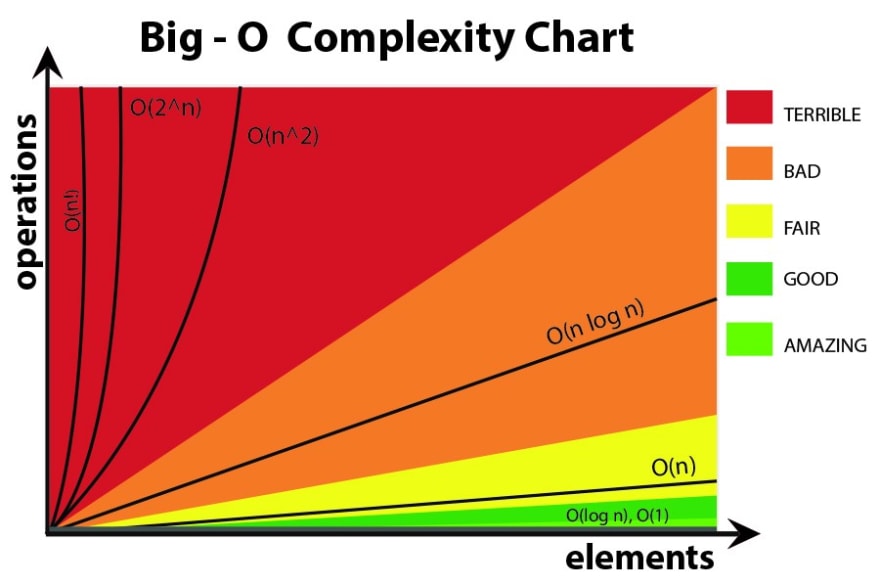
Big O 시간복잡도
이전에 업로드한 시간복잡도에 대한 나의 생각은 아주 지극히 개인적은 나의 생각이였다. 하지만, 이번에는 시간복잡도에 대해서 제대로 공부해보자!
시간 복잡도를 한마디로 정리하자면 아래와 같이 말할수있다.
입력값의 변화에 따라 연산을 실행할 때, 연산 횟수에 비해 시간이 얼마만큼 걸리는가?
효율적인 알고리즘을 구현한다는 것은 시간복잡도를 생각하며 입력값이 커짐에 증가하는 시간의 비율을 최소화한 알고리즘을 구성했다는 이야기이다.
지금까지 백준문제를 풀면서 시간복잡도에 대해서 감을 잡게 된 내용은 쉽게 풀어서 1부터 10까지 2씩 곱한뒤 모두 다 더하는 로직을 일일이 12+22+32+...92+10*2 보다는 1부터 10까지 더한 값에 2를 곱하는것이 더 효율적이라는 방법이라고 볼수있다. 컴퓨터는 어떠한 행동을 할때마다 시간이 조금이라도 걸린다고 보면된다. 우린 최대한 그 행동을 적게하게끔 로직을 짜주면된다.
Big-O 표기법
시간 복잡도를 표기하는 방법은 다음과 같다.
1. Big-O(빅-오)
2. Big-Ω(빅-오메가)
3. Big-θ(빅-세타)
위 세가지 표기법은 시간 복잡도를 각각 최악, 최선, 중간(평균)의 경우에 대하여 나타내는 방법이다.
하지만, 이중에서는 Big-O표기법이 가장 자주 사용된다.
빅오 표기법은 최악의 경우를 고려하므로, 프로그램이 실행되는 과정에서 소요되는 최악의 시간까지 고려할 수 있기 때문이다.
"최소한 특정 시간 이상이 걸린다" 혹은 "이 정도 시간이 걸린다"를 고려하는 것보다 "이 정도 시간까지 걸릴 수 있다"를 고려해야 그에 맞는 대응이 가능하다.
Big-O 표기법의 종류
O(1)
Big-O 표기법은 입력값의 변화에 따라 연산을 실행할 때, 연산 횟수에 비해 시간이 얼마만큼 걸리는가?를 표기하는 방법이다. O(1)는 constant complexity라고 하며, 입력값이 증가하더라도 시간이 늘어나지 않는다. 다시 말해 입력값의 크기와 관계없이, 즉시 출력값을 얻어낼 수 있다는 의미이다.
int a = 3;
System.out.println(a);
int [] arr = {1,2,3,4,5,6,7,8,9};
System.out.println(arr[3]);위 코드처럼 설령 배열내부에 1,000,000개의 데이터가 있다 하더라도 O(1)의 복잡도를 갖는다.
O(n)
O(n)은 linear complexity라고 부르며, 입력값이 증가함에 따라 시간 또한 같은 비율로 증가하는 것을 의미한다.
