
Error
0. 사건의 전말
AWS로부터 [Amazon EC2 Maintenance: Instance scheduled for reboot] 라는 제목의 이메일을 받았다.
프리티어로 EC2와 RDS를 사용하고 있기 때문에 매달 말 사용량 alert 메일을 받아 왔기에
이번에도 그 메일인줄 알고 클릭했는데, 평소와 전혀 다른 내용의 메일이었다.
Amazon EC2 has detected degradation of the underlying hardware hosting your EC2 instance associated with your AWS account (AWS Account ID: 00000000000) in the ap-northeast-2 region. This instance is scheduled for maintenance and will be rebooted any time between 2023-04-12 02:00:00 UTC and 2023-04-12 04:00:00 UTC. ... (중략) What will happen to my instance during this maintenance event? During maintenance, the instance will be rebooted. The reboot generally takes a few minutes to complete. After the reboot, your instance retains its IP address, DNS name, and any data on local instance-store volumes. (이하 생략)
(자체 해석)
현재 사용중인 인스턴스의 물리적 하드웨어의 성능 저하가 감지되었고, 그로 인해 해당 날짜에 재부팅 될 것이다.
이 유지 관리 이벤트 중, 내 인스턴스는 재부팅 될 것이고 몇 분이면 끝날 것이다.
재부팅 후에도 IP 주소, DNS, local instance-store volumes 가 유지될 것이다.
