Cache

최근 프로젝트를 진행하던 중 프론트엔드의 숙명 중 하나인 웹 최적화와 관련해 자료를 서치하던 중 Cache를 발견했다.
Cash 아니고 Cache다.
쿠키나 세션과 더불어 기본적인 개념은 알고 있었지만 딥하게 파보지는 않았기 때문에
이번 글에서 자세히 다뤄보고 실제로도 적용해 보기 위해 이렇게 글을 남긴다.
Cache란?
캐시(Cache)는 데이터나 리소스를 미리 저장해두어서, 다음에 같은 요청이 오면 저장해둔 데이터를 반환하여 빠른 응답 속도를 제공하는 기술이다.
캐시는 웹 애플리케이션에서 매우 중요한 역할을 하며 서버에서 클라이언트로 전송되는 데이터의 양을 줄이고, 응답 속도를 향상시키며, 서버 부하를 감소시키는 데 도움이 된다.
캐시는 여러 곳에서 사용될 수 있으며, 대표적인 예로는 브라우저 캐시, CDN(Content Delivery Network) 캐시, 데이터 캐시, 코드 캐시 등이 있다.

당연하게도 캐시를 사용하는 것을 캐싱이라고 한다!
Cache Memory란?
캐시의 대표격인 캐시 메모리를 위주로 캐싱을 이해해보자.
Cache Memory의 도입
캐시 메모리를 이해하려면 간단하게 컴퓨터의 동작 흐름에 대해 알아야 하는데 살펴보고 넘어가자.
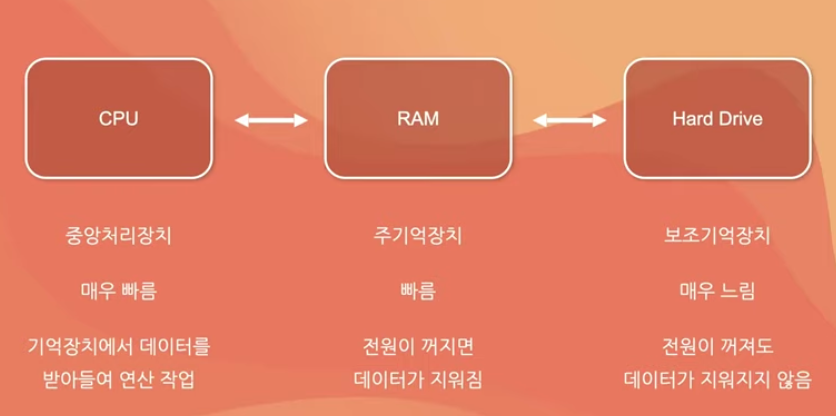
RAM은 하드디스크에서 데이터를 불러오고 CPU는 램의 저장되어 있는 데이터를 이용하여 연산 작업을 수행하는 구조이다.
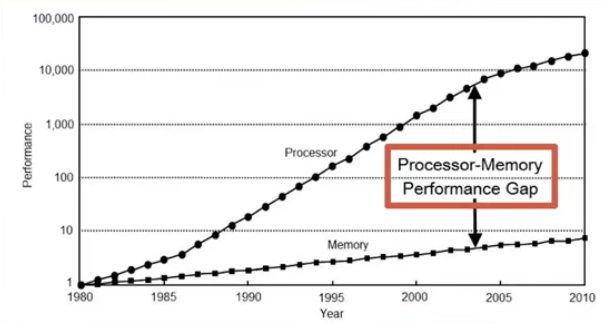
위 그래프는 CPU와 일반적으로 우리가 알고 있는 RAM간의 성능차이 그래프다.
CPU는 눈에 띄게 성능이 좋아진 반면 메모리는 그렇지 않은 걸 볼 수 있다.
왜 그럴까?
바로 그 이유는 CPU와 다르게 메모리는 속도보다는 메모리 자체의 용량을 늘리는 것을 주 목표로 삼았기 때문이다.
