1. 기본 데이터 구조
1-1. 리스트(list)
- 리스트의 시작 = head
- 리스트의 다른쪽 끝 = tail
- 리스트의 항목들에 접근하는 방식을 제한함으로써 스택과 큐라는 특별한 유형의 리스트 두가지를 얻을 수 있다.
1-2. 스택(stack)
스택은 head 에서만 항목들을 제거하거나 삽입할 수 있는 리스트이다. 스택의 헤드는 top, 테일은 bottom, 스택의 top에 데이터를 추가하는 일은 push, 제거하는 일은 pop한다고 표현한다. 스택에서 제거되는 항목은 항상 마지막에 스택에 추가된 항목으로 이러한 특성으로 인해 스택은 흔히 LIFO(Last-in, First-Out)이라고 불린다.
이러한 LIFO 특성은 데이터를 넣은 순서와 반대로 꺼내어야 할 항목들을 저장할 때 스택이 이상적이라는 것을 의미하며, 따라서 스택은 종종 백트래킹 활동의 기초구조로 사용된다.
1-3. 큐(queue)
head에서는 제거만, tail에서는 추가만 이루어지는 리스트!
FIFO(First-in, First-Out) 구조로 큐의 항목들은 저장되는 순서대로 제거된다.
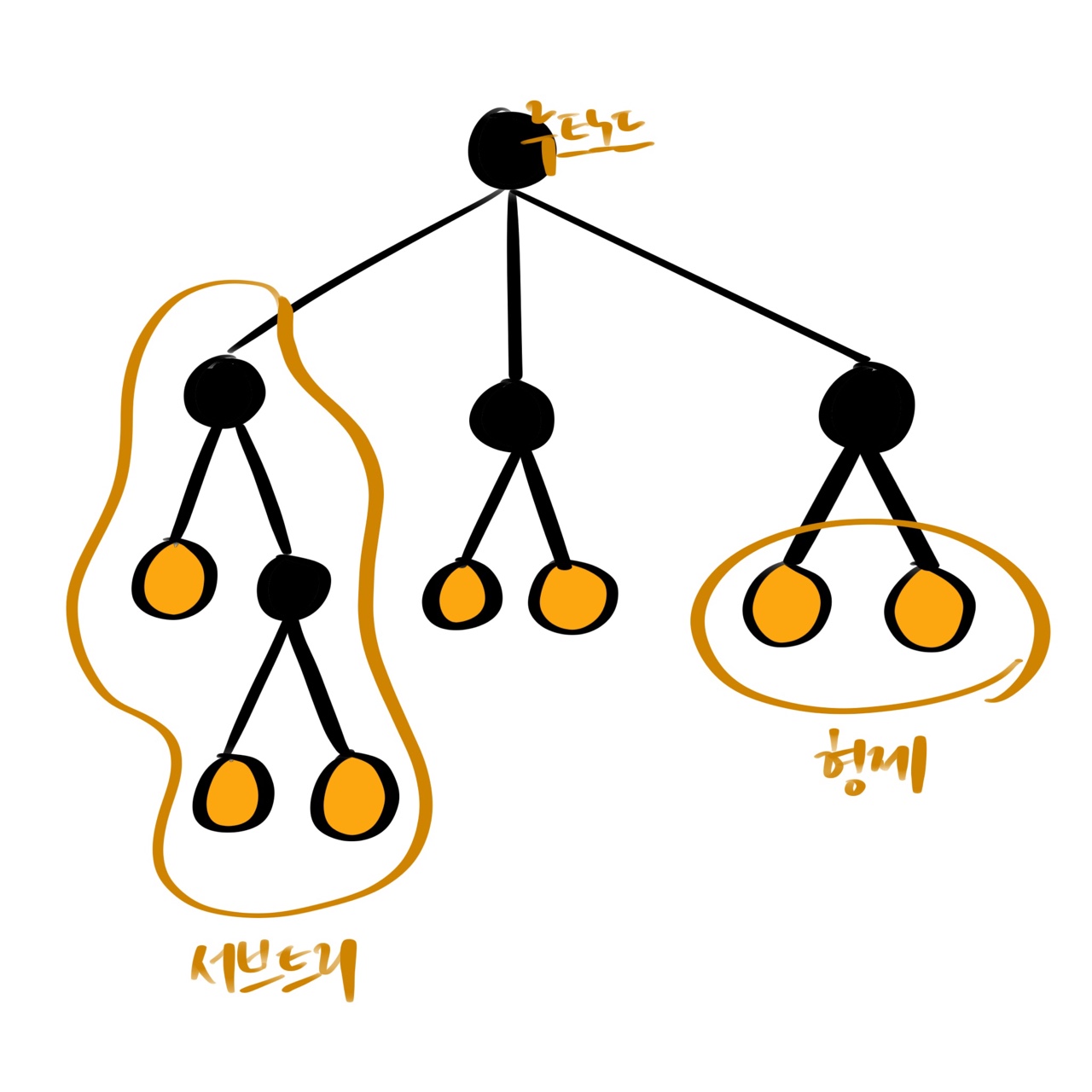
1-4. 트리(tree)

- 트리상의 각 위치는 노드(node), 최상단의 노드는 루트 노드(root node), 루트의 반대쪽 끝에 있는 노드를 단말 노드(terminal node, leaf node)라고 한다. 루트 노드에서 단말 노드에 이르는 최장 경로의 노드 개수를 이 트리의 depth 라고 부른다.
- 어떤 노드의 바로 아래 노드를 자식(child) 노드, 바로 위 노드를 부모(parent) 노드, 동일한 부모를 갖는 노드를 형제(sibling), 각 부모 노드가 둘 이하의 자식을 갖는 트리는 2진트리(binary tree)라고 한다.