실제 서비스가 아닌, 프로젝트 배포용으로 인스턴스를 사용 중이었기 때문에 몇 분간의 서버 다운은 전혀 문제가 없다(고 생각했다). 그렇게 아무 조치를 취하지 않은 채 4월 12일을 맞이했고... 사건이 발생했다.
1. 네트워크 에러
같이 프로젝트를 진행했던 팀장님(FE)에게 오랜만에 DM이 왔고,
Network Error 라는 문구가 뜨며 서버와의 연결이 되지 않는다는 내용이었다.
디엠을 받은 날은 4월 14일(리부팅 2일 후) 였고
- 정식 배포 후 4달 넘게 서버 문제 없었음.
- 배포한 서비스를 매일 확인하는 사람은 (아마) 없기 때문에, 12일 이후 누군가 배포 링크를 처음 방문했을 것.
바로 리부팅으로 인한 이슈일 거라는 생각이 들었다.
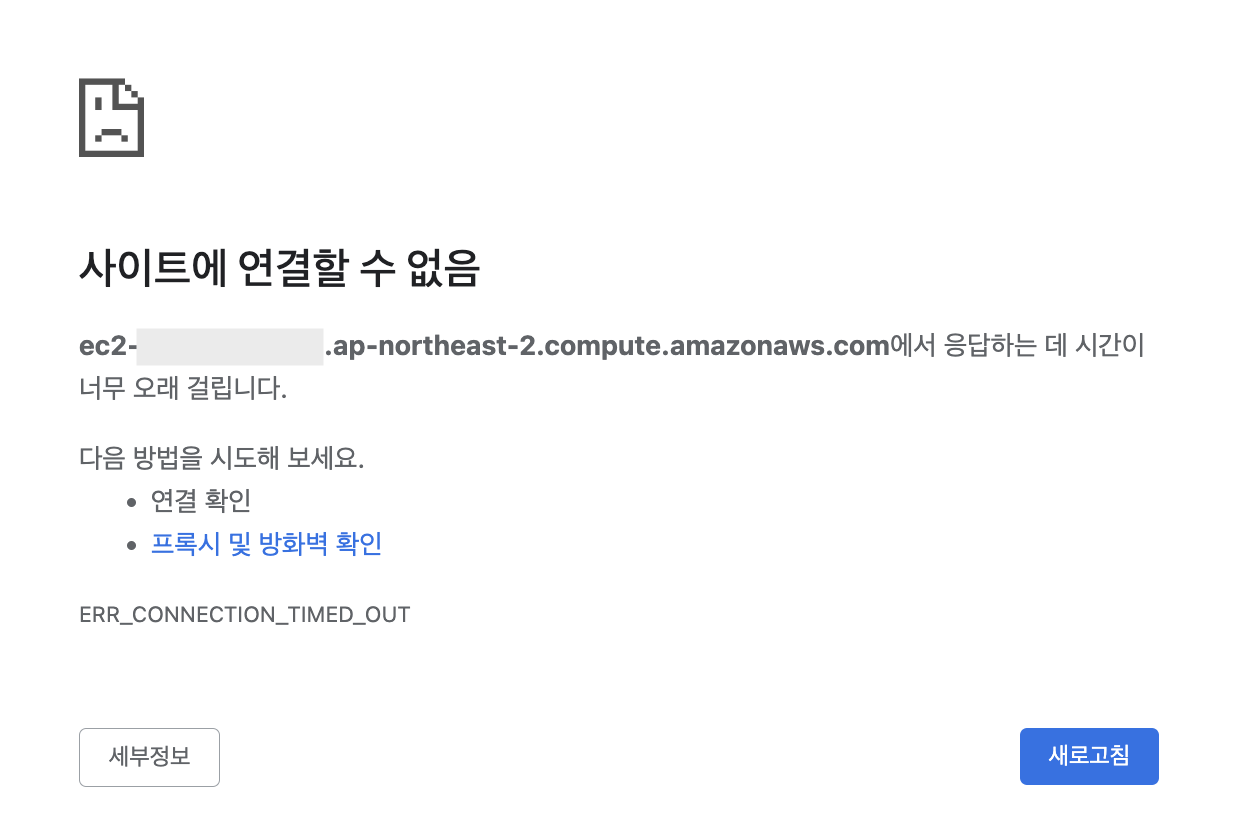 응답하는 데 시간이 너무 오래 걸립니다 .png
응답하는 데 시간이 너무 오래 걸립니다 .png
직접 확인해보니 역시나 연결이 되지 않았다.
ec2 인스턴스를 ssh 연결도 먹통이었다.
"ecs 인스턴스 응답하는 데 시간이 너무 오래 걸립니다", "ec2 ssh 연결안됨" 등으로 수없이 구글링을 해봐도 인스턴스 보안그룹 인바운드 규칙을 설정하라는 말이 대부분이었고, 내 인스턴스는 이미 해당 블로깅에 적혀있는 해결 완료 후의 상태와 같았다.
2. 인스턴스 연결성 검사 실패

인스턴스 세부정보 탭을 하나씩 다 눌러보다가 모니터링을 보니, cpu 사용량이 85프로를 넘어가고 있었다.
몇 분 후, 상태 검사 탭을 보니 인스턴스 연결성 검사 실패가 떠있는 걸 볼 수 있었다.
이제는 정말 인스턴스 재시작 밖에는 답이 없다는 생각이 들었고, 다른 블로그에서도 대부분 그 방법을 추천했다.
Solution
3. 인스턴스 중지 및 재시작
인스턴스 중지, 재시작은 정말 쉽다.
다만, 인스턴스의 주소가 매번 변경되므로 이를 원치 않는다면 탄력적 IP 등록이 필요하다.
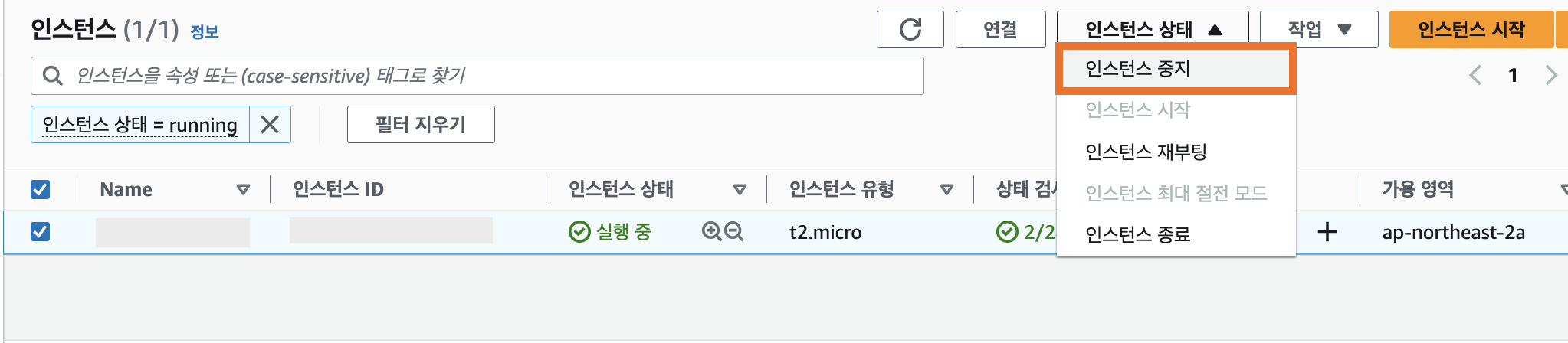
- 중지할 인스턴스를 체크한다.
