💡 조인 수행 원리
조인이란 ❓
두 개 이상의 테이블을 하나의 집합으로 만드는 연산이다.
-
일반적으로 행들은 PK나 FK값의 연관에 의해 조인이 성립된다.
-
PK, FK의 관계가 없어도 논리적인 값들의 연관만으로 조인이 성립되는 경우도 있다.
-
SQL 문에서 FROM 절에 두 개 이상의 테이블이 나열될 경우 조인이 수행된다.
-
FROM 절에 A, B, C 테이블을 조인할 경우, A,B를 먼저 조인하고 그 결과와 C를 조인하게 되는 과정을 거친다.
◽ 대표적인 조인 기법
| Nested Loop Join | - 선행 테이블에서 액세스한 각 값을 후행 테이블과 조인하는 방식 |
| Sort Merge Join | - 조인 컬럼을 기준으로 데이터를 정렬하여 조인을 수행하는 방식 |
| Hash Join | - 해시 함수를 이용해서 데이터를 조인하는 방식 |
◽ NL Join
-
NL Join은 프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행한다.
-
반복문의 외부에 있는 테이블을 선행 테이블 또는 외부 테이블(Outer Table)이라 한다.
-
반복문 내부에 있는 테이블을 후행 테이블 또는 내부 테이블(Inner Table) 이라고 한다.
-
선행 테이블의 조건을 만족하는 행을 추출하여 후행 테이블을 읽으면서 조인을 수행한다.
-
결과 행의 수가 적은(처리 주관 범위가 좁은) 테이블을 조인 순서 상 선행 테이블로 선택하는 것이 전체 일량을 줄일 수 있다.
-
랜덤 방식으로 데이터를 액세스- 추출버퍼(= 운반단위, Array Size, Prefetch Size)는 SQL문의 실행 결과를 보관하는 버퍼
-
선행 테이블에 사용 가능한 인덱스가 존재한다면 인덱스를 통해 선행 테이블을 액세스 할 수 있음- 조인 성공 시 바로 조인 결과를 사용자에게 보여줄 수 있으며, 온라인 프로그램에 적절 하다.
◾ NJ Join의 동작 원리
① 선행 테이블에서 주어진 조건을 만족하는 행을 찾는다.
② 선행 테이블의 조인 키 값을 가지고 후행 테이블에서 조인 수행한다.
③ 선행 테이블의 조건을 만족하는 모든 행에 대해 1번 작업 반복 수행한다.
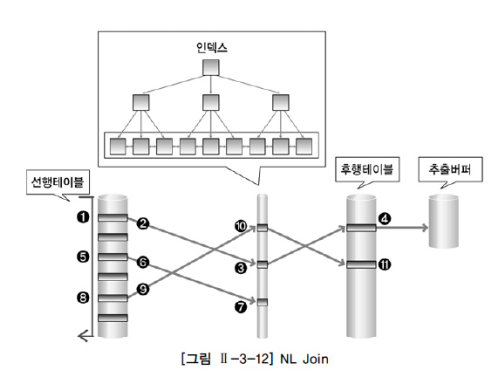
- 선행 테이블에서 조건을 만족하는 첫 번째 행을 찾는다.
- 선행 테이블의 조인 키를 가지고 후행 테이블에 조인 키가 존재하는지 찾는다.
- 후행 테이블의 인덱스에 선행 테이블의 조인 키가 존재하는지 확인4. 인덱스에서 추출한 레코드 식별자를 이용하는 후행 테이블을 액세스5~11. 앞의 작업을 반복 수행한다.
◽ Sort Merge Join
-
Sort Merge Join은 조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행한다.
-
NL Join은 랜덤 액세스 방식, Sort Merge Join은 스캔 방식 사용한다.
-
정렬할 데이터가 많은 경우 임시 영역(디스크)을 사용하기 때문에 성능이 떨어질 수도 있다.
-
대량의 조인 작업은 CPU 작업 위주로 처리하는 Hash Join이 성능상 유리하다.
-
Hash Join과는 달리 동등 조인 뿐만 아니라 비동등 조인에 대해서 조인 작업 가능하다.
-
조인 칼럼의 인덱스를 사용하지 않기 때문에 조인 칼럼의 인덱스가 존재하지 않을 경우에 사용가능하다.
-
수행 도중 정렬 작업이 미리 수행되었다면 조인을 위한 정렬작업이 발생되지 않을 수도 있다.
