1) VPN: Learning Video-Pose Embedding for Activities of Daily Living
논문 원문: https://arxiv.org/pdf/2007.03056.pdf
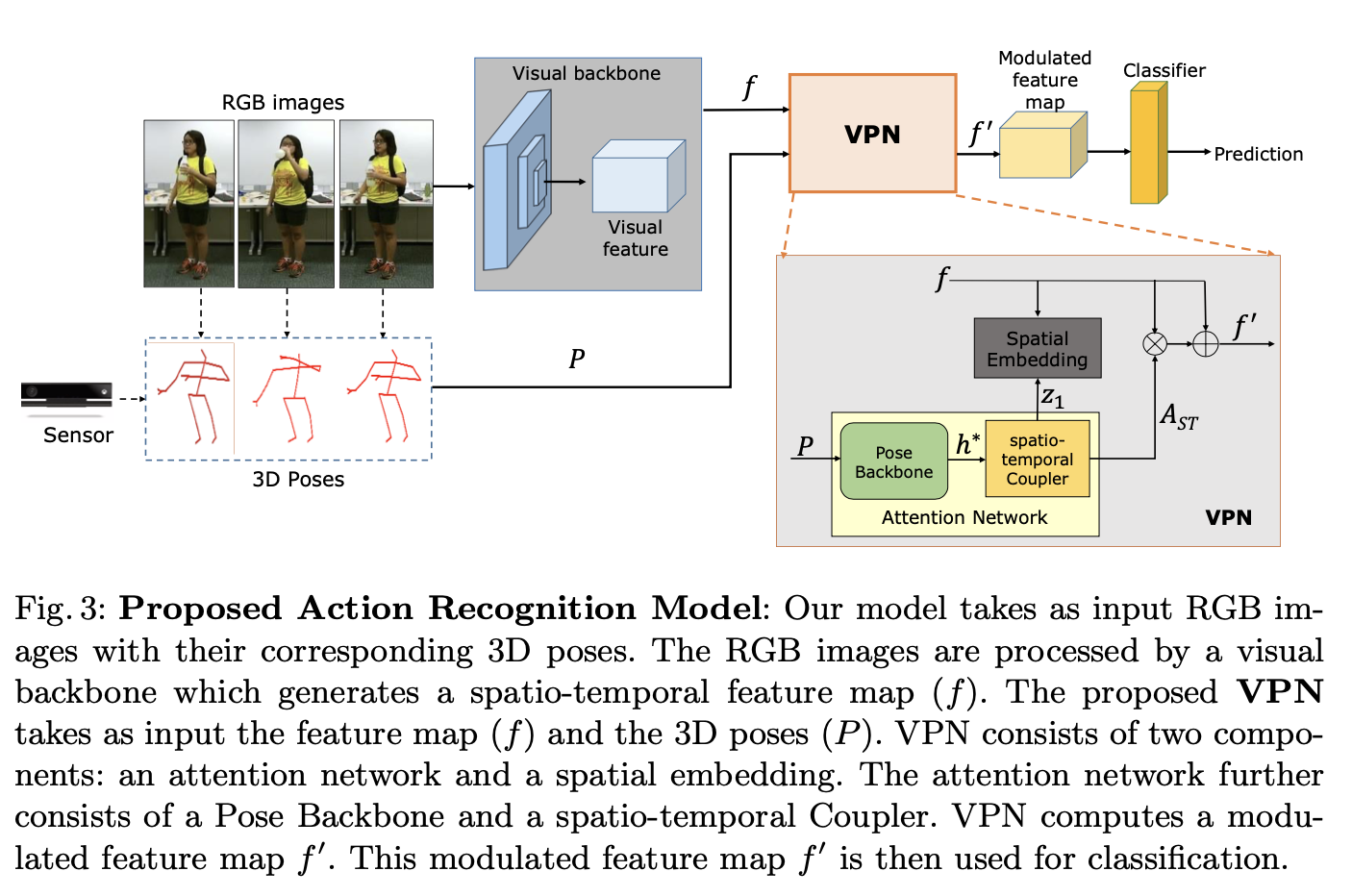
VPN: 3DConvNet의 top layer로 plugged in 되어서 활용됨.
