반정규화 (De-Normalization)
반정규화란 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙을 위배하는 행위이다.
- 반정규화를 수행하면 시스템의 성능이 향상되고 관리 효율성을 증가하지만 데이터의 일관성 및 정합성이 저하될 수 있음
- 과도한 반정규화는 오히려 성능을 저하시킴
- 반정규화를 위해서는 사전에 데이터의 일관성과 무결성을 우선으로 할지, 데이터베이스의 성능과 단순화를 우선으로 할지를 결정해야 함
- 반정규화 방법에는 테이블 통합, 테이블 분할, 중복 테이블 추가, 중복 속성 추가 등이 있음
정규화와 반정규화는 Trade off 관계에 있다.
정규화
정규화를 하면 정합성과 데이터무결성이 보장된다.
반면, 테이블이 복잡해지고 성능이 떨어질 수 있다.
그에 따라 입력(Create), 수정(Update), 삭제(Delete)의 성능은 향상되고 조회(Read)의 경우 나빠질수도 있고 좋아질 수도 있다.
반정규화
반 정규화를 하면 테이블이 단순화되며 성능이 향상되는 반면,
정합성과 데이터무결성이 보장되지 않을 수있다.
반 정규화는 의도적으로 중복을 만들어 검색(Read) 성능을 향상시킨다.
하지만 속성이 각기 다른 테이블에 중복되어 나타나기 때문에 입력(Create), 수정(Update), 삭제(Delete)의 성능은 낮아진다.
애플리케이션 레벨에서 꼭 해당 속성에 포함된 모든 테이블에 트랜잭션을 보내야 한다.
본격적인 반 정규화 방식에 대해 이야기 하기 전에
디지털 디바이스(하드웨어)의 성능을 어떤식으로 보장해 주어야하는지 알아보자.
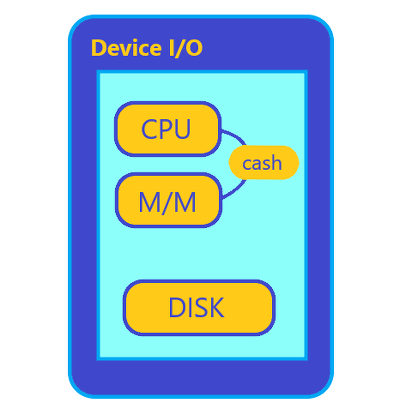
디스크와 메모리(M/M), CPU 큰 속도와 가격 차이를 가지고 있다.
CPU는 연산을 수행하며 가장 빠르고 비싸다.
디스크는 가장 큰 저장공간을 가지고 있고 느리다.
디스크와 CPU는 1만배 이상의 속도 차이를 가지고 있다.
이를 보완하기 위해 메모리가 중간에 자리잡고 있는데, 디스크가 장기기억장소라면 메모리는 단기기억장소이다. (메모리와 CPU의 속도차이도 커서 캐시라는 비싼 메모리를 그 간극을 보완한다.)
메모리는 한 트랜잭션에 필요한 데이터를 디스크에서 가져와 CPU 연산작업을 하는 기간동안 저장해놓는다. 디스크에서 메모리로 데이터를 퍼오는 횟수를 줄일수록 (속도)를 향상시킬 수 있다.
데이터베이스(DB)는 어디에 저장될까?
당연히 장기기억매체인 디스크에 저장되며, 디스크에서 메모리로 데이터를 퍼오는 횟수를 줄이려는 노력이 반정규화이다.
테이블 반정규화 방법
1. 테이블 병합
-
1:1관계의 테이블 병합
- 병합했을 때 이행적 종속이 발생하더라도, 자주 변경(Update)되는 정보가 아니며 같이 조회(Read)되는 경우가 많다면 통합한다.
-
1:m관계의 테이블 병합
-
수퍼타입 서브타입 테이블 병합
2. 테이블 분할
-
수직 분할 (column 단위)
- 한 엔터티(테이블)에서 집중화된 일부 항목들을 다른 엔터티로 분리한다
-
수평 분할 (recode 단위):
-
프로세스가 구간별(e.g 월별)로 발생하는 한 엔터티(테이블)를 구간별 엔터티로 분할한다.
-
구간별로 엔터티를 분할하면 데이터베이스(DB)의 성능은 향상되나 코드를 짤 때는 비효율적이다. 그래서 근래 DBMS에는 파티셔닝이라는 기능을 통해 테이블을 논리적으로는 1개인 테이블을 물리적으로는 N개로 쪼개서 저장할 수 있게 해준다.
-
3. 테이블 추가
중복 테이블, 집계 테이블, 이력 테이블, 부분 테이블 추가
- 중복원리에 의해 조회(Read)성능이 향상된다.
컬럼의 반정규화 방법
-
중복 컬럼 추가
이미 테이블 C에서 테이블 A의 e컬럼을 조회할 수 있는 관계가 있으나, 자주 조회(Read)하는 컬럼 e를 테이블 C에도 추가하여 접근 경로를 단축시켜준다.
-
파생 컬럼 추가
-
Primary Key에 의한 컬럼 추가
-
오 입력 처리를 위한 컬럼 추가
관계의 반정규화
-
관계중복
이미 A테이블에서 C테이블의 정보를 읽을 수 있는 관계가 있음에도 관계를 중복하여 조회(Read) 경로를 단축시킨다.