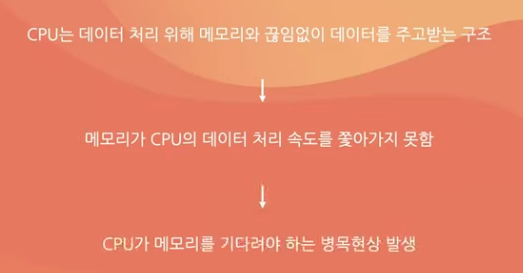
결과적으로 CPU와 메모리 간의 성능 차이는 점점 더 벌어지고 CPU는 데이터를 처리하기 위해 메모리와 끊임 없이 데이터를 주고 받는 관계인데
메모리가 CPU의 데이터 처리 속도를 쫓아가지 못해 CPU가 메모리를 기다려야 되는 병목현상이 일어나게 된다.

따라서 이 병목 현상을 완화하기 위해
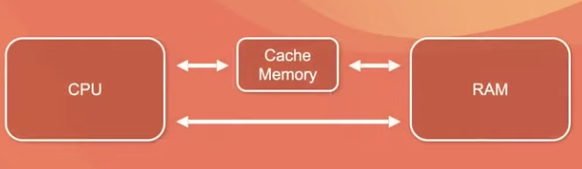
CPU와 메인 메모리 사이에 크기는 작지만 속도가 빠른 캐시 메모리를 두고

캐시 메모리의 향후 재사용 할 가능성이 클 것으로 예상되는 데이터에
복사본을 저장해 둔 후 CPU가 요청하는 데이커를 바로 바로 전달할 수 있도록 되었다.
그렇다면 캐시 메모리만 사용하면 되는 거 아닌가?
캐시 메모리의 용량을 크게 쓰거나, 아예 메인 메모리로 사용하면 되지 않을까 하고 생각할 수 있다.
안타깝게도 캐시 메모리는 비싸다.~~ 눈물 쓰-윽~~
아래의 사진을 살펴보자.
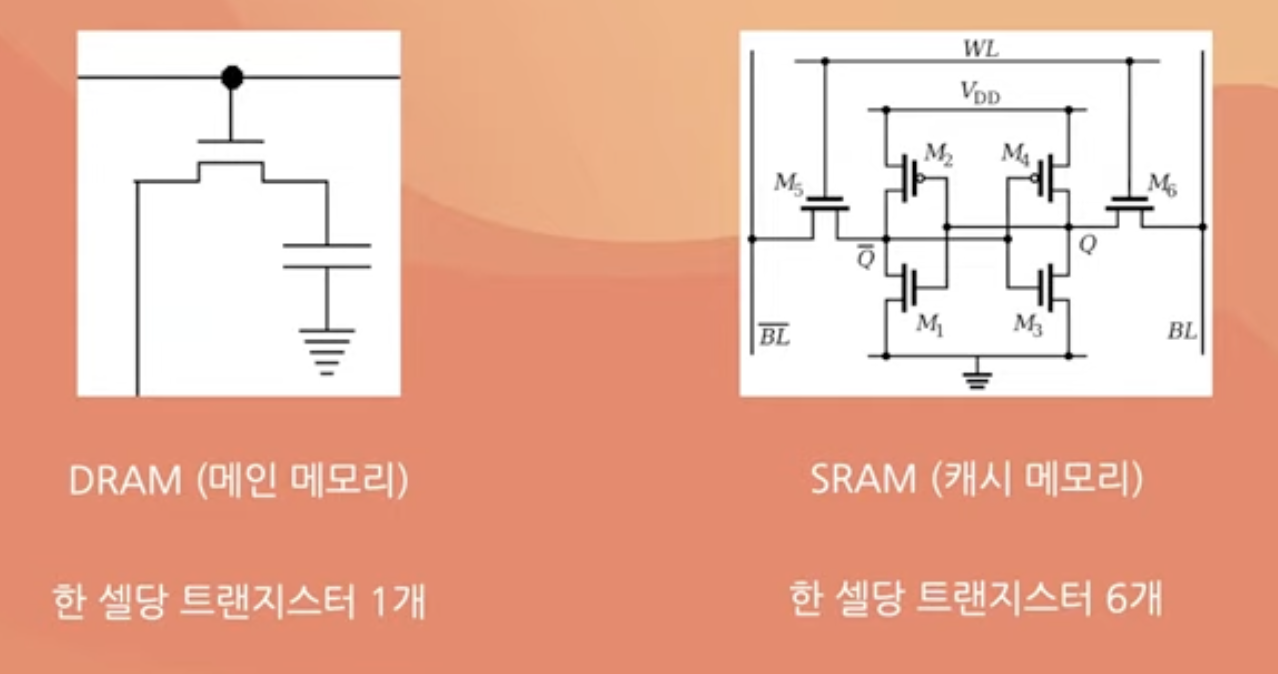
한 눈에 봐도 캐시 메모리가 비싸보인다.