VPN 구성 요소
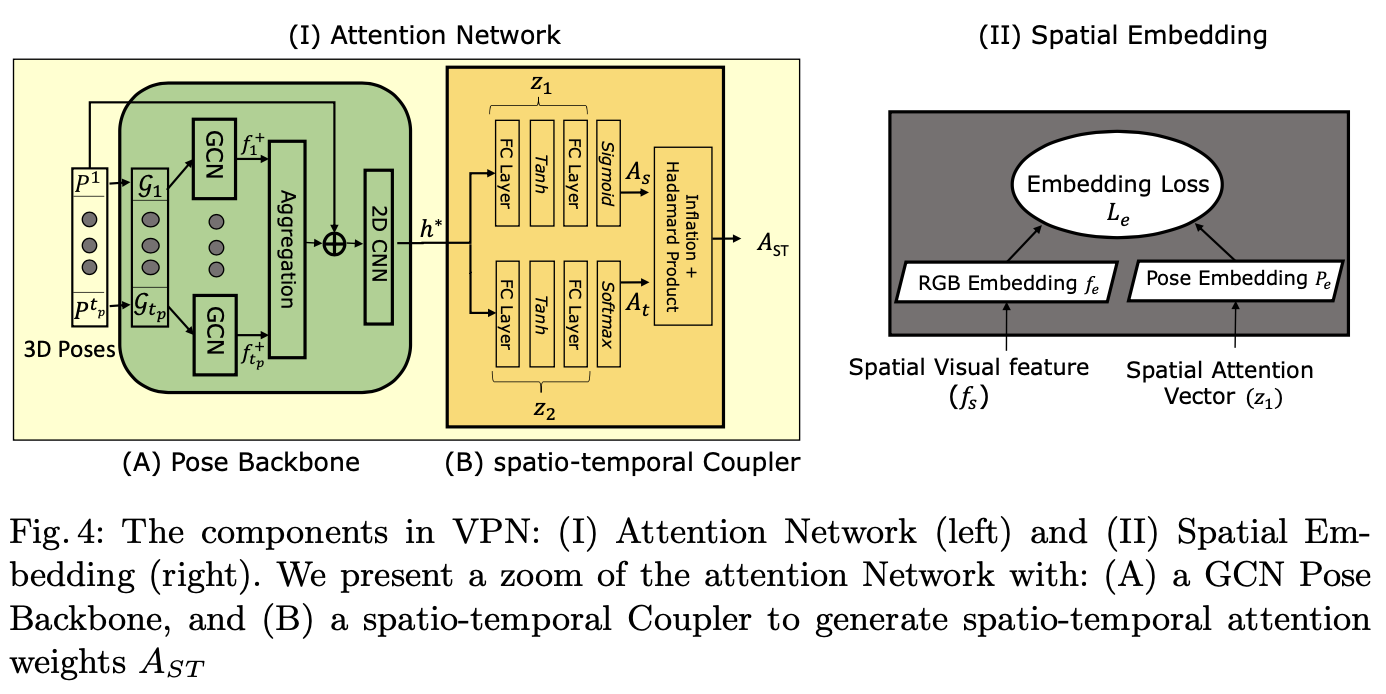
- Attention Network
-
Pose Backbone: 3D Poses를 Graph로 만들어서 GCN에 넣어서 3D Pose의 feature h* 추출
input: 3P Pose
output: h*
-
spatio-temporal coupler: 3D Poses의 공간적인 특성과 시간적인 특성에 대한 attention weight 생성.
input: h*
output: Ast
-
-
Spatial Embedding
RGB image와 3P Pose사이의 correspondences 높이기 위한 embedding 학습
input: fs, z1(from stc)
training spatial embedding vector through Le
pose와 rgb 간의 correspondence 측정은 embedding space에서 mapping된 거리 측정
This is a first step towards combining RGB and Pose through an explicit embedding.
→ 동작이 비슷해서 헷갈리는 동작들을 정확하게 인식하기 위해서!
