💡 백준 1157 -단어공부(파이썬)
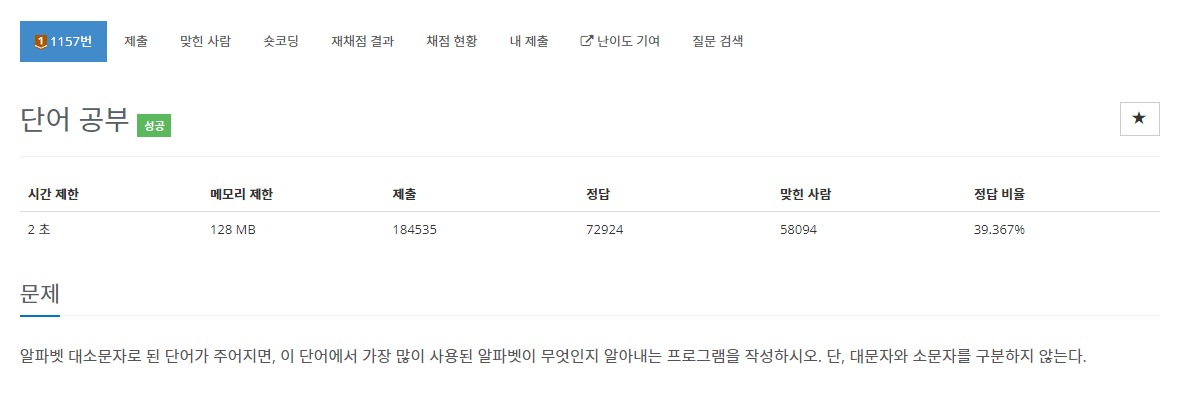
◽ 문제
◽ 입력 & 출력
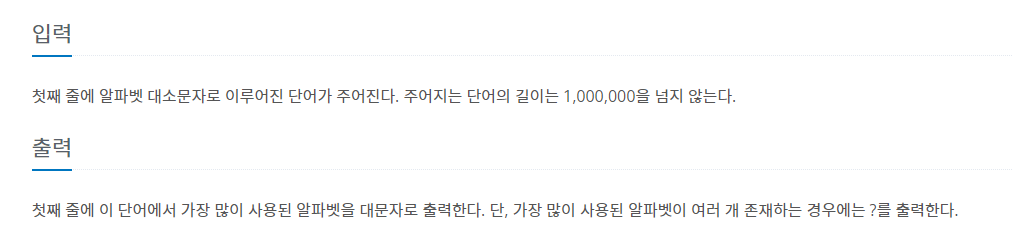
◽ 예제입력 & 예제출력
◽ 풀이
-
문자열을 입력받으면 문자열 중에서 가장 많이 사용된 알파벳 을 출력하는 문제이다.
-
가장 많이 사용된 알파벳의 개수가
1개가 아닌 경우에는 물음표를 출력해야 한다.

-
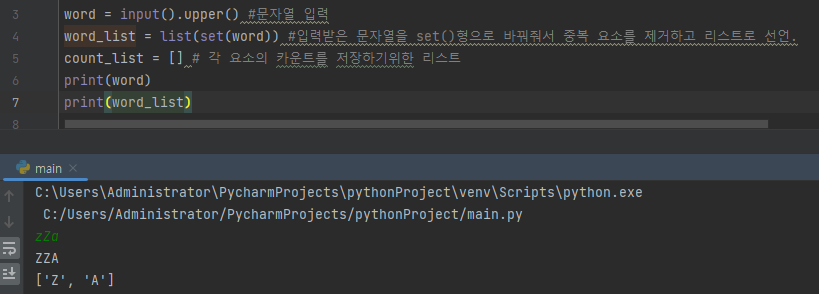
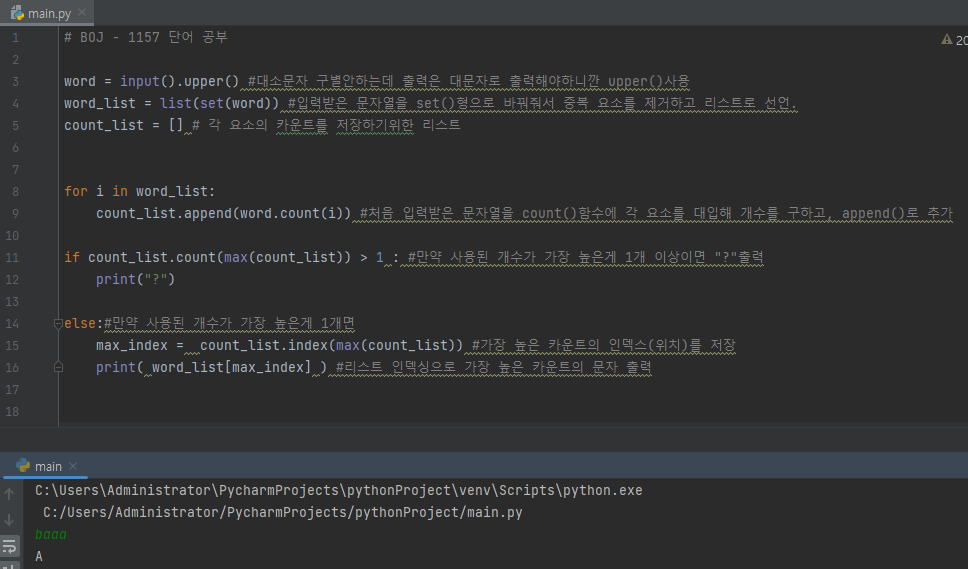
입력받은 문자열을 세트형으로 바꿔주고 리스트로 저장한 다음에 출력해보면 위와 같이 "zZa"를 입력했는데 word_list 에는 ['A', 'Z']가 저장된 것을 볼 수 있다.
-
9번째 줄을 보면 z가 2번 입력된 것을 볼 수있다.

정리하자면 위와 같이 baaa를 입력하면 16번째 줄에서 word_list 는 중복이 제거된 리스트가 출력되고,17번째 줄에서 count_list 를 보면 b가 1개 a가 3개
18번째 줄에서 count_list 의 가장 높은 카운트의 인덱스는 1번째 'A' 인것을 볼 수있다.
마지막으로 가장 높은 카운트의 인덱스 를 word_list에서 인덱싱 하면 A가 나오는 것을 볼 수있다.
💡 배운점
◽ count()
-
문자열 안에서 찾고 싶은 문자의 개수를 찾을 수 있다.
-
튜플, 리스트, 집합과 같은 반복 가능한 iterable 자료형에서도 사용 가능하다.
-
사용법
>>> 'ooyyy'.count('y')
3>>> b = 'ox o x oxoxox'
>>> b.count('ox')
4'o'와 'x'가 떨어져 있는 경우를 제외한 개수 4를 반환