메인 메모리는 DRAM, 캐시 메모리는 SRAM의 구조를 가지는데 한 메모리 셀당 트랜지스터 갯수가 다르다.
DRAM은 한 개, SRAM은 여섯 개,,,
물리적으로 차지하는 면적도 SRAM이 더욱 크다고 한다.
사람들이 안 하는데에는 모두 이유가 있다,,!
메모리 계층 구조
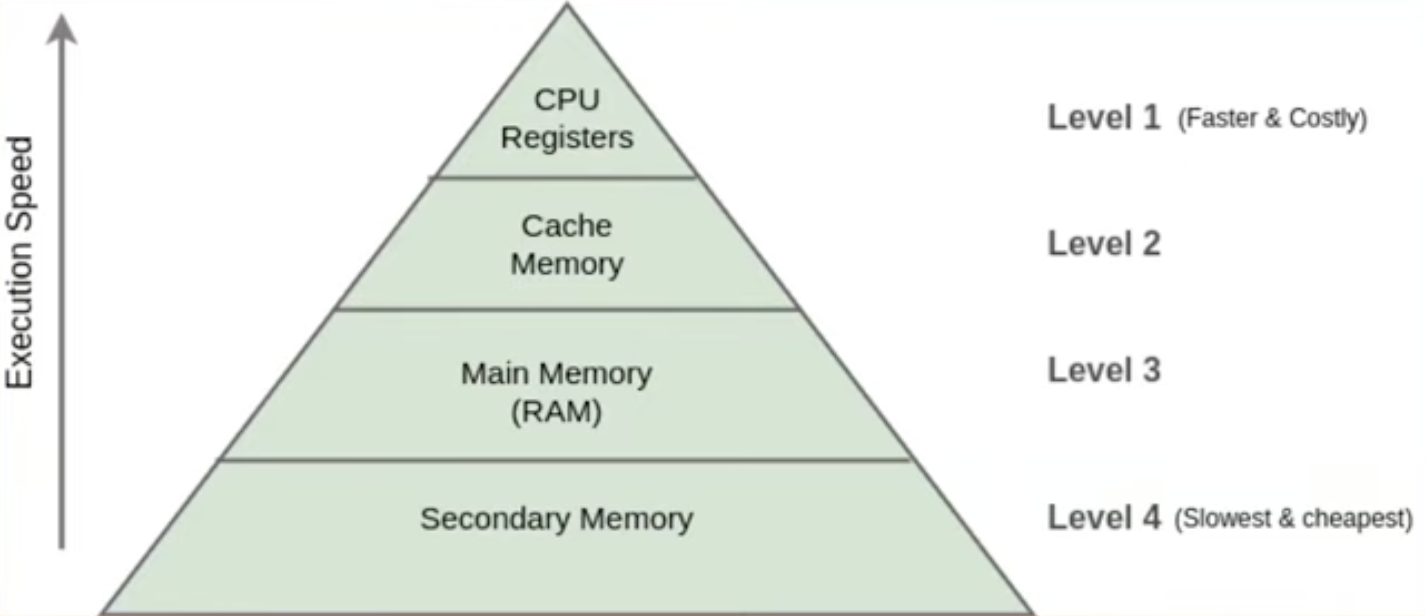
캐시 메모리를 포함한 메모리 계층은 위와 같다.
위의 있을수록 빠르고 비싸고 작은 용량을 가지며 CPU와 가까이에 위치하고 있다.
지금까지 캐시 메모리 위주로 얘기했지만 캐싱은 CPU와 RAM 사이에서만 사용되는 것은 아니다.
한 개체는 바로 아래 계층에 대하여 캐싱 작업을 수행한다.
CPU가 캐시 메모리를 캐싱하고
캐시 메모리가 RAM을 캐싱하고
메인 메모리도 하드 디스크를 캐싱한다.
결국 이러한 메모리 계층 구조의 목적은
캐싱을 이용하여 빠르고 작은 메모리와 크고 느린 메모의 장점을 조합해서 빠른 메모리처럼 행동하도록 만드는 것이다.