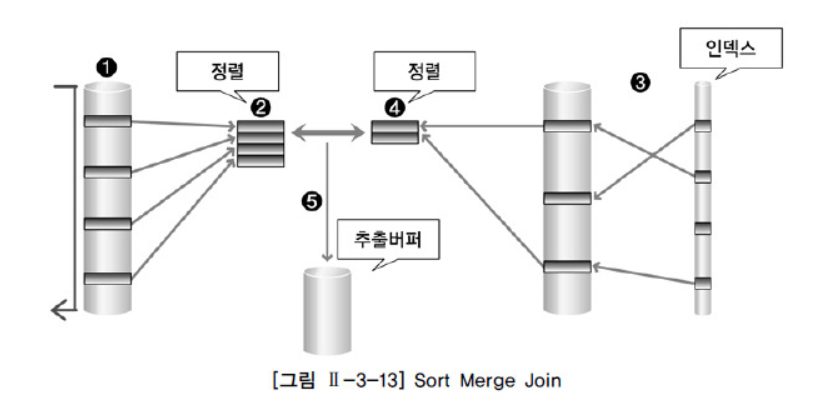
◾ Sort Merge Join의 동작 원리
① 선행 테이블에서 주어진 조건을 만족하는 행을 찾는다.
② 선행 테이블의 조인 키를 기준으로 정렬 작업을 수행한다.
- 1~2번 작업을 선행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행한다.
③ 후행 테이블에서 주어진 조건을 만족하는 행을 찾는다.
④ 후행 테이블의 조인 키를 기준으로 정렬 작업을 수행한다.
- 3~4번 작업을 후행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행한다.
⑤ 정렬된 결과를 이용하여 조인을 수행하며 조인에 성공하면 추출버퍼에 넣는다.
◽ Hash Join
-
Hash Join은 해슁 기법을 이용하여 조인을 수행한다.
-
조인을 수행할 테이블의 조인 칼럼을 기준으로해쉬 함수를 수행하여 서로 동일한 해쉬 값을 갖는 것들 사이에서 실제 값이 같은지를 비교하면서 조인을 수행한다.
-
Hash Join은 NL Join의 랜덤 액세스 문제점과 Sort Merge Join의 문제점인 정렬 작업의 부담을 해결한다.
-
조인 칼럼의 인덱스를 사용하지 않기 때문에 조인 칼럼의 인덱스가 존재하지 않을 경우 사용 가능하다.
-
동등 조인에서만 사용 가능하다.
-
해쉬 함수를 적용한 값은 어떤 값으로 해슁될 지 알 수 없다.
-
해쉬 테이블을 메모리에 생성해야하고, 크기가 클 경우 임시 영역에 저장하기 때문에 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋다.
-
OLAP 환경에 적합하다.
-
먼저 해쉬 테이블을 생성하는선행 테이블(Build Input), 해쉬 테이블에 대해 해쉬 값의 존재 여부를 검사하는 후행 테이블(Prove Input) 로 이루어져 있다.
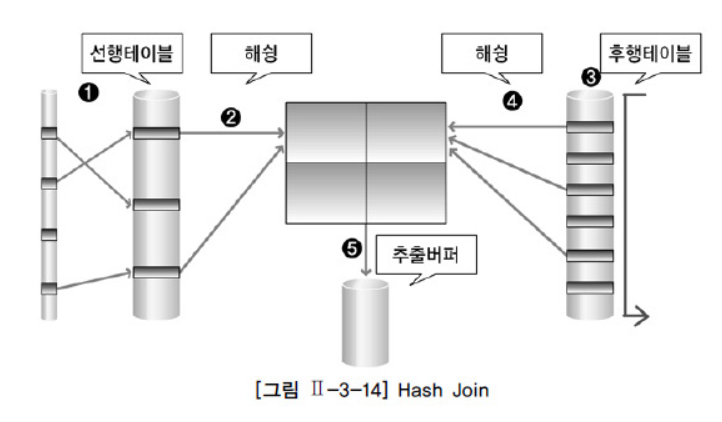
◾ Hash Join의 동작 원리
① 선행 테이블에서 주어진 조건을 만족하는 행을 찾는다.
② 선행 테이블의 조인 키를 기준으로 해쉬 함수를 적용하여 해쉬 테이블을 생성한다.
-
조인 칼럼과 SELECT 절에서 필요로 하는 칼럼도 함께 저장된다.
-
1~2번 작업을 선행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행한다.
③ 후행 테이블에서 주어진 조건을 만족하는 행을 찾는다.
④ 후행 테이블의 조인키를 기준으로 해쉬 함수를 적용하여 해당 버킷을 찾는다.
- 조인 키를 이용해서 실제 조인될 데이털르 찾는다.
⑤ 조인에 성공하면 추출버퍼에 넣는다.
- 3~5번 작업을 후행 테이블의 조건을 만족하는 모든 행에 대해서 반복 수행한다.