2) VPN++: Rethinking Video-Pose embeddings for understanding Activities of Daily Living
논문 원문: https://arxiv.org/pdf/2105.08141.pdf
https://github.com/srijandas07/vpnplusplus
VPN Accuracy 비교
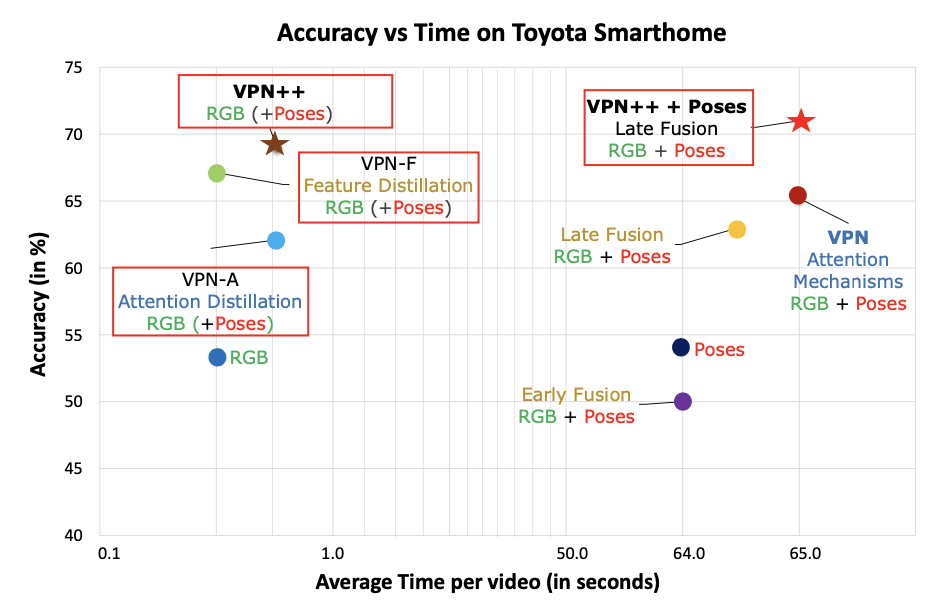
- VPN++를 하는 이유: 기존의 VPN이 성능은 좋은데 너무 느림
- VPN-F와 VPN-A를 개발하고 이 둘을 합쳐서 VPN++를 만듦. → VPN++ = VPN-F + VPN-A
- VPN++는 training할 때 RGB와 Pose를 사용하고 test할 때는 RGB만 넣어서 VPN보다 속도를 빠르게 함!
- VPN++에 input에 Pose도 같이 넣는 것은 VPN++보다 정확도가 조금 높아지는 것에 비해 시간이 거의 100배 가까이 걸리기 때문에 VPN++이 effective함!
VPN, VPN-F, VPN-A, VPN++
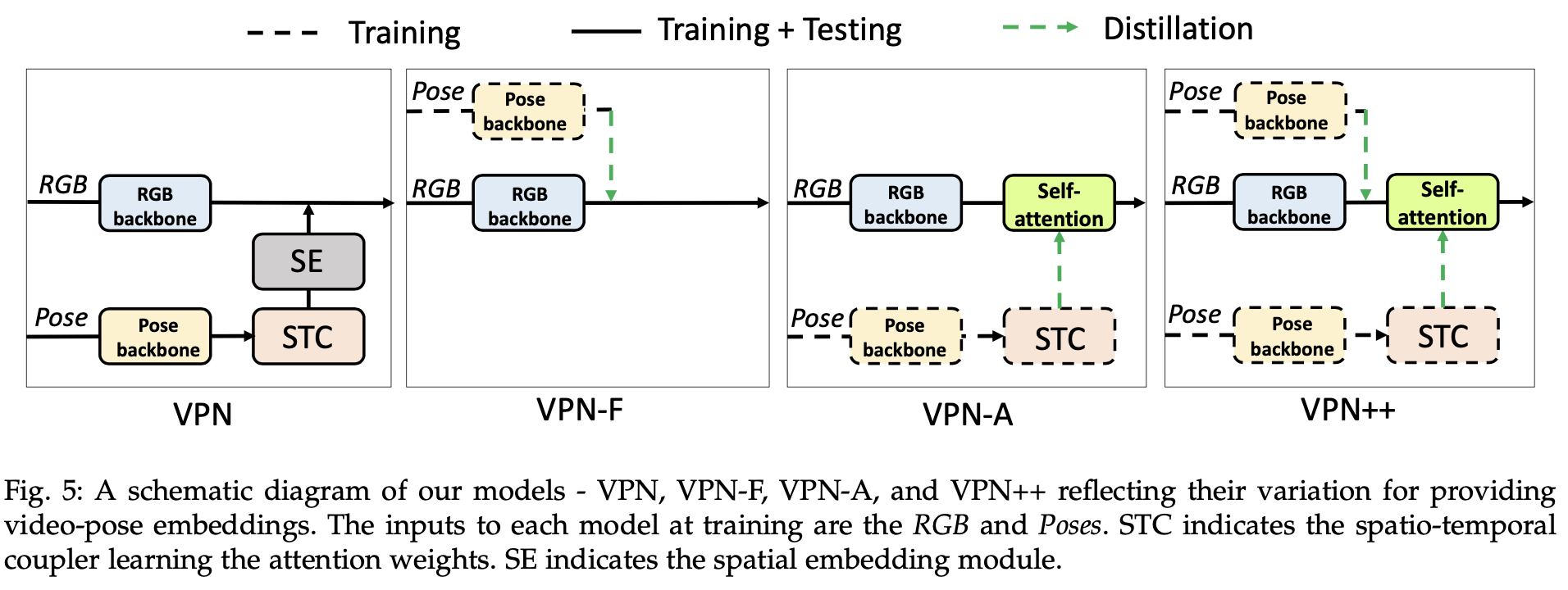
1. VPN