캐시 동작 원리
재사용 할 가능성이 클 것으로 예상되는 데이터?
앞에서 재사용 할 가능성이 클 것으로 예상되는 데이터에 복사본에 저장함으로써 캐싱을 사용할 수 있다고 했다.
그렇다면 재사용 할 가능성이 클지는 어떻게 알까?
바로 데이터 지역성의 원리를 이용한다.
데이터 지역성의 원리
데이터 지역성의 원리란 데이터 접근이 시간적 혹은 공간적으로 가깝게 일어나는 것을 의미한다.
앞에서 봤던 메모리 계층 구조의 핵심이 캐싱인데, 캐싱의 핵심 원리는 데이터 지역성원리이니 메모리 계층 구조의 핵심이라고 할 수도 있다.
자세히 알아보자.
시간적 지역성
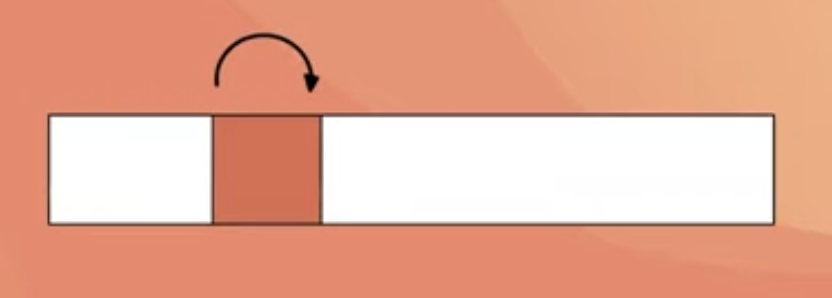
- 특정 데이터가 한 번 접근되었을 경우, 가까운 미래에 또 한 번 데이터에 접근할 가능성이 높은 것
- 메모리 상의 같은 주소에 여러 차례 읽기, 쓰기를 수행할 경우 상대적으로 작은 크기의 캐시를 사용해도 효율성을 높일 수 있다.
공간적 지역성
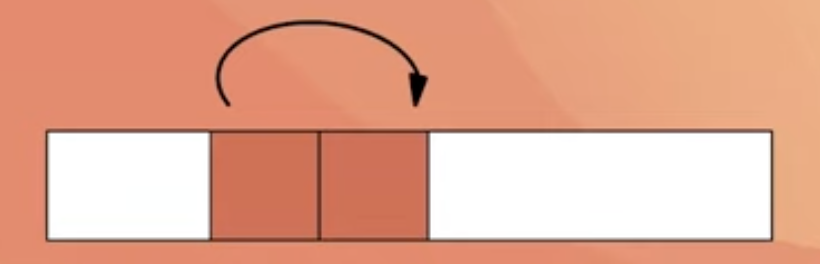
- 특정 데이터와 가까운 주소가 순서대로 접근되는 경우
- 한 메모리 주소에 접근할 때 그 주소뿐 아니라 해당 블록을 전부 캐시에 가져옴
- 이 때 메모리 주소를 오름차순이나 내림차순으로 접근한다면, 캐시에 이미 저장된 같은 블록의 데이터를 접근하게 되므로 캐시의 효율성이 크게 향상
캐시 히트와 캐시 미스
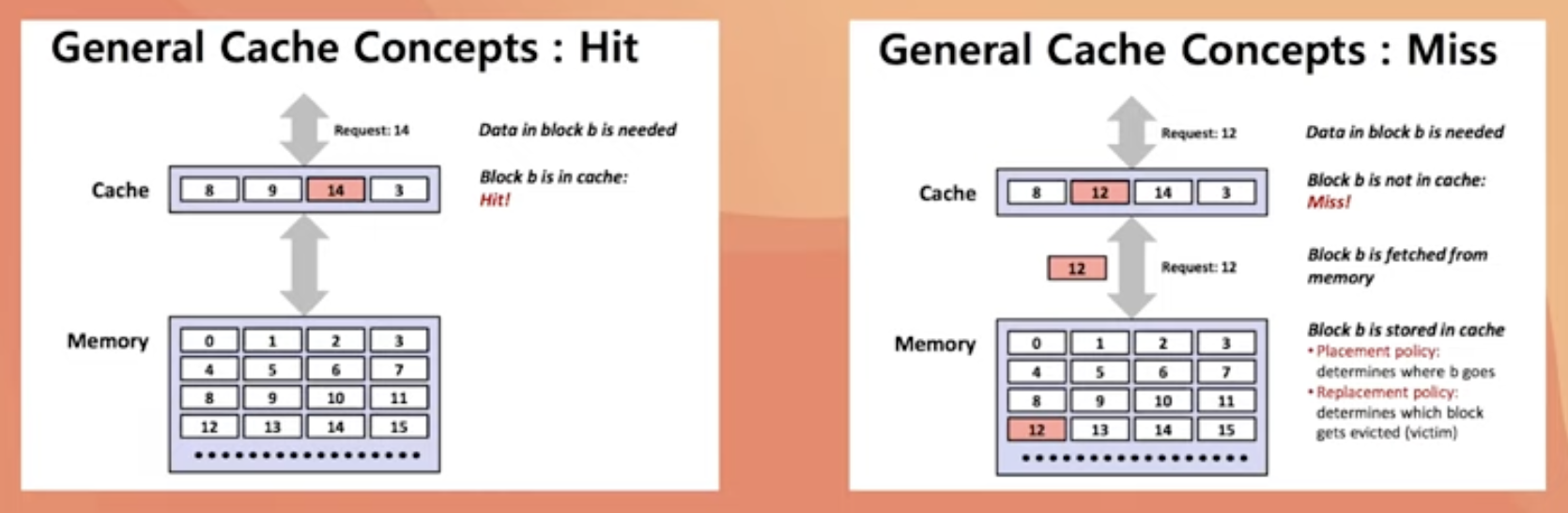
데이터 지역성의 원리를 사용해서 캐시에 데이터를 넣었다고 가정하자.
그러면 이제 CPU가 메모리에 데이터를 요청할 때 메인 메모리에 접근하기 앞서
캐시 메모리에 접근한다.
-
이 때 캐시 메모리가 해당 데이터를 가지고 있다면 캐시 히트, 또는 캐시 적중이라고 한다.
-