2. 추상화, 정적 구조와 동적 구조, 포인터
2-1. 추상화
- 앞에서 제시된 구조들(배열, 리스트, 스택, 큐, 트리)은 사용자가 실제 저장장치의 세부사항들을 신경쓰지 않고 보다 편리한 형식으로 정보를 이용할 수 있게 해주는 추상적 도구이다. 왜냐하면 컴퓨터의 주기억장치는 실제로 이러한 구조들로 구정되어 있는 것이 아니라 주소를 지정할 수 있는 메모리의 셀로 구성되어 있기 때문이다. 그리고 이 구조들이 모의구현되어야 한다.
2-2. 정적 구조와 동적 구조
- 추상적 데이터 구조를 구축할 때, 모의구현하는 구조가 정적인가 동적인가 하는 문제는 아주 중요하다. 이는 구조의 형태가 크기가 시간에 따라 변화하는가의 여부를 말한다.
2-3. 포인터
- 컴퓨터의 주기억장치의 셀들은 숫자로 된 주소로 식별될 수 있고, 이 주소들은 숫자이므로 주소 자체를 인코딩하여 메모리 셀에 저장할 수 있다. 포인터란 이 인코딩된 주소를 값으로 갖는 메모리 영역이다.
3. 데이터베이스의 기초
3-1. 스키마
- 데이터베이스 소프트웨어가 데이터베이스를 유지하기 위해 사용하는 전체 데이터베이스 구조에 대해 기술한 것
3-2. 데이터베이스 관리 시스템 DBMS
- 데이터베이스에 대한 실제 조작이 이루어지는 곳
ex1. 관계형 데이터베이스 모델
1. 구조
- 관계(relation) : 데이터를 사각형 테이블에 저장되어 있는 것으로 기술하며, 이러한 테이블들을 지칭한다.
- 튜플(tuple) : 관계 안의 한 행
- 속성(attribute) : 관계 안의 열 // 열 안의 각 항목이 해당 튜플의 어떤 속성을 기술하기 때문이다.