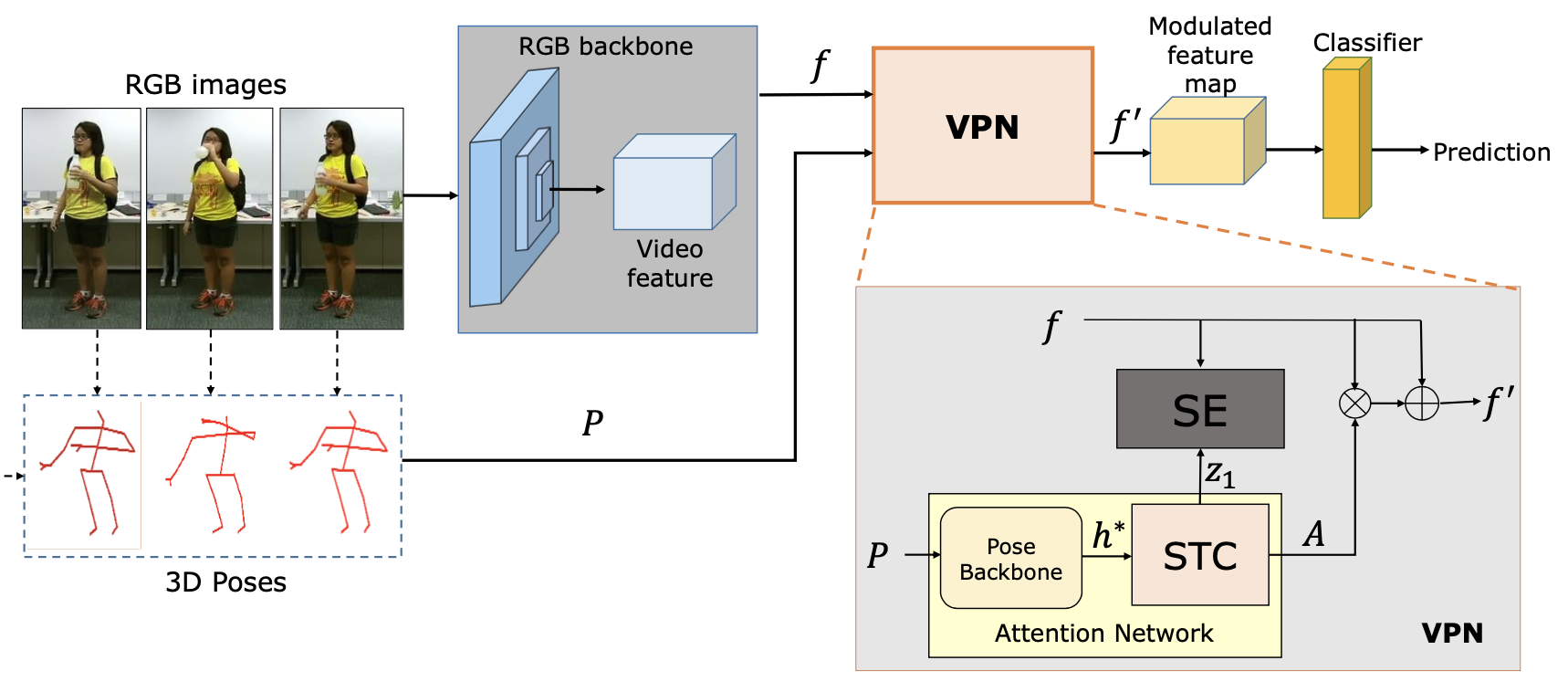
- RGB backbone(i3d)
- Pose backbone(GCN)
- STC
- SE
2. VPN-F
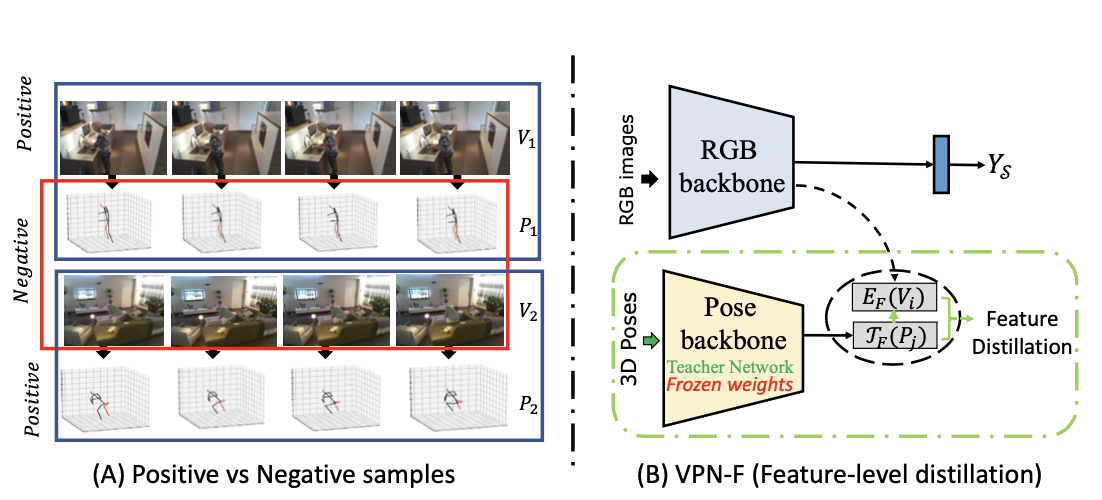
- Teacher-Student Network
- Contrastive Learning
- SE, STC x
→ Contrastive Learning을 통해 RGB 이미지와 3D Pose pair의 correspondence를 학습. (SE x)
→ training시에 Pose feature들을 학습시켜서 student network인 RGB backbone에 넘겨줌
3. VPN-A
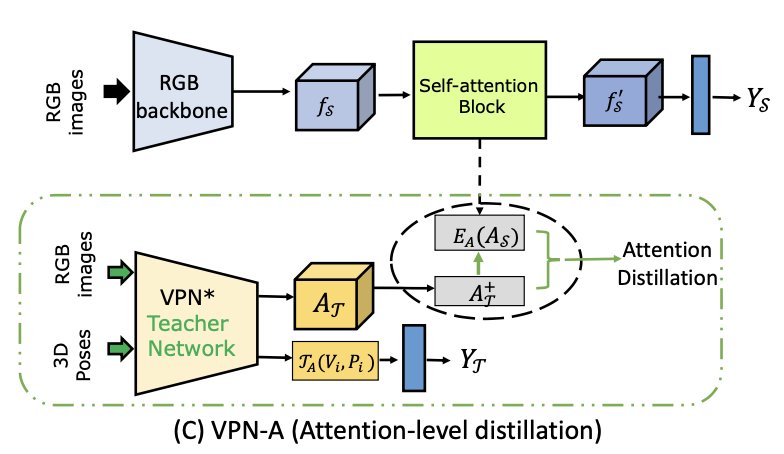
- Teacher-Student Network
- Self-attention Mechanism
- Collaborative Learning
- VPN* (w/o SE)
→ 기존 VPN에서 Attention Network가 하는 일을 함
→ Attention weight들을 학습히켜서 Student Network인 Self-attention block에 넘겨줌 (VPN의 STC에서 뱉어내는거랑 같은 웨이트들)