반면 캐시 메모리가 해당 데이터를 가지고 있지 않다면 캐시 미스라고 한다.
일반적으로 미스가 달성하면 캐싱을 하는데 히트 상태에서 데이터 쓰기 동작이 발생하면 두 가지 정책이 있다.
캐시 메모리 쓰기 정책과 캐시 일관성
이게 무슨 말이냐면 CPU에서 데이터를 읽는 동작이 아니라, 입력 하는 동작이 발생하고 데이터를 변경할 주소가 캐싱된 상태라면 메모리에 데이터가 업데이트 되는 대신 캐시의 데이터가 업데이트 된다.
따라서 메인 메모리를 업데이트 해 주어야 하는데 이 메인 메모리를 업데이트 하는 시점에 따라 정책이 두가지로 나뉜다.
Write Through 정책
메인 메모리를 바로 업데이트 하는 정책
- 단순하고 캐시와 메인 메모리의 일관성을 유지할 수 있지만, 매번 바꿔줘야 되므로 느리다는 단점이 존재한다.
Write Back 정책
캐시만 업데이트 하다가 업데이트 된 데이터가 캐시에서 빠지게 될 때 메인 메모리를 업데이트 하는 정책
- 속도가 빠르지만 캐시와 메모리가 서로 값이 다른 경우가 발생할 때가 있다.
- 데이터가 변경됐는지 확인하기 위해 캐시 블록마다 dirty 비트를 추가해야 하며 데이터가 변경되었다면 1로 바꿔준다.
- 이 후 해당 블록이 교체될 때 dirty 비트가 1이라면 메모리의 데이터를 변경하는 방식
위의 기법뿐만 아니라 캐시 일관성을 지키기 위한 여러 기법이 존재한다고 한다.
결론
캐싱 : 데이터나 리소스를 미리 저장해두어서, 다음에 같은 요청이 오면 저장해둔 데이터를 반환하여 빠른 응답 속도를 제공하는 기술
- 데이터에 직접적으로 접근하는 데 걸리는 시간이 오래 걸릴 때
- 필요한 값을 얻기 위해 계산하는 과정을 생략하고 싶을 때
- 반복적으로 동일한 결과를 돌려주는 경우
캐싱은 복사본을 이용하는 것이다.
복사본과 원본이 달라지는 경우가 생길 수 있으니 일관성 유지에 유의하자.
