- 커밋(COMMIT): 올바르게 반영된 데이터를 데이터베이스에 반영시키는 것
- 롤백(ROLLBACK): 트랜잭션 시작 이전의 상태로 되돌리는 것
- 저장점(SAVEPOINT): 저장점 기능
▪ COMMIT
- 데이터를 DB에 영구적으로 반영하는 명령어
- 커밋 시 트랜잭션이 완료되어 LOCKING이 해제됨, SQL Server은 기본적으로 자동 커밋
-
Oracle SQL>>
UPDATE PLAYER SET HEIGHT = 100;
COMMIT; -
SQL>>
UPDATE PLAYER SET HEIGHT = 100;
-
COMMIT 전
-
데이터 변경이 메모리 버퍼에만 영향을 받았기 때문에 복구가 가능하다. (NOLOGGING 옵션 사용 시 버퍼 캐시의 기록을 생략하여 입력 성능이 향상된다.)
-
사용자는 SELECT절로 결과를 확인할 수 있으나 다른 사용자는 현재 결과를 볼 수 없다.
-
변경된 행에 LOCKING이 설정되어 다른 사용자가 변경할 수 없다. (LOCKING이 안 걸린 상태일 때 여러 사용자가 데이터를 변경하면 상관없다.)
-
-
COMMIT 후
- 변경 사항이 DB에 반영되고 이전 데이터는 복구가 불가능 하다.
- 모든 사용자가 결과를 볼 수 있다.
- LOCKING이 해제되어 다른 사용자가 행을 조작할 수 있다.
▪ ROLLBACK
- 트랜잭션 시작 이전의 상태로 되돌리는 명령어
- COMMIT 이전 상태로 돌려주며, ROLLBACK 시 LOCKING이 해제된다.
- Oracle SQL>>
UPDATE PLAYER SET HEIGHT = 100; ———>(480개의 행이 수정되었다.) ROLLBACK; ———>(롤백이 완료되었다.)``` - SQL>>
BEGIN TRAN UPDATE PLAYER SET HEIGHT = 100; ROLLBACK; ———>(롤백이 완료되었다.)``` - SAVEPOINT: 트랜잭션 일부만 롤백 할 수 있도록 중간상태를 저장하는 명령어, ‘ROLLBACK TO 저장점명’ 시 해당 저장점(SAVEPOINT) 상태로 돌려준다.
- 동일한 저장점명이 있으면 나중 저장점(SAVEPOINT)이 유효하다.
- SQL Server에서는 ’BEGIN TRAN’으로 명시해야 가능하다.