→ VPN teacher network is trained with action labels to learn pose driven attention weights At to modulate its RGB feature map. (Ltc)
→ VPN*가 뱉은 At 랑 self attention block의 As의 MSE로 Loss 설정 (Ld)
4. VPN++
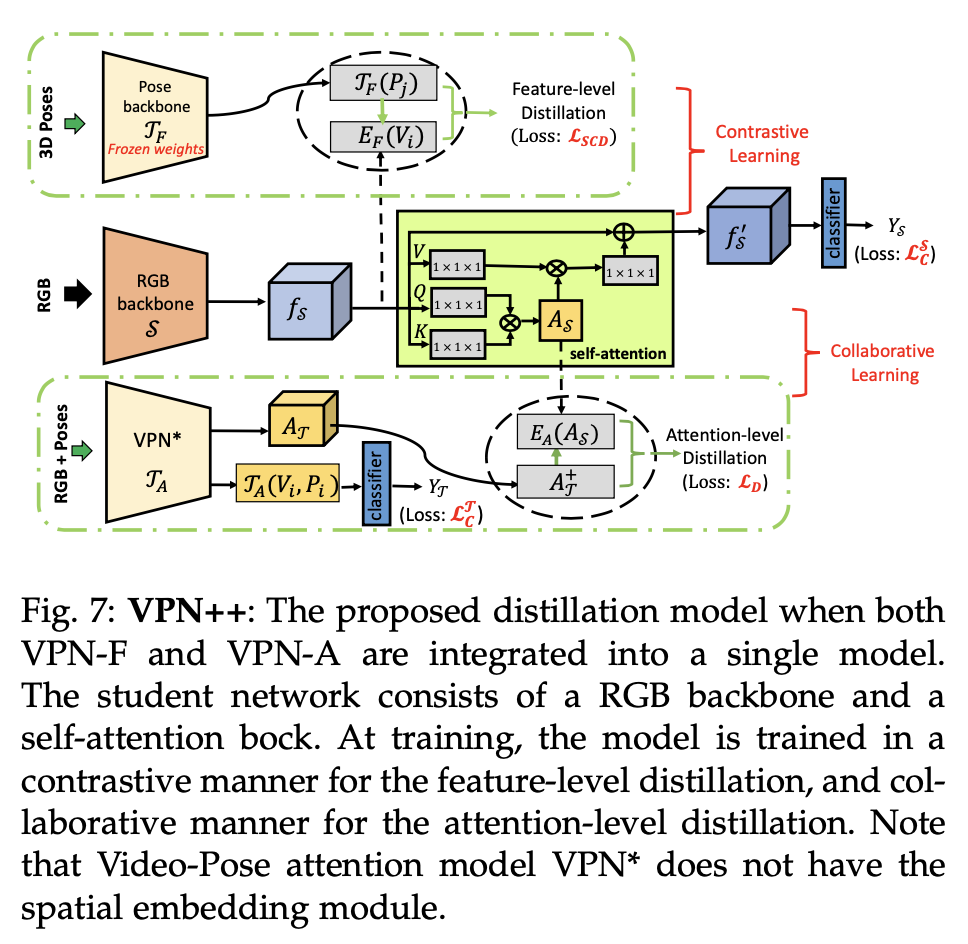
- VPN-F + VPN-A
- (positive, negative) pairs: feature-level distillation
- (positive, positive) pairs: attention-level distillation
- 최종 Loss
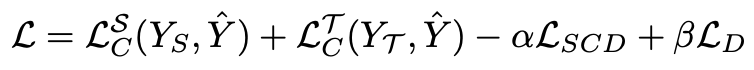 → alpha, beta는 weighting factors
→ alpha, beta는 weighting factors
- testing시에는 only use RGB frames as input to compute action classes scores, avoiding the requirement of 3D poses
→ 3D poses는 시간 너무 오래걸려서 뺌
Experiments
- dataset 특이 사항
- Toyota Smarthome(SH): kinetic 안써서 3D skeletons는 LCRNet으로 추출함
- training time
- Teacher network for VPN-F: AGCN-J를 Pose backbone으로 사용
- Teacher network for VPN-A: VPN*(SE없는 VPN) + 2 layer AGCN 를 Pose backbone으로 사용
- Student network: I3D RGB backbone pretrained on ImageNet and Kinetics-400
- input: 64 RGB frames
- self-attention block: additional Non-Local block 을 I3D top에 붙여서 구현
- test time
- fully convolutional → final classification by max-pooling the softmax scores
- only use RGB images