- 인스턴스 중지를 클릭한다.
중지를 누르면 인스턴스 상태가 [실행 중] 에서 [중지 중] 으로 바뀐다.
[중지 중]일때는 시작이 안된다.
중지하는데 한 30초 ~ 1분 정도가 소요되었고, 그 이후 [중지됨] 으로 바뀐다.
그 후에 같은 방법으로 인스턴스 상태에서 인스턴스를 다시 시작하면 된다.
시작되는 데에는 또 30초 ~ 1분이 걸린다.
인스턴스 재시작 후, 다시 ssh 연결을 시도해보니 정상적으로 인스턴스에 연결되었다.
이를 Postman 으로 확인해보았다.
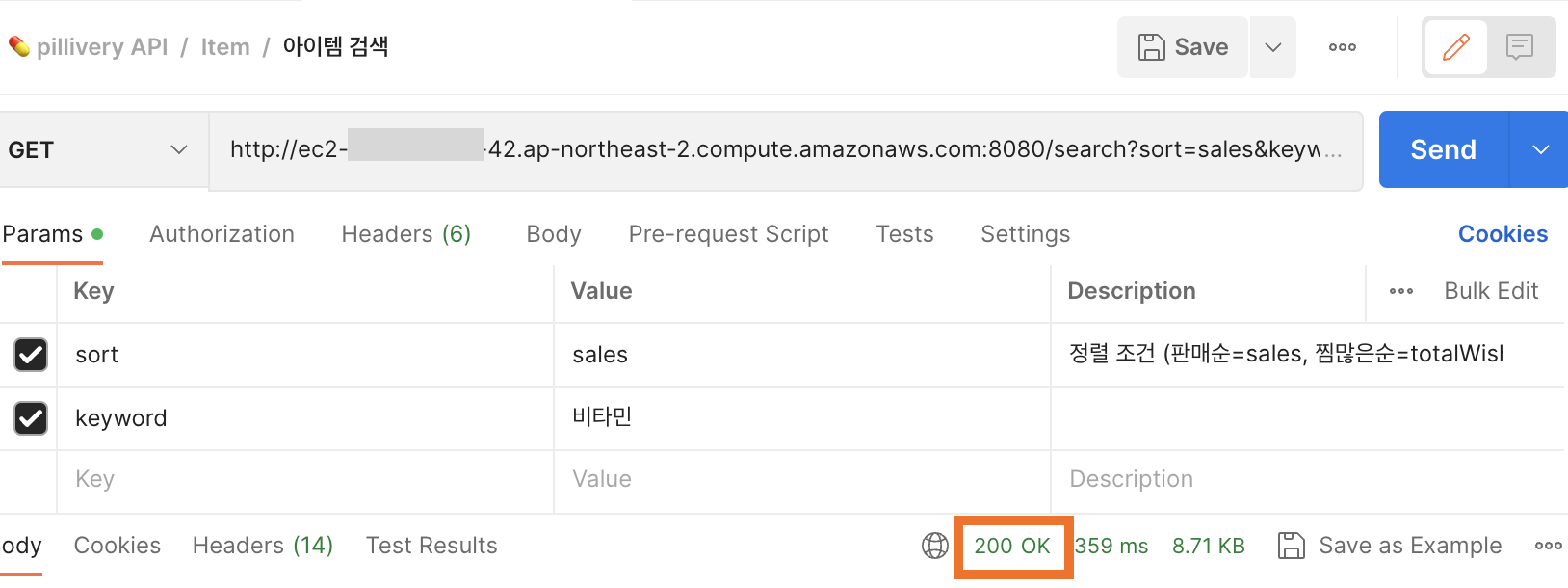
HTTP status code 200. 응답도 정상이다.