예를 들어 입력값이 1일 때 1초의 시간이 걸리고, 입력값을 100배로 증가시켰을 때 1초의 100배인 100초가 걸리는 알고리즘을 구현했다면, 그 알고리즘은 O(n)의 시간 복잡도를 가진다고 할 수 있다.
예시로는 1중 for문을 예시로 들을 수 있다.
만약 로직에서 1중 for문을 2번 사용했다면, 표기법은 2 O(n)이 된다. 하지만, 몇배로 증가하더라고 O(n)으로 표기한다.
O(log n)
O(log n)은 logarithmic complexity라고 부르며 Big-O표기법중 O(1) 다음으로 빠른 시간 복잡도를 가진다.
자료구조에서 Binary Search Tree가 이 O(log n)의 복잡도를 갖는다.
2진 탐색트리는 노드를 이동할때마다 경우의 수가 절반으로 줄어든다.
O(n^2)
O(n^2)은 quadratic complexity라고 부르며, 입력값이 증가함에 따라 시간이 n의 제곱수의 비율로 증가하는 것을 의미한다. 예시로는 2중 for문을 예시로 들을 수 있으며, O(n)과 마찬가지로 O(n^3)이나 O(n&=^5) 모두 O(n^2)으로 표기한다.
O(2^n)
O(2^n)은 exponential complexity라고 부르며 Big-O 표기법 중 가장 느린 시간 복잡도를 갖는다.
O(log n)복잡도 같은 경우는 선택할때마다 경우의 수가 절반으로 줄어들었지만, O (2^n)복잡도는 그 반대로 경우의 수가 2배씩 들어난다고 보면된다. 예시로는 재귀로 구현하는 피보나치 수열이 O(2^n)복잡도를 갖는다.
시간복잡도를 구하는 요령
각 문제의 시간복잡도 유형을 빨리 파악할 수 있도록 아래 예를 통해 빠르게 알아 볼수 있다.
- 하나의 루프를 사용하여 단일 요소 집합을 반복 하는 경우 : O (n)
- 컬렉션의 절반 이상 을 반복 하는 경우 : O (n / 2) -> O (n)
- 두 개의 다른 루프를 사용하여 두 개의 개별 콜렉션을 반복 할 경우 : O (n + m) -> O (n)
- 두 개의 중첩 루프를 사용하여 단일 컬렉션을 반복하는 경우 : O (n²)
- 두 개의 중첩 루프를 사용하여 두 개의 다른 콜렉션을 반복 할 경우 : O (n * m) -> O (n²)
- 컬렉션 정렬을 사용하는 경우 : O(n*log(n))
추가적인 알고리즘 문제 풀때의 시간 복잡도
알고리즘은 얼마나 효율적인 시간복잡도로 답을 유추해내는가에 문제이다.
따라서 입력 데이터가 끌 때는 O(n) 혹은 O(log n)의 시간 복잡도를 만족할 수 있도록 예측해서 문제를 풀어야한다.
대략적인 데이터 크기에 따른 시간 복잡도는 다음과 같다.
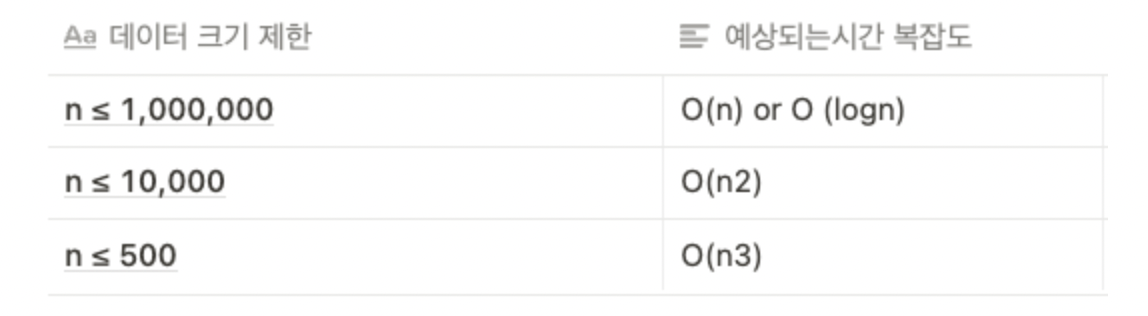
한가지 더 얘기를 하자면, 우리가 for문안에 정렬이나, 다른 메소드를 사용한다면 1중 for문이라해도 2중 for문의 시간 복잡도를 갖게 된다. 이유는 입력값에 따라서 해야하는 일이 2개씩 있기 때문이다. 꼭 알아두고 나중에 1중 for문인데 왜 시간초과가 걸리지? 이러한 상황을 예방하자.