2. 관계 연산
select : 특정 특성을 갖는 튜플을 선택(관계에서 행을 추출)
project : 열들을 추출
join : 여러 관계를 조합하여 한 관계를 만듦.
3. SQL(structured Query Languge)
관계형 데이터베이스 관리 시스템은 select, project, join 등의 연산 수행 루틴을 직접적으로 제공하기보다, 기본 단계를 조합한 기능을 수행하는 루틴을 제공하기도 하는데 이의 한 예가 SQL 이다.
SQL은 질의 수행(select 절 등) 외에도 관계의 구조 정의, 생성, 내용 수정 등을 위한 문장들을 포함한다.(ex. insert into, delete from, update)
4. 데이터베이스 무결성 유지
4-1. 커밋/롤백 프로토콜
트랜잭션 과부하가 걸리는 대규모 데이터 베이스의 경우, 트랜잭션 실행을 위한 요청이나, 장비 오동작이 발생할 가능성이 높다.
이를 방지하기 위해 비휘발성 저장장치에 각 트랜잭션 활동에 대한 기록을 포함하는 로그(log)를 유지하는 방법을 쓴다.
커밋 시점(commit point)
- 트랜잭션 안의 모든 단계들이 로그에 기록되는 시점
롤백(roll back)
- 트랜잭션이 커밋 시점에 이르기 전에 문제가 발생할 경우, DBMS는 완료될 수 없는 부분 실행 트랜잭션을 갖게 될 것이고, 이 경우 로그는 트랜잭션에 의해 실제 수행된 활동을 되돌리는데(roll back) 사용될 수 있다.
- 롤백은 장비 오동작으로 인한 복구과정에만 사용되는 것이 아니라 종종 정상적인 작업의 일부분으로 사용되기도 한다.
4-2. 로킹
- intro) 데이터베이스에서 어떤 트랜잭션이 진행되는 동안 다른 트랜잭션의 실행을 시작하는 데 따른 문제로 합산 오류 문제와 갱신 유실 문제를 들 수 있다.
이러한 현상을 해결하기 위해 사용되는 방법으로, 어떤 트랜잭션에서 현재 사용하는 데이터베이스 안의 항목들을 표시하는 로킹 프로토콜(loking protocol)을 사용한다. 이러한 표시들을 로크(lock)라고 하며, 표시된 항목을 로크 걸린 항목이라 한다.
로킹 (loking) : 한 트랜잭션이 사용 중인 데이터에 다른 트랜잭션의 접근을 막는 것.
공유 로크 (shared lock) : 데이터를 읽을 때 사용.
배타적 로크 (exculsive lock) : 데이터를 변경할 때 사용.
5. 데이터 마이닝
- intro) 데이터마이닝은 저장된 사실을 검색하는 데이터베이스와 달리 사전에 알려져 있지 않은 패턴을 식별하는 것으로 목적으로 한다. 데이터 마이닝은 잦은 갱신이 이루어지는 온라인 운영데이터 베이스가 아니라 데이터 웨어하우스(data warehouse)라고 불리는 정적인 데이터 집합에 대해 수행된다.
5-1. 여러가지 데이터마이닝 기법
- 클래스 서술 (class description) : 어떤 데이터 항목 그룹을 특정짓는 성질을 식별한다.
- 클래스 차별화 (class discrimination) : 두 개의 그룹을 나누는 성질을 식별한다.
- 클러스터 분석 (cluster analysis) : 클래스 자체의 발견을 목적으로 한다.
- 연계성 분석 (association analysis) : 데이터 그룹 사이의 연결 링크를 찾는 것을 목적으로 한다.
- 이상치 분석 (outliter analysis) : 일반 기준을 벗어난 데이터 항목들의 식별을 목적으로 한다.
- 순차 패턴 분석 (sequential pattern analysis) : 시간의 경과에 따른 행위 패턴의 식별을 목적으로 한다.
- 데이터 큐브 (data cube) : 데이터 마이닝이 가능하도록 만드는 여러 관점에서 바라보는 데이터.