Additional
A1. 인스턴스 사라짐
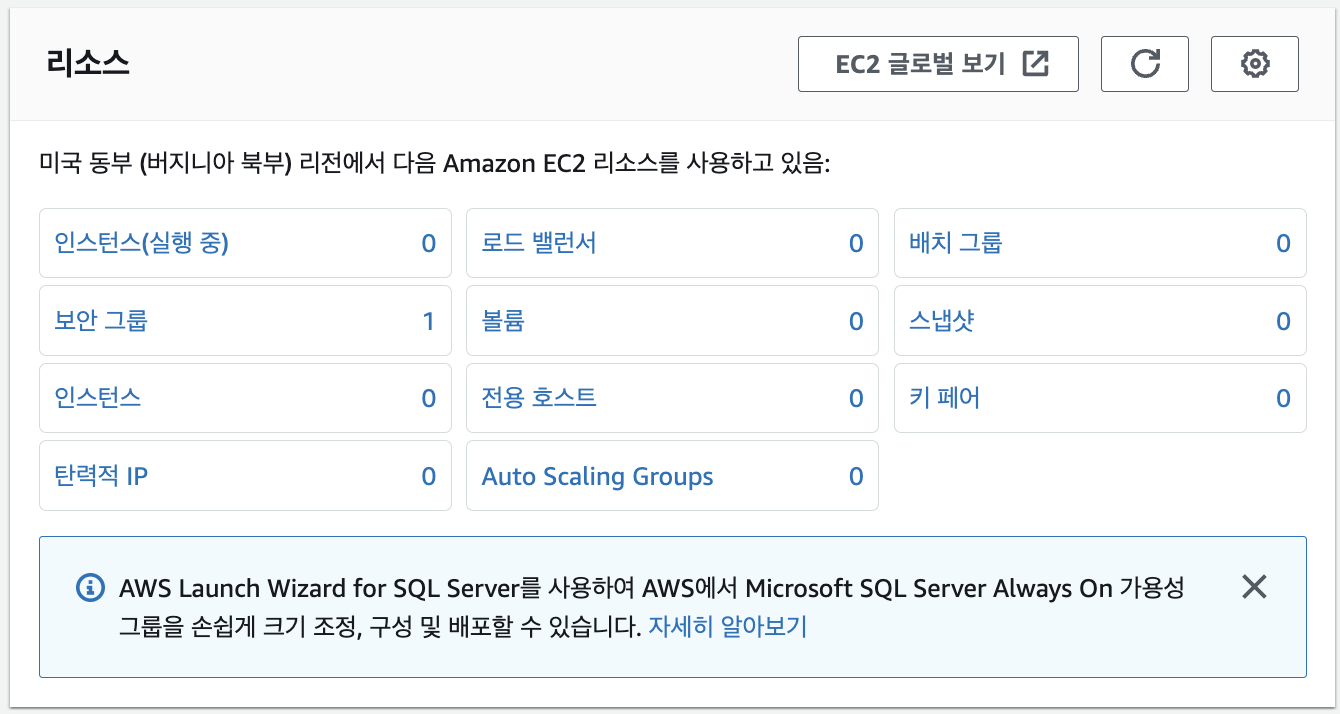
갑자기 인스턴스가 사라졌다면, 당황하지 말고 설정된 리전을 확인해보면 된다.
이 글을 읽고 있는 대부분의 사람의 경우 서울 리전에서 인스턴스를 운영 중일 것이기 때문에,
아시아 태평양 (서울) ap-northeast-2 를 선택하면 된다.
사라진 줄 알았던 인스턴스가 멀쩡히 잘 있는 것을 볼 수 있다.
A2. 탄력적 IP
기존 인스턴스는 탄력적 IP 를 사용하고 있지 않았기 때문에, 인스턴스를 중지 후 재시작 할 때마다 새로운 주소가 부여되고 있었다.
이런 이슈가 또 발생할지도 모를 뿐더러, 그럴 때마다 주소가 바뀌면 여러모로 번거롭기 때문에 이번 기회에 고정 주소를 발급받았다.

EC2 > 네트워크 및 보안 > 탄력적 IP 에서 탄력적 IP를 할당하고, 인스턴스에 연결하면 된다.
이때, 주의할 점은 다음과 같다.
1. 탄력적 IP는 프리티어로 무료 사용이 가능하지만, 탄력적 IP를 할당받은 후 인스턴스에 연결하지 않은 상태로 두면 과금의 위험이 있다.
2. 따라서, 인스턴스를 사용하지 않을 거라면 탄력적 IP도 잊지 말고 삭제해야 한다.

🔗 AWS Elastic IP guide 에서 더 자세한 정보를 확인할 수 있다.
A3. EC2 인스턴스 백그라운드 실행
nohup java -jar 파일명.jar &
ssh로 인스턴스에 연결 후, 해당 명령어를 통해 jar 파일을 실행하면 터미널을 종료해도 백그라운드에서 정상적으로 실행된다.
