데이터베이스
데이터베이스의 목적은 많은 양의 정보들을 CRUD하기 편리하게 사용하기 위해서 사용한다.
- Create
- Read
- Update
- Delete
우리가 엑셀시트를 사용하여 행과 열에 따라서 정보를 구분짓듯이 관계형 데이터 베이스에서도 행과 열로 정보를 구분지어 관리하기에 편하게 사용한다.
하지만, 왜 굳이 데이터 베이스를 사용할까?
- 데이터가 필요할 때마다 전체 파일을 매번 읽어야 한다. 파일의 크기가 커질수록 이 작업은 버겁고, 비효율적이어서 File I/O 방식의 큰 단점이다.
- 파일이 손상되거나 여러 개의 파일들을 동시에 다뤄야 하거나 하는 등 복잡하고 데이터량이 많아질수록 데이터를 불러들이는 작업이 점점 무거워진다.
이 두가지 이유로도 충분히 엑셀시트를 이용하지 않음이 설명된다.
우리는 무수히 많은 정보를 처리하여 클라이언트에게 정보를 보내주어야한다.
관계형 데이터베이스 (SQL Database)
이전 데이터베이스가 처음 나왔을때 데이터베이스의 종류는 모두 관계형 데이터베이스라고 해도 과언이 아니였다. 관계형 데이터베이스는 행(row)과 열(column)로 구성된 테이블에 데이터를 저장한다. 각 열은 하나의 속성에 대한 정보를 저장하고, 행에는 각 열의 데이터 형식에 맞는 데이터가 저장된다. 특정한 형식을 지키기 때문에, 데이터를 정확히 입력했다면 데이터를 사용할 때에는 매우 수월하다. 형식에 맞는 데이터가 저장되므로 중요한 정보들을 관리하기에 매우 적합했다. 하지만 SNS처럼 데이터의 구조가 거의 또는 전혀 없는 대용량의 데이터를 저장하는 경우 관계형 데이터의 이점들이 사라지기에 비관계형 데이터 베이스들이 탄생하기 시작했다.
비관계형 데이터베이스 (No SQL Database)
비관계형 데이터베이스의 큰 특징으로는 데이터베이스는 저장할 수 있는 데이터의 유형에 제한이 없고, 필요에 따라서 언제든지 데이터의 새 유형을 추가할 수 있다.
즉,동적으로 스키마의 형태를 관리할 수 있으며 행을 추가할 때 즉시 새로운 열을 추가할 수 있고, 개별 속성에 대해서 모든 열에 대한 데이터를 반드시 입력하지 않아도된다.
그러므로 빠르게 서비스를 구축하는 과정에서 데이터 구조를 자주 업데이트 하는 경우사용한다면, 확실한 이점으로 자리잡을수있다.
SQL과 No SQL 차이점
-
데이터 저장(Storage)
NoSQL은 key-value, document, wide-column, graph 등의 방식으로 데이터를 저장한다.
관계형 데이터베이스는 SQL을 이용해서 데이터를 테이블에 저장한다. 미리 작성된 스키마를 기반으로 정해진 형식에 맞게 데이터를 저장해야 한다. -
스키마(Schema)
SQL을 사용하려면, 고정된 형식의 스키마가 필요한다. 다시 말해, 처리하려는 데이터 속성별로 열(column)에 대한 정보를 미리 정해두어야 한다. 스키마는 나중에 변경할 수 있지만, 이 경우 데이터베이스 전체를 수정하거나 오프라인(down-time)으로 전환할 필요가 있다.
NoSQL은 관계형 데이터베이스보다 동적으로 스키마의 형태를 관리할 수 있다. 행을 추가할 때 즉시 새로운 열을 추가할 수 있고, 개별 속성에 대해서 모든 열에 대한 데이터를 반드시 입력하지 않아도 된다. -
쿼리(Querying)
쿼리는 데이터베이스에 대해서 정보를 요청하는 질의문이다. 관계형 데이터베이스는 테이블의 형식과 테이블간의 관계에 맞춰 데이터를 요청해야 한다. 그래서 정보를 요청할 때, SQL과 같이 구조화된 쿼리 언어를 사용한다.
비관계형 데이터베이스의 쿼리는 데이터 그룹 자체를 조회하는 것에 초점을 두고 있다. 그래서 구조화 되지 않은 쿼리 언어로도 데이터 요청이 가능하다. UnQL(UnStructured Query Language)이라고 말하기도 한다. -
확장성(Scalability)
일반적으로 SQL 기반의 관계형 데이터베이스는 수직적으로 확장한다. 높은 메모리, CPU를 사용하는 확장이라고도 한다. 데이터베이스가 구축된 하드웨어의 성능을 많이 이용하기 때문에 비용이 많이 든다. 여러 서버에 걸쳐서 데이터베이스의 관계를 정의할 수 있지만, 매우 복잡하고 시간이 많이 소모된다.
NoSQL로 구성된 데이터베이스는 수평적으로 확장한다. 보다 값싼 서버 증설, 또는 클라우드 서비스 이용하는 확장이라고도 한다. NoSQL 데이터베이스를 위한 서버를 추가적으로 구축하면, 많은 트래픽을 보다 편리하게 처리할 수 있다. 그리고 저렴한 범용 하드웨어나 클라우드 기반의 인스턴스에 NoSQL 데이터베이스를 호스팅할 수 있어서, 수직적 확장보다 상대적으로 비용이 저렴하다.
예시
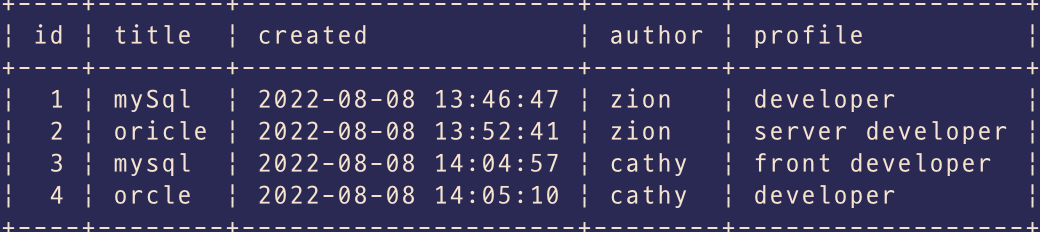
위 사진은 MySQL을 이용하여 테이블을 만들고 그안에 데이터들을 집어넣은 모습이다.
데이터베이스는 위에서 말했듯 CURD를 위한것이다. 따라서 데이터를 필터링하여 원하는 갯수만큼 가져오거나, title에서 mysql을 사용하는 데이터들만을 불러오거나 할수있다.
앞으로 알아봐야 하는 내용
-
데이터들을 내림차순으로 zion작가의 데이터들만을 불러와서 그중 profile이 server developer인 것만을 필터링 하는 방법을 알아보자.
-
위 사진보다 더많은 데이터를 가지고 있는 상황에서 limit를 10개로 지정하여 데이터를 확인해보고 그이후 11번째 데이터부터 20번째 데이터까지 가져오도록하는 페이징 기술을 알아보자.
