💡 성능 데이터 모델링 - 반정규화
반정규화란?
-
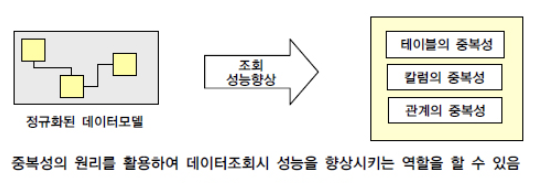
정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위하여 중복을 허용하고, 조인을 줄이는 데이터 모델링 기법이다.
-
반정규화는 데이터 무결성이 깨질 수 있는 위험을 감수하고 조회(select) 속도를 향상시키지만, 데이터 모델의 유연성은 낮아진다.
◽ 반정규화를 수행하는 이유
-
디스크 I/O 양이 많아서 성능이 저하된 경우
-
경로가 너무 멀어 조인으로 인한 성능 저하된 경우
-
칼럼을 계산하여 읽을 때 성능이 저하된 경우
-
다량의 범위를 자주 처리해야하는 경우
-
특정 범위의 데이터만 자주 처리하는 경우
-
요약/집계 정보가 자주 요구되는 경우
◽ 반정규화 절차


클러스터링(Clustering) 이란❓
- 디스크로부터 데이터를 읽어오는 시간을 줄이기 위해서 조인이나 자주 사용되는 테이블의 데이터를 디스크의 같은 물리적인 위치에 정렬해서 저장시키는 방법
- 클러스터는 데이터 조회 성능을 향상 시키지만 데이터 저장, 수정, 삭제 또는 한 테이블 전체 Scan의 성능을 감소 시킨다.
◽ 반정규화 기법
▪ 테이블 반정규화
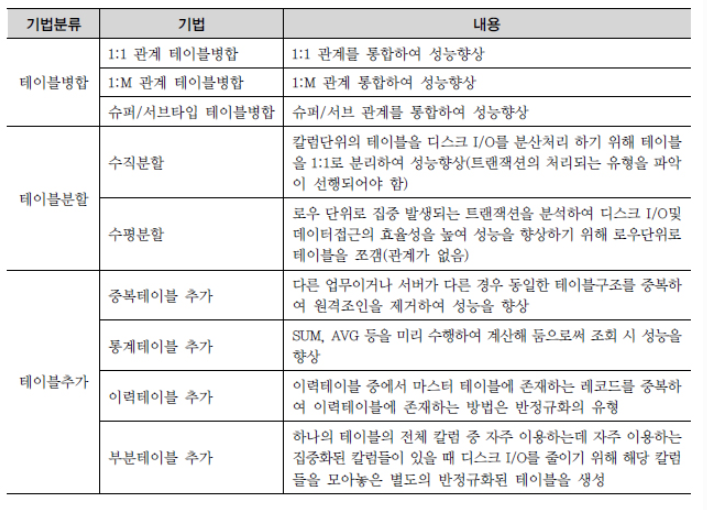
▪ 칼럼 반정규화

▪ 관계 반정규화

◽ 정규화가 잘 정의된 데이터 모델에서 성능이 저하될 수 있는 경우
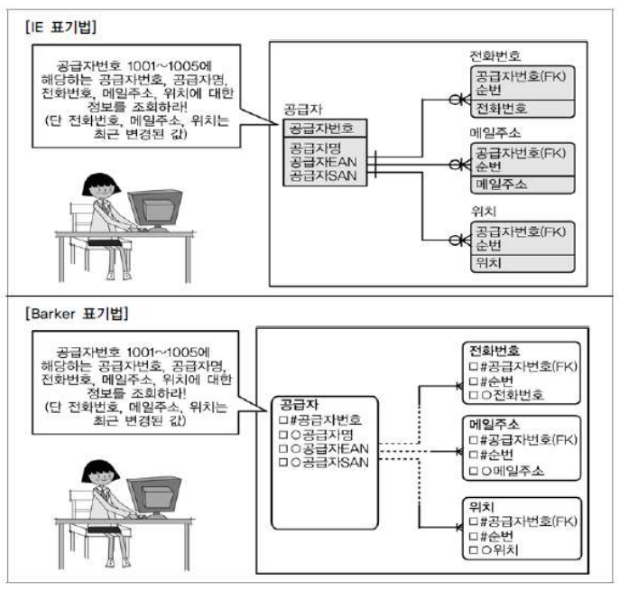
-정규화 모델의 문제점-
공급자와 전화번호, 메일주소, 위치는 1:M 관계이므로
한 명의 공급자 당 여러 개의 전화번호, 메일주소, 위치가 존재한다. 가장 최근에 변경된 값을 가져오려면 복잡한 JOIN 이 필요하다.
가장 최근에 변경된 값을 공급자 엔터티 위치시키도록 적절하게 반정규화를 적용하면, SQL 구문이 간단하게 된다.

-반정규화를 통한 성능향상 사례-
